CRAFT Your Dataset: Task-Specific Synthetic Dataset Generation Through Corpus Retrieval and Augmentation

0

Sign in to get full access
Overview
- The paper proposes a method called CRAFT (Corpus Retrieval and Augmentation for Task-specific synthetic data generation) to generate task-specific synthetic datasets.
- CRAFT retrieves relevant text from a large corpus and augments it to create diverse, high-quality training data for machine learning models.
- The authors demonstrate CRAFT's effectiveness on several natural language processing tasks, including question answering, dialogue, and text classification.
Plain English Explanation
In machine learning, having a large, high-quality dataset is crucial for training effective models. However, creating such datasets can be time-consuming and expensive. CRAFT: Task-Specific Synthetic Dataset Generation offers a solution to this problem by automatically generating synthetic data that is tailored to specific tasks.
The key idea behind CRAFT is to leverage a large corpus of existing text data and selectively retrieve and augment relevant portions to create a new dataset. This involves two main steps:
-
Corpus Retrieval: CRAFT searches through a large corpus of text data (such as books, articles, or web pages) to find passages that are most relevant to the target task. This ensures that the synthetic data is grounded in real-world language and content.
-
Data Augmentation: Once the relevant passages are identified, CRAFT applies various data augmentation techniques, such as paraphrasing, entity substitution, and style transfer, to create a diverse set of synthetic examples. This helps the model learn to generalize beyond the original data.
By combining corpus retrieval and data augmentation, CRAFT can generate large, diverse, and high-quality synthetic datasets for a wide range of natural language processing tasks, including question answering, dialogue, and text classification. This can significantly reduce the time and effort required to build effective machine learning models, especially for domains where labeled data is scarce.
Technical Explanation
The CRAFT: Task-Specific Synthetic Dataset Generation paper presents a novel approach to generating synthetic datasets for natural language processing tasks. The key components of their method are:
-
Corpus Retrieval: The authors use a pre-trained language model (e.g., BERT) to encode the target task description and retrieve the most relevant passages from a large corpus of text data. This ensures that the synthetic data is grounded in real-world language and content.
-
Data Augmentation: The retrieved passages are then augmented using various techniques, such as paraphrasing, entity substitution, and style transfer. This creates a diverse set of synthetic examples that capture different linguistic variations and maintain the semantic coherence of the original data.
-
Synthetic Dataset Generation: The augmented passages are combined to form a synthetic dataset that can be used to train machine learning models for the target task. The authors show that this approach outperforms traditional data augmentation methods and can significantly improve model performance, especially in low-resource settings.
The authors evaluate CRAFT on several natural language processing tasks, including question answering, dialogue, and text classification. They demonstrate that the synthetic datasets generated by CRAFT can improve model performance by a significant margin compared to using only the original training data or applying generic data augmentation techniques.
Critical Analysis
The CRAFT: Task-Specific Synthetic Dataset Generation paper presents a promising approach to address the challenge of dataset scarcity in natural language processing. By leveraging a large corpus of text data and applying targeted data augmentation, the authors are able to generate high-quality synthetic datasets that can significantly improve model performance.
One potential limitation of the CRAFT approach is that it relies on the quality and relevance of the initial corpus. If the corpus does not contain sufficient relevant content for the target task, the synthetic data generated by CRAFT may not be as effective. The authors acknowledge this and suggest further research into techniques for corpus curation and expansion.
Additionally, the paper could have provided more detailed discussions on the potential biases or artifacts that may be introduced by the data augmentation techniques used in CRAFT. It is important to ensure that the synthetic data does not perpetuate harmful biases or lead to unintended consequences when deployed in real-world applications.
Overall, the CRAFT: Task-Specific Synthetic Dataset Generation paper presents an innovative and practical approach to dataset generation that could have significant implications for the field of natural language processing. As the authors suggest, further research into improving the robustness and scalability of CRAFT could lead to even more powerful and versatile synthetic data generation methods.
Conclusion
The CRAFT: Task-Specific Synthetic Dataset Generation paper introduces a novel approach to generating synthetic datasets for natural language processing tasks. By combining corpus retrieval and data augmentation, CRAFT can create large, diverse, and high-quality synthetic datasets that can significantly improve model performance, especially in low-resource settings.
The key innovation of CRAFT is its ability to leverage a large corpus of existing text data and selectively retrieve and augment relevant passages to create task-specific synthetic data. This approach allows for the generation of synthetic data that is grounded in real-world language and content, while also capturing diverse linguistic variations through data augmentation.
The authors demonstrate the effectiveness of CRAFT on several natural language processing tasks, including question answering, dialogue, and text classification. Their results show that the synthetic datasets generated by CRAFT can significantly improve model performance compared to using only the original training data or applying generic data augmentation techniques.
Overall, the CRAFT: Task-Specific Synthetic Dataset Generation paper presents an important contribution to the field of natural language processing, as it offers a practical and scalable solution to the challenge of dataset scarcity. As the authors suggest, further research into improving the robustness and versatility of CRAFT could lead to even more powerful and impactful synthetic data generation methods in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CRAFT Your Dataset: Task-Specific Synthetic Dataset Generation Through Corpus Retrieval and Augmentation
Ingo Ziegler, Abdullatif Koksal, Desmond Elliott, Hinrich Schutze
Building high-quality datasets for specialized tasks is a time-consuming and resource-intensive process that often requires specialized domain knowledge. We propose Corpus Retrieval and Augmentation for Fine-Tuning (CRAFT), a method for generating synthetic datasets, given a small number of user-written few-shots that demonstrate the task to be performed. Given the few-shot examples, we use large-scale public web-crawled corpora and similarity-based document retrieval to find other relevant human-written documents. Lastly, instruction-tuned large language models (LLMs) augment the retrieved documents into custom-formatted task samples, which then can be used for fine-tuning. We demonstrate that CRAFT can efficiently generate large-scale task-specific training datasets for four diverse tasks: biology question-answering (QA), medicine QA and commonsense QA as well as summarization. Our experiments show that CRAFT-based models outperform or achieve comparable performance to general LLMs for QA tasks, while CRAFT-based summarization models outperform models trained on human-curated data by 46 preference points.
Read more9/4/2024
0
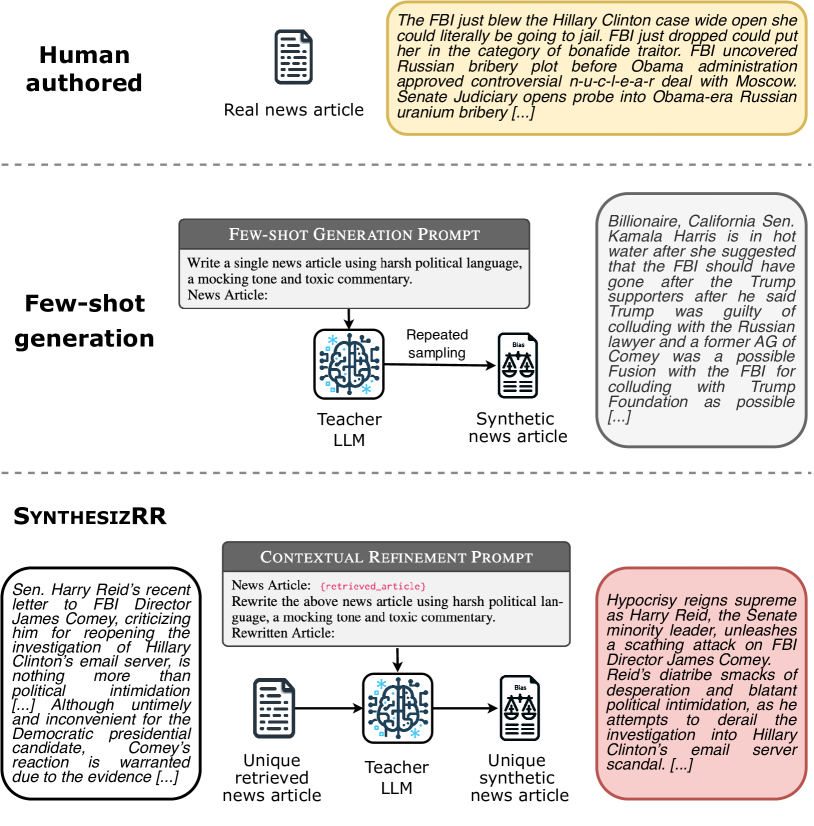
SynthesizRR: Generating Diverse Datasets with Retrieval Augmentation
Abhishek Divekar, Greg Durrett
It is often desirable to distill the capabilities of large language models (LLMs) into smaller student models due to compute and memory constraints. One way to do this for classification tasks is via dataset synthesis, which can be accomplished by generating examples of each label from the LLM. Prior approaches to synthesis use few-shot prompting, which relies on the LLM's parametric knowledge to generate usable examples. However, this leads to issues of repetition, bias towards popular entities, and stylistic differences from human text. In this work, we propose Synthesize by Retrieval and Refinement (SynthesizRR), which uses retrieval augmentation to introduce variety into the dataset synthesis process: as retrieved passages vary, the LLM is seeded with different content to generate its examples. We empirically study the synthesis of six datasets, covering topic classification, sentiment analysis, tone detection, and humor, requiring complex synthesis strategies. We find that SynthesizRR greatly improves lexical and semantic diversity, similarity to human-written text, and distillation performance, when compared to 32-shot prompting and four prior approaches. We release our extensive codebase at https://github.com/amazon-science/synthesizrr
Read more7/9/2024
🛸
0
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
Read more5/30/2024

2
RAFT: Adapting Language Model to Domain Specific RAG
Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a open-book in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
Read more6/6/2024