Credible, Unreliable or Leaked?: Evidence Verification for Enhanced Automated Fact-checking

0
Sign in to get full access
Overview
• This paper explores the problem of evidence verification for automated fact-checking, focusing on assessing the credibility of information sources. • The authors propose a novel framework that combines natural language processing, knowledge graph reasoning, and multi-modal analysis to determine whether a given piece of information is credible, unreliable, or potentially leaked. • The framework aims to enhance the accuracy and reliability of automated fact-checking systems, which are crucial in the fight against the spread of misinformation and disinformation online.
Plain English Explanation
The paper addresses the challenge of verifying the credibility of information sources in the context of automated fact-checking. Fact-checking is the process of evaluating the accuracy of claims or statements, and it is an important tool in combating the spread of false or misleading information online. However, this process can be time-consuming and labor-intensive when done manually.
The authors of this paper propose a new approach that combines several techniques to automatically assess the credibility of information sources. This includes analyzing the language used in the information, cross-referencing it with known facts and relationships in a knowledge graph (a database of interconnected information), and even looking at the visual elements of the information (such as images or videos).
By using this multi-faceted approach, the researchers aim to create a more accurate and reliable automated fact-checking system. This could help reduce the spread of misinformation and disinformation online, which can have serious consequences for individuals and society as a whole.
Technical Explanation
The paper proposes a novel framework for evidence verification in automated fact-checking. The framework integrates natural language processing, knowledge graph reasoning, and multi-modal analysis to determine the credibility of information sources.
The natural language processing component analyzes the textual content of the information to identify linguistic cues that may indicate unreliable or leaked sources. The knowledge graph reasoning component cross-references the information with a database of known facts and relationships to assess its consistency with established knowledge. The multi-modal analysis component examines any visual elements, such as images or videos, to detect anomalies or manipulations that could suggest the information is unreliable.
By combining these complementary techniques, the framework aims to provide a more comprehensive and accurate assessment of the credibility of information sources. The authors evaluate the performance of their approach on a dataset of fact-checked claims and demonstrate its superiority over baseline methods.
Critical Analysis
The paper presents a compelling approach to enhancing automated fact-checking through evidence verification. The authors' use of a multi-modal analysis, incorporating natural language processing, knowledge graph reasoning, and visual cues, is a notable strength of the framework.
However, the paper does acknowledge some limitations. The authors note that the performance of the framework is still dependent on the quality and coverage of the underlying knowledge graph and the accuracy of the natural language processing and multi-modal analysis models. Additionally, the paper does not address the potential ethical and privacy concerns associated with the extensive data collection and analysis required for such a system.
Further research could explore ways to improve the robustness and generalizability of the framework, as well as address the ethical implications of deploying such a system at scale. Incorporating user feedback and transparency into the decision-making process could also help build trust and acceptance of the technology.
Conclusion
This paper introduces a comprehensive framework for evidence verification in automated fact-checking. By combining natural language processing, knowledge graph reasoning, and multi-modal analysis, the proposed approach aims to enhance the accuracy and reliability of automated systems in assessing the credibility of information sources.
The successful implementation of this framework could have significant implications for the fight against the spread of misinformation and disinformation online, which is a pressing issue with far-reaching consequences for individuals and society. The authors' work represents an important step forward in the development of more robust and trustworthy automated fact-checking technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Credible, Unreliable or Leaked?: Evidence Verification for Enhanced Automated Fact-checking
Zacharias Chrysidis, Stefanos-Iordanis Papadopoulos, Symeon Papadopoulos, Panagiotis C. Petrantonakis
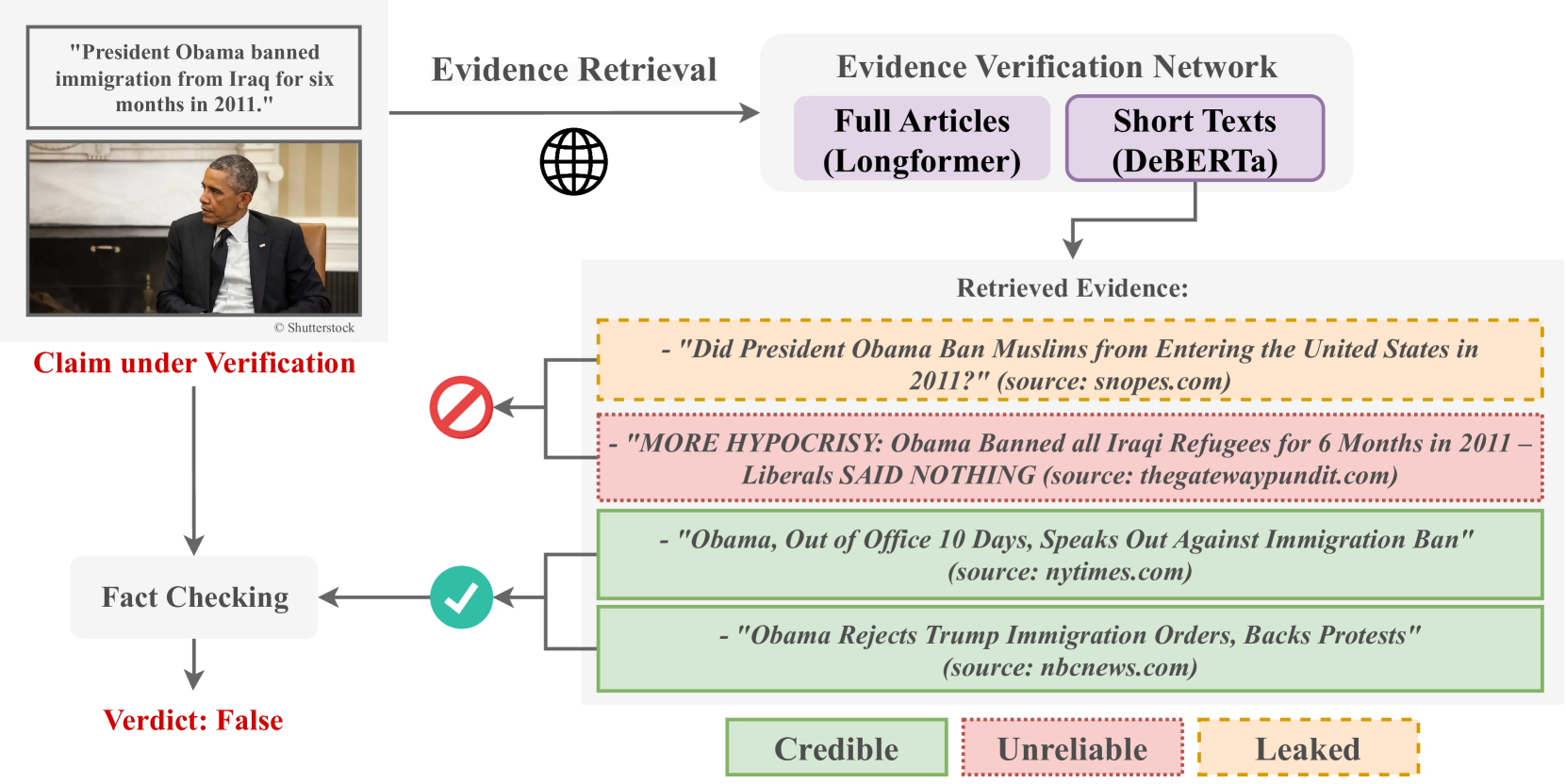
Automated fact-checking (AFC) is garnering increasing attention by researchers aiming to help fact-checkers combat the increasing spread of misinformation online. While many existing AFC methods incorporate external information from the Web to help examine the veracity of claims, they often overlook the importance of verifying the source and quality of collected evidence. One overlooked challenge involves the reliance on leaked evidence, information gathered directly from fact-checking websites and used to train AFC systems, resulting in an unrealistic setting for early misinformation detection. Similarly, the inclusion of information from unreliable sources can undermine the effectiveness of AFC systems. To address these challenges, we present a comprehensive approach to evidence verification and filtering. We create the CREDible, Unreliable or LEaked (CREDULE) dataset, which consists of 91,632 articles classified as Credible, Unreliable and Fact checked (Leaked). Additionally, we introduce the EVidence VERification Network (EVVER-Net), trained on CREDULE to detect leaked and unreliable evidence in both short and long texts. EVVER-Net can be used to filter evidence collected from the Web, thus enhancing the robustness of end-to-end AFC systems. We experiment with various language models and show that EVVER-Net can demonstrate impressive performance of up to 91.5% and 94.4% accuracy, while leveraging domain credibility scores along with short or long texts, respectively. Finally, we assess the evidence provided by widely-used fact-checking datasets including LIAR-PLUS, MOCHEG, FACTIFY, NewsCLIPpings+ and VERITE, some of which exhibit concerning rates of leaked and unreliable evidence.
Read more5/1/2024

0
Automated Justification Production for Claim Veracity in Fact Checking: A Survey on Architectures and Approaches
Islam Eldifrawi, Shengrui Wang, Amine Trabelsi
Automated Fact-Checking (AFC) is the automated verification of claim accuracy. AFC is crucial in discerning truth from misinformation, especially given the huge amounts of content are generated online daily. Current research focuses on predicting claim veracity through metadata analysis and language scrutiny, with an emphasis on justifying verdicts. This paper surveys recent methodologies, proposing a comprehensive taxonomy and presenting the evolution of research in that landscape. A comparative analysis of methodologies and future directions for improving fact-checking explainability are also discussed.
Read more7/19/2024
🌐
0
Complex Claim Verification with Evidence Retrieved in the Wild
Jifan Chen, Grace Kim, Aniruddh Sriram, Greg Durrett, Eunsol Choi
Evidence retrieval is a core part of automatic fact-checking. Prior work makes simplifying assumptions in retrieval that depart from real-world use cases: either no access to evidence, access to evidence curated by a human fact-checker, or access to evidence available long after the claim has been made. In this work, we present the first fully automated pipeline to check real-world claims by retrieving raw evidence from the web. We restrict our retriever to only search documents available prior to the claim's making, modeling the realistic scenario where an emerging claim needs to be checked. Our pipeline includes five components: claim decomposition, raw document retrieval, fine-grained evidence retrieval, claim-focused summarization, and veracity judgment. We conduct experiments on complex political claims in the ClaimDecomp dataset and show that the aggregated evidence produced by our pipeline improves veracity judgments. Human evaluation finds the evidence summary produced by our system is reliable (it does not hallucinate information) and relevant to answering key questions about a claim, suggesting that it can assist fact-checkers even when it cannot surface a complete evidence set.
Read more6/18/2024

0
Evidence-backed Fact Checking using RAG and Few-Shot In-Context Learning with LLMs
Ronit Singhal, Pransh Patwa, Parth Patwa, Aman Chadha, Amitava Das
Given the widespread dissemination of misinformation on social media, implementing fact-checking mechanisms for online claims is essential. Manually verifying every claim is highly challenging, underscoring the need for an automated fact-checking system. This paper presents our system designed to address this issue. We utilize the Averitec dataset to assess the veracity of claims. In addition to veracity prediction, our system provides supporting evidence, which is extracted from the dataset. We develop a Retrieve and Generate (RAG) pipeline to extract relevant evidence sentences from a knowledge base, which are then inputted along with the claim into a large language model (LLM) for classification. We also evaluate the few-shot In-Context Learning (ICL) capabilities of multiple LLMs. Our system achieves an 'Averitec' score of 0.33, which is a 22% absolute improvement over the baseline. All code will be made available on All code will be made available on https://github.com/ronit-singhal/evidence-backed-fact-checking-using-rag-and-few-shot-in-context-learning-with-llms.
Read more8/23/2024