RAFT: Adapting Language Model to Domain Specific RAG
2403.10131
3
0

Abstract
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a open-book in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
Create account to get full access
Overview
- This paper introduces RAFT, a novel approach to adapting large language models (LLMs) for domain-specific retrieval-augmented generation (RAG) tasks.
- The researchers explore the use of LLMs in open-book exam settings, where models have access to an external knowledge base to help answer questions.
- The paper proposes techniques to fine-tune and adapt LLMs for domain-specific RAG, with the goal of improving performance on tasks like question answering.
Plain English Explanation
The researchers in this paper are looking at how large language models can be used for "open-book exams" - situations where an AI model has access to an external knowledge base to help answer questions.
The key idea is to take a powerful language model and adapt or "fine-tune" it for a specific domain, like medical or legal knowledge. This allows the model to better understand and reason with the relevant information in its knowledge base, leading to improved performance on tasks like question answering.
The researchers call their approach "RAFT" (Retrieval-Augmented Fine-Tuning), and they show how it can boost the model's ability to find and use the most relevant information to answer questions. This is kind of like a student studying a specific subject before taking an exam - they'll do much better than if they just showed up cold.
Overall, this work is an important step in making large language models more useful for real-world applications that require in-depth knowledge of a particular domain.
Technical Explanation
The paper introduces the RAFT framework, which aims to adapt large language models (LLMs) for domain-specific retrieval-augmented generation (RAG) tasks.
The key components of RAFT include:
- Domain-Specific Fine-Tuning: The researchers fine-tune the LLM on a domain-specific corpus to imbue it with relevant knowledge and language patterns.
- Retrieval-Augmented Fine-Tuning: The model is further fine-tuned on a RAG task, where it learns to effectively retrieve and leverage information from an external knowledge base to generate responses.
- Retrieval-Augmented Generation: During inference, the fine-tuned model uses its retrieval and generation capabilities to answer questions by dynamically accessing relevant information from the knowledge base.
The researchers evaluate RAFT on open-book exam settings, where models have access to an external knowledge source. They compare RAFT to standard fine-tuning approaches and collaborative retrieval-augmented generation methods, demonstrating significant performance improvements on several question answering benchmarks.
Critical Analysis
The paper provides a thorough and well-designed study of adapting LLMs for domain-specific RAG tasks. The RAFT framework appears to be a promising approach, with the authors demonstrating its effectiveness on several evaluation tasks.
However, the paper does acknowledge some limitations and areas for future work:
- Generalization to Other Domains: The experiments focus on specific domains (e.g., medical, legal), and it's unclear how well RAFT would generalize to other knowledge areas.
- Interpretability and Explainability: The paper does not delve into the interpretability of the RAFT model's decision-making process or its ability to explain its reasoning.
- Computational Efficiency: The fine-tuning and inference steps in RAFT may be computationally intensive, which could limit its practical deployment in certain scenarios.
Additionally, future research could explore:
- Ranking feedback and query rewriting techniques to further enhance the retrieval and generation capabilities of RAFT.
- Incorporating more advanced knowledge representation and reasoning mechanisms into the model.
- Investigating the model's robustness and performance under various real-world conditions and constraints.
Conclusion
This paper presents a valuable contribution to the field of retrieval-augmented generation by introducing the RAFT framework. The proposed techniques for adapting LLMs to domain-specific RAG tasks have shown promising results, particularly in open-book exam settings.
The work highlights the potential of leveraging large language models in combination with external knowledge sources to tackle complex, knowledge-intensive tasks. As AI systems become more prevalent in various domains, approaches like RAFT can play a crucial role in enhancing their capabilities and ensuring they can effectively utilize relevant information to provide accurate and informed responses.
Future research building on this work could lead to even more powerful and versatile AI assistants that can seamlessly integrate language understanding, knowledge retrieval, and contextual reasoning to tackle a wide range of real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
Shuting Wang, Jiongnan Liu, Shiren Song, Jiehan Cheng, Yuqi Fu, Peidong Guo, Kun Fang, Yutao Zhu, Zhicheng Dou
0
0
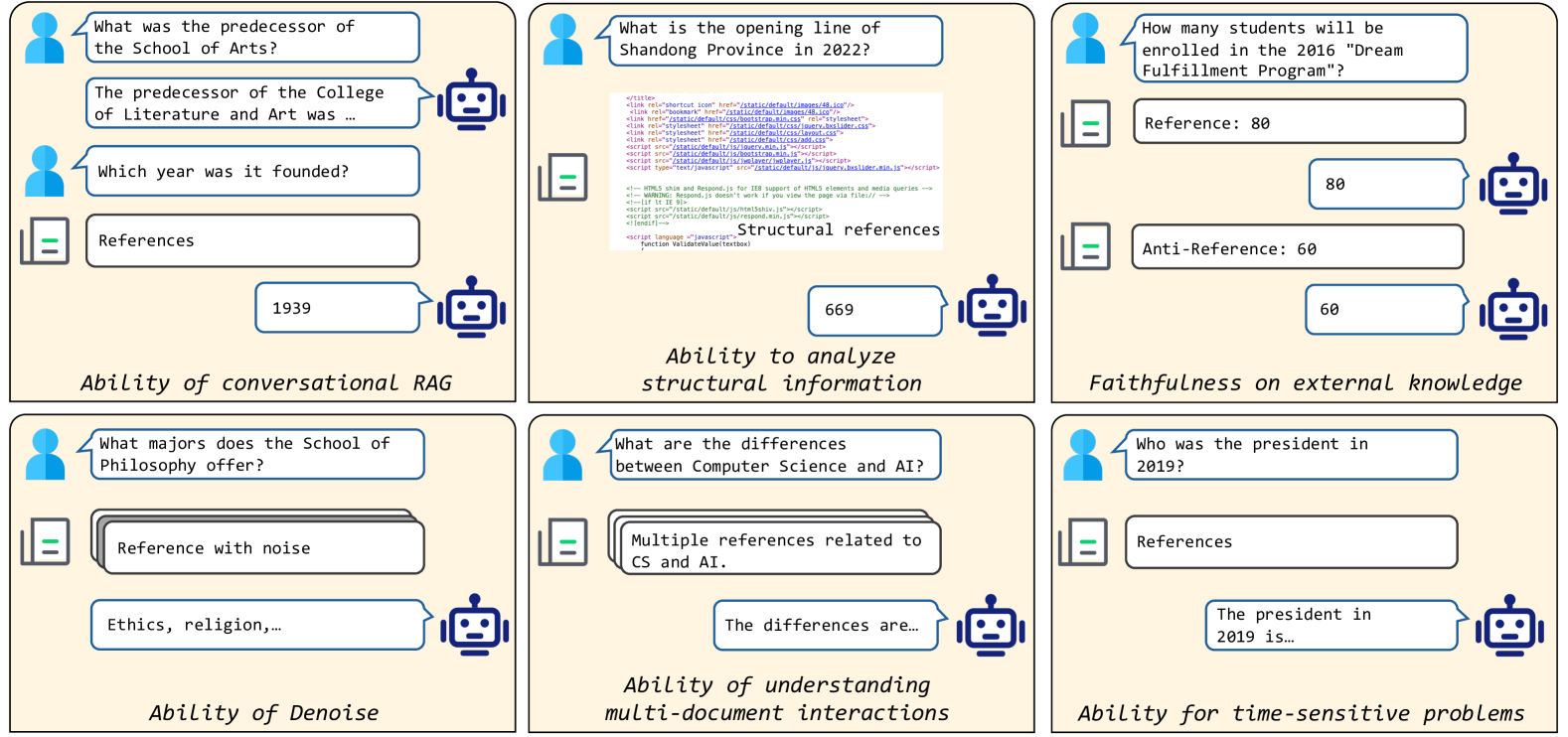
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.
6/18/2024
Improving Retrieval for RAG based Question Answering Models on Financial Documents
Spurthi Setty, Katherine Jijo, Eden Chung, Natan Vidra
0
0
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
4/12/2024
🛸
DuetRAG: Collaborative Retrieval-Augmented Generation
Dian Jiao, Li Cai, Jingsheng Huang, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
0
0
Retrieval-Augmented Generation (RAG) methods augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, contemporary RAG approaches suffer from irrelevant knowledge retrieval issues in complex domain questions (e.g., HotPot QA) due to the lack of corresponding domain knowledge, leading to low-quality generations. To address this issue, we propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. Our bootstrapping philosophy is to simultaneously integrate the domain fintuning and RAG models to improve the knowledge retrieval quality, thereby enhancing generation quality. Finally, we demonstrate DuetRAG' s matches with expert human researchers on HotPot QA.
5/24/2024
↗️
T-RAG: Lessons from the LLM Trenches
Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla
0
0
Large Language Models (LLM) have shown remarkable language capabilities fueling attempts to integrate them into applications across a wide range of domains. An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, limited computational resources and the need for a robust application that correctly responds to queries. Retrieval-Augmented Generation (RAG) has emerged as the most prominent framework for building LLM-based applications. While building a RAG is relatively straightforward, making it robust and a reliable application requires extensive customization and relatively deep knowledge of the application domain. We share our experiences building and deploying an LLM application for question answering over private organizational documents. Our application combines the use of RAG with a finetuned open-source LLM. Additionally, our system, which we call Tree-RAG (T-RAG), uses a tree structure to represent entity hierarchies within the organization. This is used to generate a textual description to augment the context when responding to user queries pertaining to entities within the organization's hierarchy. Our evaluations, including a Needle in a Haystack test, show that this combination performs better than a simple RAG or finetuning implementation. Finally, we share some lessons learned based on our experiences building an LLM application for real-world use.
6/7/2024