M2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets
2404.01753
0
0
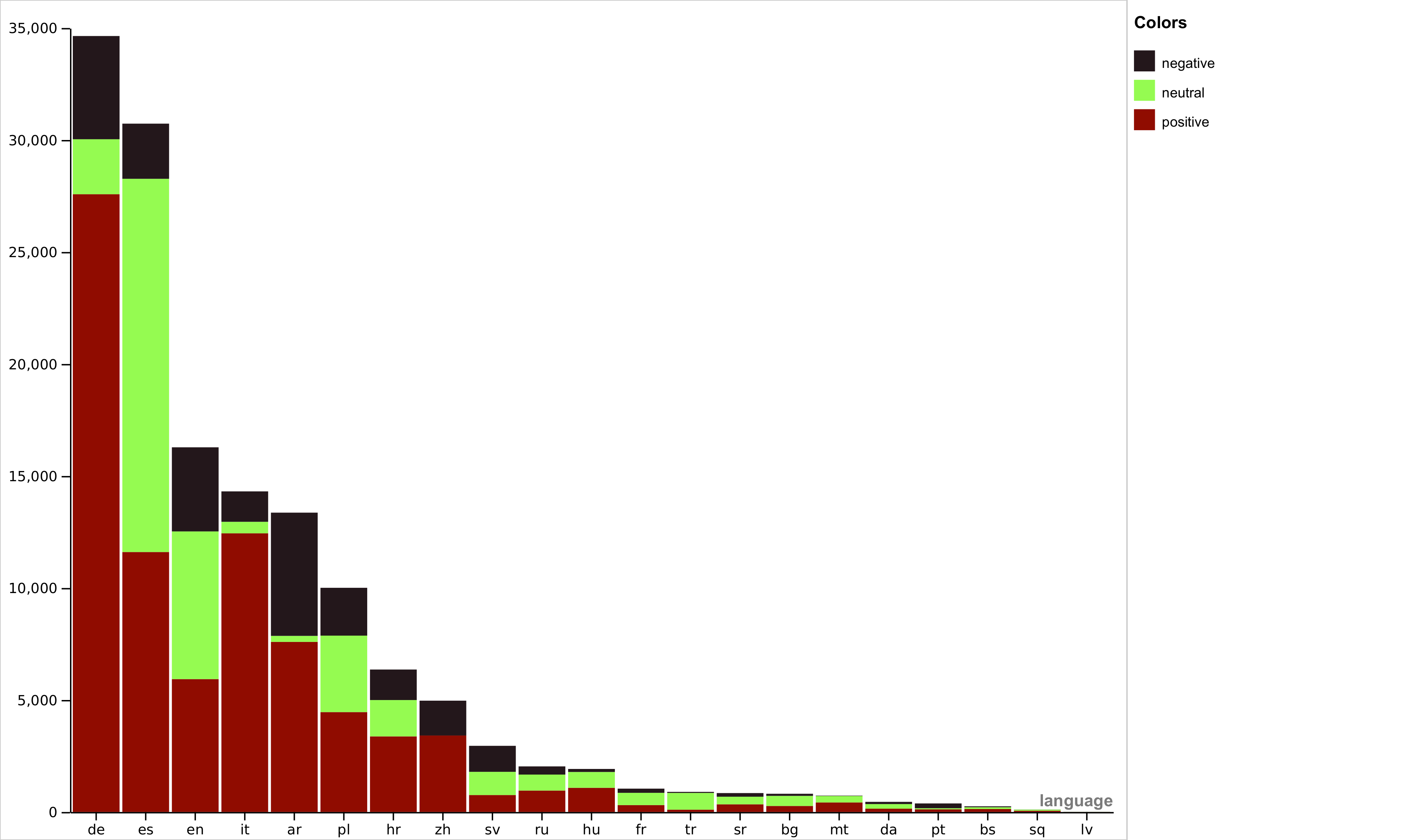
Abstract
In recent years, multimodal natural language processing, aimed at learning from diverse data types, has garnered significant attention. However, there needs to be more clarity when it comes to analysing multimodal tasks in multi-lingual contexts. While prior studies on sentiment analysis of tweets have predominantly focused on the English language, this paper addresses this gap by transforming an existing textual Twitter sentiment dataset into a multimodal format through a straightforward curation process. Our work opens up new avenues for sentiment-related research within the research community. Additionally, we conduct baseline experiments utilising this augmented dataset and report the findings. Notably, our evaluations reveal that when comparing unimodal and multimodal configurations, using a sentiment-tuned large language model as a text encoder performs exceptionally well.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a multimodal and multilingual model for sentiment analysis of tweets, called M2SA.
- The model combines text, image, and metadata features to improve sentiment classification performance across multiple languages.
- Experiments on several benchmark datasets show the model outperforms state-of-the-art approaches for sentiment analysis of tweets.
Plain English Explanation
The researchers have developed a new machine learning model called M2SA that can analyze the emotional sentiment expressed in tweets. Tweets often contain a mix of text, images, and other metadata like user information. The M2SA model is designed to consider all of these different types of information when determining whether a tweet expresses a positive, negative, or neutral sentiment.
The key innovation is that the model works across multiple languages, not just English. This makes it more widely applicable, as people use many different languages on Twitter. The researchers tested the model on standard benchmark datasets and found it performed better than other state-of-the-art sentiment analysis approaches. This suggests the multimodal and multilingual capabilities of M2SA provide meaningful advantages for the task of sentiment analysis on social media.
Technical Explanation
The M2SA model has three main components: a text encoder, an image encoder, and a metadata encoder. The text encoder uses a pre-trained language model to generate text feature representations. The image encoder uses a convolutional neural network to extract visual features from tweet images. The metadata encoder processes additional user and tweet-level information.
These three feature streams are then concatenated and passed through additional neural network layers to produce a final sentiment prediction. The model is trained end-to-end on labeled sentiment datasets covering multiple languages.
The researchers evaluate M2SA on benchmark datasets for English, Spanish, and Arabic tweets. They compare the performance to prior state-of-the-art models that only use text or are limited to a single language. The results show M2SA achieves superior sentiment classification accuracy, demonstrating the benefits of the multimodal and multilingual approach.
Critical Analysis
The paper provides a thorough evaluation of the M2SA model on several standard datasets, which lends confidence to the claimed performance improvements. However, the authors do not discuss potential limitations or caveats of their approach.
For example, the model relies on pre-trained components like language models and image encoders, which may have inherent biases or blind spots. Additionally, the datasets used for evaluation may not fully capture the diversity of real-world tweets, especially for under-resourced languages.
Further research could explore the model's robustness to noisy or incomplete data, as well as its generalization to new domains beyond the evaluated benchmark tasks. Analyzing potential fairness and ethical considerations around deploying such a system in the real world would also be valuable.
Conclusion
This paper introduces a novel multimodal and multilingual model called M2SA for sentiment analysis of tweets. By combining textual, visual, and metadata features, the model achieves state-of-the-art performance on benchmark datasets covering multiple languages. The technical contributions demonstrate the value of leveraging diverse information sources to improve natural language processing tasks on user-generated social media content. With further research to address potential limitations, the M2SA approach has promising applications for understanding public sentiment at scale across languages and cultures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
Sentiment Analysis Across Languages: Evaluation Before and After Machine Translation to English
Aekansh Kathunia, Mohammad Kaif, Nalin Arora, N Narotam
0
0
People communicate in more than 7,000 languages around the world, with around 780 languages spoken in India alone. Despite this linguistic diversity, research on Sentiment Analysis has predominantly focused on English text data, resulting in a disproportionate availability of sentiment resources for English. This paper examines the performance of transformer models in Sentiment Analysis tasks across multilingual datasets and text that has undergone machine translation. By comparing the effectiveness of these models in different linguistic contexts, we gain insights into their performance variations and potential implications for sentiment analysis across diverse languages. We also discuss the shortcomings and potential for future work towards the end.
5/7/2024
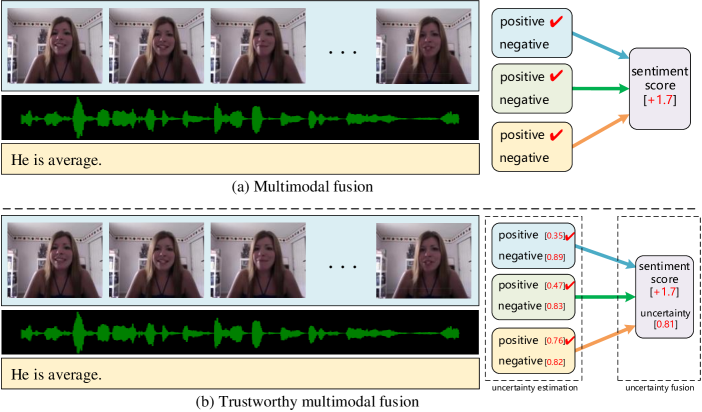
Trustworthy Multimodal Fusion for Sentiment Analysis in Ordinal Sentiment Space
Zhuyang Xie, Yan Yang, Jie Wang, Xiaorong Liu, Xiaofan Li
0
0
Multimodal video sentiment analysis aims to integrate multiple modal information to analyze the opinions and attitudes of speakers. Most previous work focuses on exploring the semantic interactions of intra- and inter-modality. However, these works ignore the reliability of multimodality, i.e., modalities tend to contain noise, semantic ambiguity, missing modalities, etc. In addition, previous multimodal approaches treat different modalities equally, largely ignoring their different contributions. Furthermore, existing multimodal sentiment analysis methods directly regress sentiment scores without considering ordinal relationships within sentiment categories, with limited performance. To address the aforementioned problems, we propose a trustworthy multimodal sentiment ordinal network (TMSON) to improve performance in sentiment analysis. Specifically, we first devise a unimodal feature extractor for each modality to obtain modality-specific features. Then, an uncertainty distribution estimation network is customized, which estimates the unimodal uncertainty distributions. Next, Bayesian fusion is performed on the learned unimodal distributions to obtain multimodal distributions for sentiment prediction. Finally, an ordinal-aware sentiment space is constructed, where ordinal regression is used to constrain the multimodal distributions. Our proposed TMSON outperforms baselines on multimodal sentiment analysis tasks, and empirical results demonstrate that TMSON is capable of reducing uncertainty to obtain more robust predictions.
4/16/2024
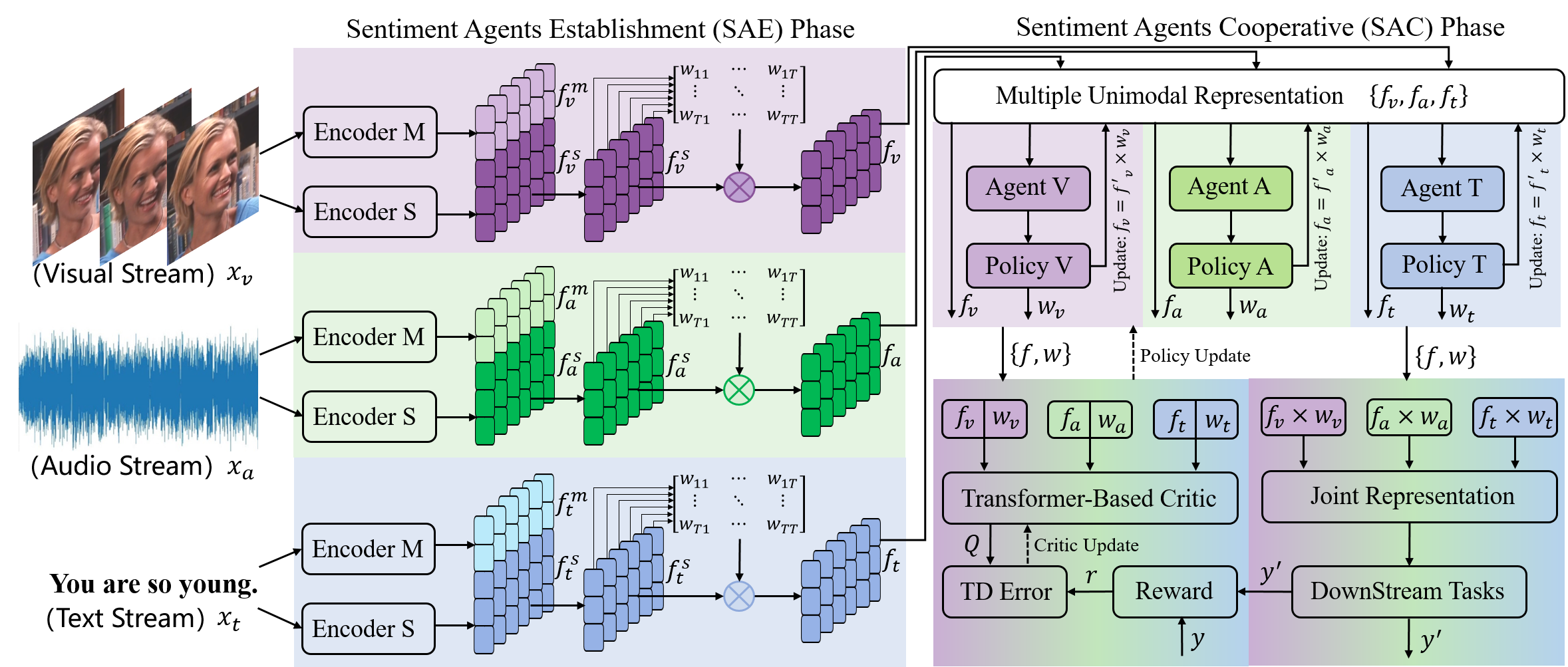
Cooperative Sentiment Agents for Multimodal Sentiment Analysis
Shanmin Wang, Hui Shuai, Qingshan Liu, Fei Wang
0
0
In this paper, we propose a new Multimodal Representation Learning (MRL) method for Multimodal Sentiment Analysis (MSA), which facilitates the adaptive interaction between modalities through Cooperative Sentiment Agents, named Co-SA. Co-SA comprises two critical components: the Sentiment Agents Establishment (SAE) phase and the Sentiment Agents Cooperation (SAC) phase. During the SAE phase, each sentiment agent deals with an unimodal signal and highlights explicit dynamic sentiment variations within the modality via the Modality-Sentiment Disentanglement (MSD) and Deep Phase Space Reconstruction (DPSR) modules. Subsequently, in the SAC phase, Co-SA meticulously designs task-specific interaction mechanisms for sentiment agents so that coordinating multimodal signals to learn the joint representation. Specifically, Co-SA equips an independent policy model for each sentiment agent that captures significant properties within the modality. These policies are optimized mutually through the unified reward adaptive to downstream tasks. Benefitting from the rewarding mechanism, Co-SA transcends the limitation of pre-defined fusion modes and adaptively captures unimodal properties for MRL in the multimodal interaction setting. To demonstrate the effectiveness of Co-SA, we apply it to address Multimodal Sentiment Analysis (MSA) and Multimodal Emotion Recognition (MER) tasks. Our comprehensive experimental results demonstrate that Co-SA excels at discovering diverse cross-modal features, encompassing both common and complementary aspects. The code can be available at https://github.com/smwanghhh/Co-SA.
4/22/2024
🌐
Multimodal Multi-loss Fusion Network for Sentiment Analysis
Zehui Wu, Ziwei Gong, Jaywon Koo, Julia Hirschberg
0
0
This paper investigates the optimal selection and fusion of feature encoders across multiple modalities and combines these in one neural network to improve sentiment detection. We compare different fusion methods and examine the impact of multi-loss training within the multi-modality fusion network, identifying surprisingly important findings relating to subnet performance. We have also found that integrating context significantly enhances model performance. Our best model achieves state-of-the-art performance for three datasets (CMU-MOSI, CMU-MOSEI and CH-SIMS). These results suggest a roadmap toward an optimized feature selection and fusion approach for enhancing sentiment detection in neural networks.
5/10/2024