Human vs. LMMs: Exploring the Discrepancy in Emoji Interpretation and Usage in Digital Communication
2401.08212
0
0
📶
Abstract
Leveraging Large Multimodal Models (LMMs) to simulate human behaviors when processing multimodal information, especially in the context of social media, has garnered immense interest due to its broad potential and far-reaching implications. Emojis, as one of the most unique aspects of digital communication, are pivotal in enriching and often clarifying the emotional and tonal dimensions. Yet, there is a notable gap in understanding how these advanced models, such as GPT-4V, interpret and employ emojis in the nuanced context of online interaction. This study intends to bridge this gap by examining the behavior of GPT-4V in replicating human-like use of emojis. The findings reveal a discernible discrepancy between human and GPT-4V behaviors, likely due to the subjective nature of human interpretation and the limitations of GPT-4V's English-centric training, suggesting cultural biases and inadequate representation of non-English cultures.
Create account to get full access
Overview
- This paper explores the use of large multimodal models (LMMs) like GPT-4V to simulate human behaviors when processing multimodal information, particularly in the context of social media.
- Emojis are a unique aspect of digital communication that can convey emotional and tonal dimensions, but there is a gap in understanding how advanced models like GPT-4V interpret and employ emojis in online interactions.
- The study aims to bridge this gap by examining the behavior of GPT-4V in replicating human-like use of emojis.
Plain English Explanation
The paper investigates how powerful artificial intelligence (AI) models, like GPT-4V, can be used to mimic human behavior when processing information from different sources, especially on social media. Emojis, those small icons we use in digital messages, are a crucial part of how we express emotions and tone online. However, there's a lack of understanding about how these advanced AI models interpret and use emojis in the same nuanced way that humans do.
The researchers wanted to see how well the GPT-4V model could replicate the way people use emojis in online interactions. Their findings suggest that there are notable differences between how humans and GPT-4V use emojis. This is likely because the subjective nature of human interpretation and the limitations of GPT-4V's training, which is focused on English, can lead to cultural biases and a lack of understanding of non-English cultures.
Technical Explanation
The paper investigates the use of large multimodal models (LMMs) like GPT-4V to simulate human behaviors when processing multimodal information, particularly in the context of social media. Emojis are a unique aspect of digital communication that can enrich and clarify the emotional and tonal dimensions of online interactions.
The study examines the behavior of GPT-4V in replicating human-like use of emojis, aiming to bridge the gap in understanding how these advanced models interpret and employ emojis in the nuanced context of online interaction. The findings reveal a discernible discrepancy between human and GPT-4V behaviors, likely due to the subjective nature of human interpretation and the limitations of GPT-4V's English-centric training, suggesting cultural biases and inadequate representation of non-English cultures.
The researchers used a variety of methods, including dialogue benchmarking and unsupervised sentiment analysis, to evaluate the model's performance in using emojis in a way that mimics human behavior. The results indicate that while LMMs like GPT-4V can provide better context and emotion understanding in certain situations, they still struggle to fully capture the nuances of human emoji usage.
Critical Analysis
The paper highlights the limitations of current LMMs, such as GPT-4V, in accurately replicating human-like use of emojis. The authors acknowledge that the subjective nature of human interpretation and the cultural biases inherent in the training data of these models can lead to discrepancies in their performance.
One potential issue not addressed in the paper is the ethics of using LMMs to simulate human behaviors, especially in the context of social media, where the potential for manipulation or misrepresentation could have significant societal implications. The researchers could have explored this angle more thoroughly.
Additionally, the study focuses on a single model, GPT-4V, and it would be valuable to see how other LMMs perform in similar tasks to gain a more comprehensive understanding of the field. Expanding the research to include a wider range of models and cultural contexts could provide deeper insights and inform the development of more inclusive and accurate multimodal AI systems.
Conclusion
This paper highlights the challenges of using large multimodal models (LMMs) like GPT-4V to simulate human behaviors, particularly in the context of social media interactions involving emojis. The findings suggest that while these advanced models can provide better context and emotion understanding in certain situations, they still struggle to fully capture the nuances of human emoji usage, likely due to cultural biases and limitations in their training data.
The research underscores the need for continued advancements in multimodal AI to better understand and replicate the complexities of human communication, especially in the rapidly evolving digital landscape. As LMMs become increasingly prevalent, it is crucial to address the ethical implications of using these models to simulate human behaviors and ensure that they are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Are Large Language Models More Empathetic than Humans?
Anuradha Welivita, Pearl Pu
0
0
With the emergence of large language models (LLMs), investigating if they can surpass humans in areas such as emotion recognition and empathetic responding has become a focal point of research. This paper presents a comprehensive study exploring the empathetic responding capabilities of four state-of-the-art LLMs: GPT-4, LLaMA-2-70B-Chat, Gemini-1.0-Pro, and Mixtral-8x7B-Instruct in comparison to a human baseline. We engaged 1,000 participants in a between-subjects user study, assessing the empathetic quality of responses generated by humans and the four LLMs to 2,000 emotional dialogue prompts meticulously selected to cover a broad spectrum of 32 distinct positive and negative emotions. Our findings reveal a statistically significant superiority of the empathetic responding capability of LLMs over humans. GPT-4 emerged as the most empathetic, marking approximately 31% increase in responses rated as Good compared to the human benchmark. It was followed by LLaMA-2, Mixtral-8x7B, and Gemini-Pro, which showed increases of approximately 24%, 21%, and 10% in Good ratings, respectively. We further analyzed the response ratings at a finer granularity and discovered that some LLMs are significantly better at responding to specific emotions compared to others. The suggested evaluation framework offers a scalable and adaptable approach for assessing the empathy of new LLMs, avoiding the need to replicate this study's findings in future research.
6/10/2024
EmoLLM: Multimodal Emotional Understanding Meets Large Language Models
Qu Yang, Mang Ye, Bo Du
0
0
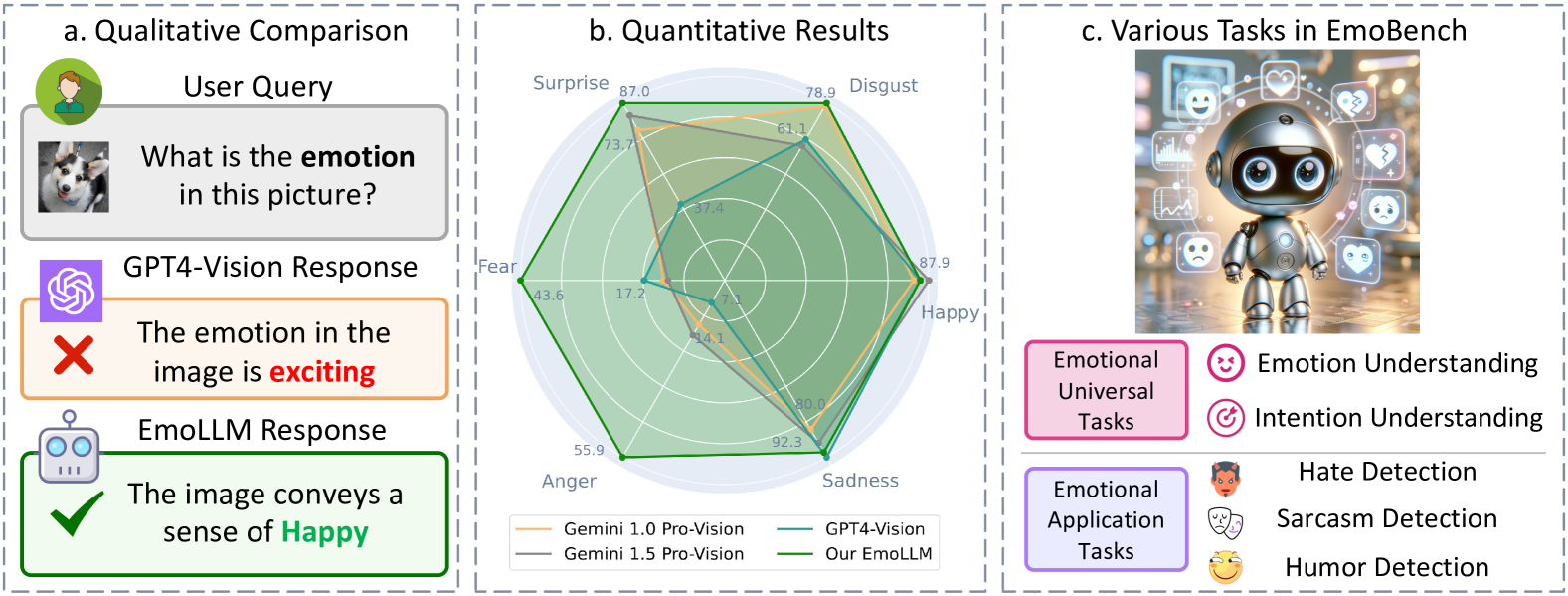
Multi-modal large language models (MLLMs) have achieved remarkable performance on objective multimodal perception tasks, but their ability to interpret subjective, emotionally nuanced multimodal content remains largely unexplored. Thus, it impedes their ability to effectively understand and react to the intricate emotions expressed by humans through multimodal media. To bridge this gap, we introduce EmoBench, the first comprehensive benchmark designed specifically to evaluate the emotional capabilities of MLLMs across five popular emotional tasks, using a diverse dataset of 287k images and videos paired with corresponding textual instructions. Meanwhile, we propose EmoLLM, a novel model for multimodal emotional understanding, incorporating with two core techniques. 1) Multi-perspective Visual Projection, it captures diverse emotional cues from visual data from multiple perspectives. 2) EmoPrompt, it guides MLLMs to reason about emotions in the correct direction. Experimental results demonstrate that EmoLLM significantly elevates multimodal emotional understanding performance, with an average improvement of 12.1% across multiple foundation models on EmoBench. Our work contributes to the advancement of MLLMs by facilitating a deeper and more nuanced comprehension of intricate human emotions, paving the way for the development of artificial emotional intelligence capabilities with wide-ranging applications in areas such as human-computer interaction, mental health support, and empathetic AI systems. Code, data, and model will be released.
7/2/2024
💬
Modeling Emotions and Ethics with Large Language Models
Edward Y. Chang
0
0
This paper explores the integration of human-like emotions and ethical considerations into Large Language Models (LLMs). We first model eight fundamental human emotions, presented as opposing pairs, and employ collaborative LLMs to reinterpret and express these emotions across a spectrum of intensity. Our focus extends to embedding a latent ethical dimension within LLMs, guided by a novel self-supervised learning algorithm with human feedback (SSHF). This approach enables LLMs to perform self-evaluations and adjustments concerning ethical guidelines, enhancing their capability to generate content that is not only emotionally resonant but also ethically aligned. The methodologies and case studies presented herein illustrate the potential of LLMs to transcend mere text and image generation, venturing into the realms of empathetic interaction and principled decision-making, thereby setting a new precedent in the development of emotionally aware and ethically conscious AI systems.
4/23/2024
The Good, the Bad, and the Hulk-like GPT: Analyzing Emotional Decisions of Large Language Models in Cooperation and Bargaining Games
Mikhail Mozikov, Nikita Severin, Valeria Bodishtianu, Maria Glushanina, Mikhail Baklashkin, Andrey V. Savchenko, Ilya Makarov
0
0
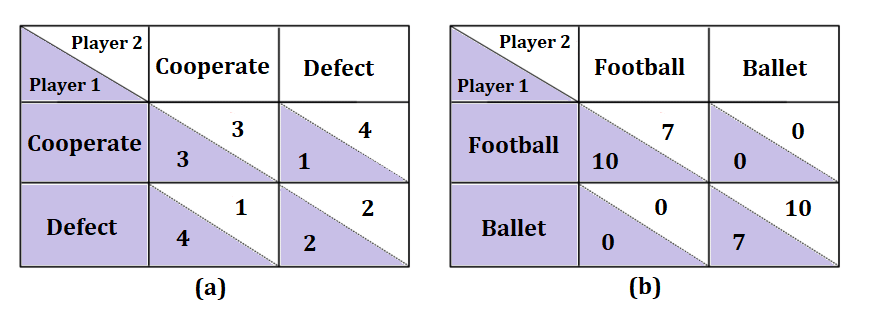
Behavior study experiments are an important part of society modeling and understanding human interactions. In practice, many behavioral experiments encounter challenges related to internal and external validity, reproducibility, and social bias due to the complexity of social interactions and cooperation in human user studies. Recent advances in Large Language Models (LLMs) have provided researchers with a new promising tool for the simulation of human behavior. However, existing LLM-based simulations operate under the unproven hypothesis that LLM agents behave similarly to humans as well as ignore a crucial factor in human decision-making: emotions. In this paper, we introduce a novel methodology and the framework to study both, the decision-making of LLMs and their alignment with human behavior under emotional states. Experiments with GPT-3.5 and GPT-4 on four games from two different classes of behavioral game theory showed that emotions profoundly impact the performance of LLMs, leading to the development of more optimal strategies. While there is a strong alignment between the behavioral responses of GPT-3.5 and human participants, particularly evident in bargaining games, GPT-4 exhibits consistent behavior, ignoring induced emotions for rationality decisions. Surprisingly, emotional prompting, particularly with `anger' emotion, can disrupt the superhuman alignment of GPT-4, resembling human emotional responses.
6/6/2024