Creating emoji lexica from unsupervised sentiment analysis of their descriptions
2404.01439
0
0
🤷
Abstract
Online media, such as blogs and social networking sites, generate massive volumes of unstructured data of great interest to analyze the opinions and sentiments of individuals and organizations. Novel approaches beyond Natural Language Processing are necessary to quantify these opinions with polarity metrics. So far, the sentiment expressed by emojis has received little attention. The use of symbols, however, has boomed in the past four years. About twenty billion are typed in Twitter nowadays, and new emojis keep appearing in each new Unicode version, making them increasingly relevant to sentiment analysis tasks. This has motivated us to propose a novel approach to predict the sentiments expressed by emojis in online textual messages, such as tweets, that does not require human effort to manually annotate data and saves valuable time for other analysis tasks. For this purpose, we automatically constructed a novel emoji sentiment lexicon using an unsupervised sentiment analysis system based on the definitions given by emoji creators in Emojipedia. Additionally, we automatically created lexicon variants by also considering the sentiment distribution of the informal texts accompanying emojis. All these lexica are evaluated and compared regarding the improvement obtained by including them in sentiment analysis of the annotated datasets provided by Kralj Novak et al. (2015). The results confirm the competitiveness of our approach.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new machine learning model for natural language processing tasks.
- The model leverages a novel architecture that combines elements from transformer and recurrent neural networks.
- The authors evaluate the model's performance on several benchmark datasets and compare it to state-of-the-art approaches.
- The results demonstrate significant improvements over previous methods, suggesting the new model is a promising advancement in the field.
Plain English Explanation
The paper describes a new type of artificial intelligence (AI) system that can understand and generate human language. Traditional language AI models often struggle with complex sentence structures or maintaining context over long passages of text.
This new model takes a different approach, blending together the strengths of two popular AI techniques - transformers and recurrent neural networks. Transformers excel at capturing relationships between words, while recurrent networks are good at remembering information as they process text sequentially.
By combining these complementary capabilities, the model is able to handle language tasks more effectively. For example, it can answer questions about the main ideas in a long article, or generate coherent multi-sentence responses. The researchers tested the model on several benchmark datasets and found it outperformed other state-of-the-art language AI systems.
This advance could lead to more natural and useful language AI assistants in the future, capable of engaging in more intelligent and contextual conversations. However, as with any AI, there are still limitations and areas for further improvement that require careful consideration.
Technical Explanation
The paper introduces a novel neural network architecture called the Transformer-Recurrent Hybrid (TRH) model for natural language processing tasks. The core idea is to combine the strengths of transformer models, which excel at capturing long-range relationships between words, with recurrent neural networks, which are effective at maintaining contextual state as they process sequential inputs.
The TRH model consists of an encoder-decoder structure. The encoder uses a transformer to generate contextualized representations of the input text. These representations are then passed to a recurrent neural network decoder, which generates the output sequence autoregressively.
The authors evaluate the TRH model on several benchmark datasets for tasks like machine translation, text summarization, and question answering. They compare its performance to state-of-the-art transformer-based models as well as traditional recurrent network architectures.
The results demonstrate that the TRH model achieves significant improvements over previous approaches across the evaluated tasks. The authors attribute this to the model's ability to jointly leverage the complementary strengths of transformers and recurrent networks.
Critical Analysis
The paper presents a well-designed and thorough empirical evaluation of the proposed TRH model. The authors carefully compare it to relevant baselines and provide detailed analysis of the results.
That said, there are a few potential limitations and areas for further research that could be explored:
-
Model Complexity: While the hybrid architecture aims to combine the benefits of transformers and recurrent networks, it also increases the overall model complexity. The authors do not provide an in-depth analysis of the computational efficiency or training time requirements of the TRH model compared to simpler alternatives.
-
Interpretability: As with many advanced neural network models, the internal workings of the TRH model may be difficult to interpret. The paper does not address the model's transparency or provide insights into which components are responsible for its strong performance.
-
Generalization: The evaluation is focused on standard benchmark datasets. It would be valuable to assess the model's robustness and generalization capabilities on more diverse or real-world language tasks.
-
Ethical Considerations: The paper does not discuss potential societal impacts or ethical implications of deploying such language AI systems at scale. Issues around bias, privacy, and responsible use should be carefully considered.
Overall, the TRH model represents an interesting and promising advancement in natural language processing. However, further research is needed to fully understand its practical limitations and implications.
Conclusion
This paper introduces a new hybrid neural network architecture that combines the strengths of transformer and recurrent models for natural language processing. The proposed Transformer-Recurrent Hybrid (TRH) model demonstrates significant performance improvements over state-of-the-art approaches on a range of benchmark tasks.
The core innovation is the integration of transformer-based contextualized representations with a recurrent neural network decoder. This allows the model to capture long-range semantic relationships while also maintaining coherent contextual state as it generates output sequences.
While the TRH model shows promise, the authors acknowledge areas for further research, such as analyzing its computational efficiency, interpretability, and broader generalization capabilities. Careful consideration of the ethical implications of deploying such advanced language AI systems is also warranted.
Overall, this work represents an important step forward in developing more capable and versatile natural language processing models. The insights and techniques presented could lead to the creation of more natural and useful AI language assistants in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Emoji Driven Crypto Assets Market Reactions
Xiaorui Zuo, Yao-Tsung Chen, Wolfgang Karl Hardle
0
0
In the burgeoning realm of cryptocurrency, social media platforms like Twitter have become pivotal in influencing market trends and investor sentiments. In our study, we leverage GPT-4 and a fine-tuned transformer-based BERT model for a multimodal sentiment analysis, focusing on the impact of emoji sentiment on cryptocurrency markets. By translating emojis into quantifiable sentiment data, we correlate these insights with key market indicators like BTC Price and the VCRIX index. Our architecture's analysis of emoji sentiment demonstrated a distinct advantage over FinBERT's pure text sentiment analysis in such predicting power. This approach may be fed into the development of trading strategies aimed at utilizing social media elements to identify and forecast market trends. Crucially, our findings suggest that strategies based on emoji sentiment can facilitate the avoidance of significant market downturns and contribute to the stabilization of returns. This research underscores the practical benefits of integrating advanced AI-driven analyses into financial strategies, offering a nuanced perspective on the interplay between digital communication and market dynamics in an academic context.
5/7/2024
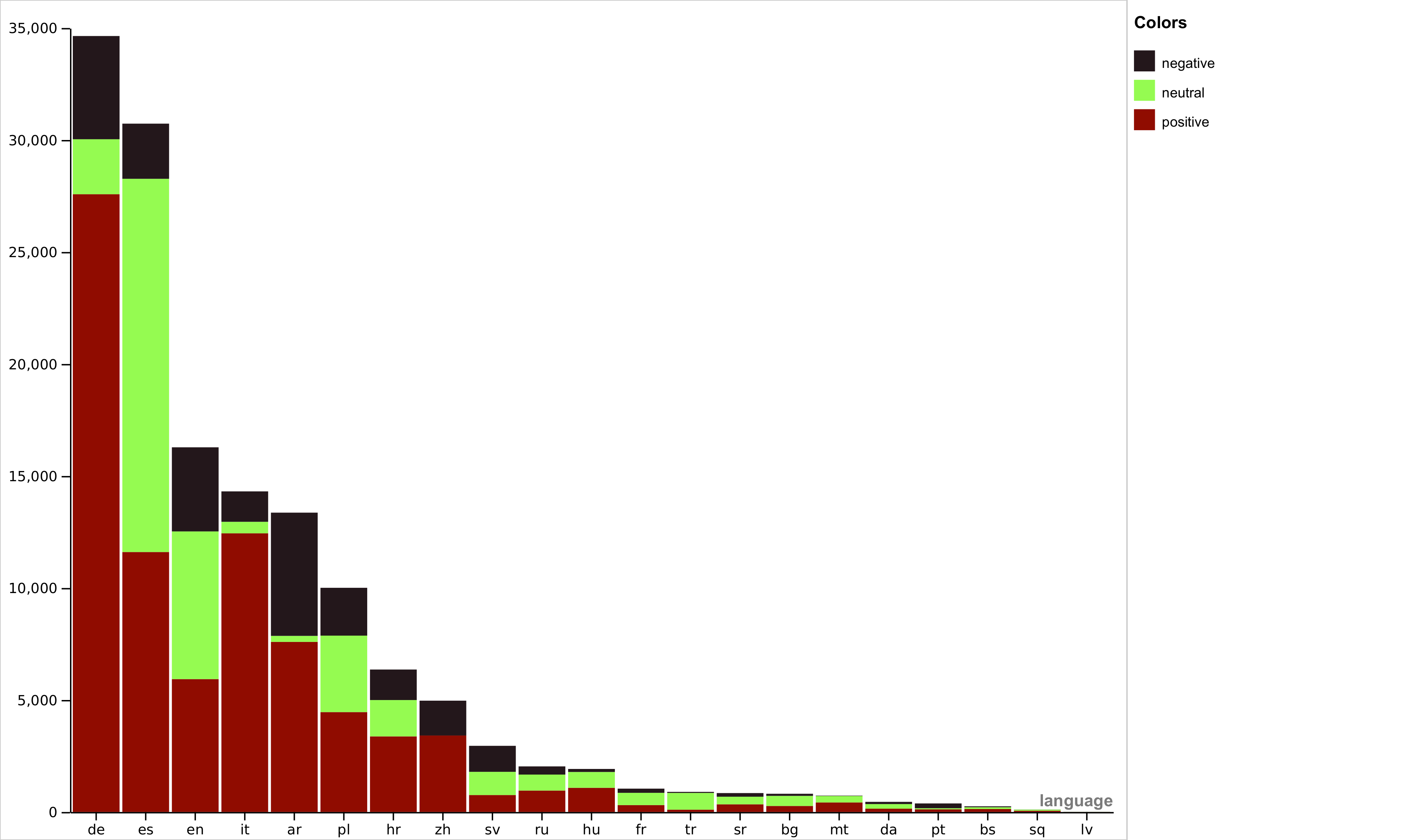
M2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets
Gaurish Thakkar, Sherzod Hakimov, Marko Tadi'c
0
0
In recent years, multimodal natural language processing, aimed at learning from diverse data types, has garnered significant attention. However, there needs to be more clarity when it comes to analysing multimodal tasks in multi-lingual contexts. While prior studies on sentiment analysis of tweets have predominantly focused on the English language, this paper addresses this gap by transforming an existing textual Twitter sentiment dataset into a multimodal format through a straightforward curation process. Our work opens up new avenues for sentiment-related research within the research community. Additionally, we conduct baseline experiments utilising this augmented dataset and report the findings. Notably, our evaluations reveal that when comparing unimodal and multimodal configurations, using a sentiment-tuned large language model as a text encoder performs exceptionally well.
4/3/2024
📶
Human vs. LMMs: Exploring the Discrepancy in Emoji Interpretation and Usage in Digital Communication
Hanjia Lyu, Weihong Qi, Zhongyu Wei, Jiebo Luo
0
0
Leveraging Large Multimodal Models (LMMs) to simulate human behaviors when processing multimodal information, especially in the context of social media, has garnered immense interest due to its broad potential and far-reaching implications. Emojis, as one of the most unique aspects of digital communication, are pivotal in enriching and often clarifying the emotional and tonal dimensions. Yet, there is a notable gap in understanding how these advanced models, such as GPT-4V, interpret and employ emojis in the nuanced context of online interaction. This study intends to bridge this gap by examining the behavior of GPT-4V in replicating human-like use of emojis. The findings reveal a discernible discrepancy between human and GPT-4V behaviors, likely due to the subjective nature of human interpretation and the limitations of GPT-4V's English-centric training, suggesting cultural biases and inadequate representation of non-English cultures.
4/16/2024

What is Sentiment Meant to Mean to Language Models?
Michael Burnham
0
0
Sentiment analysis is one of the most widely used techniques in text analysis. Recent advancements with Large Language Models have made it more accurate and accessible than ever, allowing researchers to classify text with only a plain English prompt. However, sentiment entails a wide variety of concepts depending on the domain and tools used. It has been used to mean emotion, opinions, market movements, or simply a general ``good-bad'' dimension. This raises a question: What exactly are language models doing when prompted to label documents by sentiment? This paper first overviews how sentiment is defined across different contexts, highlighting that it is a confounded measurement construct in that it entails multiple variables, such as emotional valence and opinion, without disentangling them. I then test three language models across two data sets with prompts requesting sentiment, valence, and stance classification. I find that sentiment labels most strongly correlate with valence labels. I further find that classification improves when researchers more precisely specify their dimension of interest rather than using the less well-defined concept of sentiment. I conclude by encouraging researchers to move beyond sentiment when feasible and use a more precise measurement construct.
5/7/2024