Evidence-backed Fact Checking using RAG and Few-Shot In-Context Learning with LLMs

0

Sign in to get full access
Overview
- Explores using Retrieval Augmented Generation (RAG) and few-shot in-context learning with large language models (LLMs) for evidence-backed fact checking.
- Aims to improve the accuracy and transparency of fact checking by incorporating relevant evidence from a knowledge base.
- Presents a novel approach that combines retrieval, reasoning, and generation to provide fact checks with supporting evidence.
Plain English Explanation
The paper describes a new approach to fact checking that combines several powerful AI techniques. The key ideas are:
-
Retrieval Augmented Generation (RAG): Using a knowledge base to retrieve relevant information that can be used to aid in fact checking. This helps provide supporting evidence for the fact check, rather than just a simple true/false answer.
-
Few-Shot In-Context Learning: Training the language model on a small number of high-quality fact checking examples. This allows the model to learn the task quickly, without requiring a huge dataset.
-
Combining Retrieval, Reasoning, and Generation: The model retrieves relevant information, reasons about the claim using that information, and then generates a detailed fact check response. This multistep process aims to produce more accurate and transparent fact checks.
The paper shows that this approach can outperform existing fact checking systems, providing more reliable and informative fact checks backed by clear evidence. This could be very helpful for applications like combating the spread of misinformation online.
Technical Explanation
The paper proposes a Retrieval Augmented Generation (RAG) approach for evidence-backed fact checking using few-shot in-context learning with large language models (LLMs).
The key components are:
- Retrieval Module: Uses dense retrieval to find relevant passages from a knowledge base given an input claim.
- Reasoning Module: Takes the claim and retrieved passages, and uses an LLM to generate a fact check response that assesses the truthfulness of the claim.
- Few-Shot In-Context Learning: The LLM is fine-tuned on a small number of high-quality fact checking examples, allowing it to learn the task quickly.
During inference, the system first retrieves relevant passages, then uses the LLM to reason about the claim in the context of the retrieved evidence, and finally generates a detailed fact check response.
The authors evaluate their approach on fact checking benchmarks and show that it outperforms existing scientific QA and claim verification systems, producing more accurate and transparent fact checks.
Critical Analysis
The paper presents a promising approach to fact checking that leverages the strengths of both retrieval-based and generation-based techniques. The use of a knowledge base and in-context learning helps the model to provide fact checks that are grounded in relevant evidence, which is an important improvement over simpler true/false predictions.
However, the authors acknowledge several limitations and areas for future work:
- The performance of the system is still not perfect, and there is room for improvement, especially on more challenging claims.
- The knowledge base used in the experiments is curated and high-quality, but real-world fact checking often needs to deal with noisy, incomplete, or biased information sources.
- The in-context learning approach relies on having a small but high-quality set of training examples, which may not always be available.
Additionally, it would be valuable to further explore the model's ability to provide transparent and interpretable fact checks, perhaps by incorporating techniques like explanatory reasoning or contrastive generation.
Overall, this research represents an important step forward in the quest for more reliable and trustworthy fact checking systems, but there are still significant challenges to overcome.
Conclusion
This paper presents a novel approach to evidence-backed fact checking using Retrieval Augmented Generation (RAG) and few-shot in-context learning with large language models. By combining retrieval, reasoning, and generation, the system can produce more accurate and transparent fact checks that are grounded in relevant evidence.
The authors demonstrate the effectiveness of their approach on fact checking benchmarks, showing improvements over existing systems. While there are still limitations and areas for future work, this research represents an important advancement in the field of automated fact checking, which is crucial for combating the spread of misinformation in the digital age.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evidence-backed Fact Checking using RAG and Few-Shot In-Context Learning with LLMs
Ronit Singhal, Pransh Patwa, Parth Patwa, Aman Chadha, Amitava Das
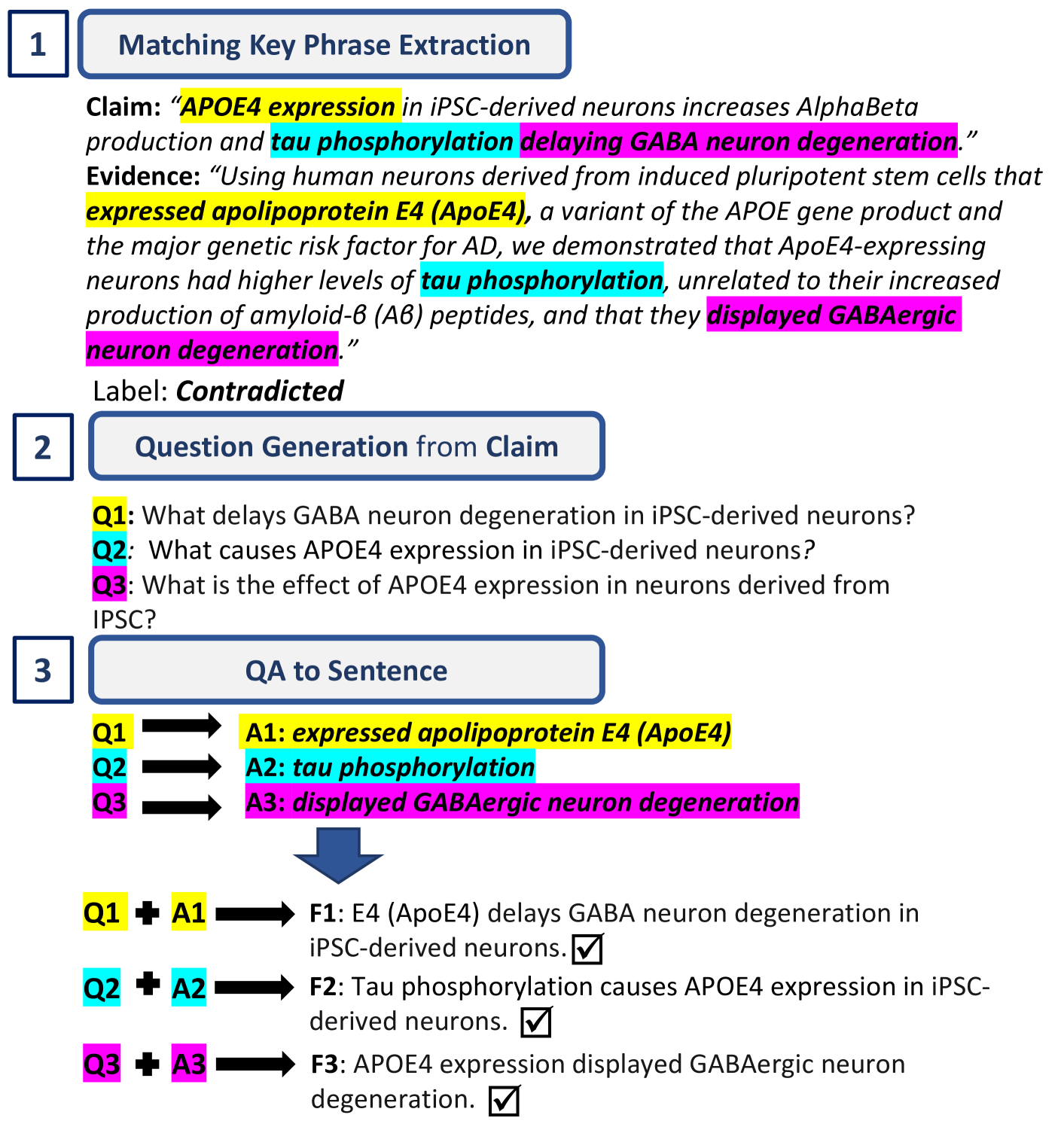
Given the widespread dissemination of misinformation on social media, implementing fact-checking mechanisms for online claims is essential. Manually verifying every claim is highly challenging, underscoring the need for an automated fact-checking system. This paper presents our system designed to address this issue. We utilize the Averitec dataset to assess the veracity of claims. In addition to veracity prediction, our system provides supporting evidence, which is extracted from the dataset. We develop a Retrieve and Generate (RAG) pipeline to extract relevant evidence sentences from a knowledge base, which are then inputted along with the claim into a large language model (LLM) for classification. We also evaluate the few-shot In-Context Learning (ICL) capabilities of multiple LLMs. Our system achieves an 'Averitec' score of 0.33, which is a 22% absolute improvement over the baseline. All code will be made available on All code will be made available on https://github.com/ronit-singhal/evidence-backed-fact-checking-using-rag-and-few-shot-in-context-learning-with-llms.
Read more8/23/2024
0
Robust Claim Verification Through Fact Detection
Nazanin Jafari, James Allan
Claim verification can be a challenging task. In this paper, we present a method to enhance the robustness and reasoning capabilities of automated claim verification through the extraction of short facts from evidence. Our novel approach, FactDetect, leverages Large Language Models (LLMs) to generate concise factual statements from evidence and label these facts based on their semantic relevance to the claim and evidence. The generated facts are then combined with the claim and evidence. To train a lightweight supervised model, we incorporate a fact-detection task into the claim verification process as a multitasking approach to improve both performance and explainability. We also show that augmenting FactDetect in the claim verification prompt enhances performance in zero-shot claim verification using LLMs. Our method demonstrates competitive results in the supervised claim verification model by 15% on the F1 score when evaluated for challenging scientific claim verification datasets. We also demonstrate that FactDetect can be augmented with claim and evidence for zero-shot prompting (AugFactDetect) in LLMs for verdict prediction. We show that AugFactDetect outperforms the baseline with statistical significance on three challenging scientific claim verification datasets with an average of 17.3% performance gain compared to the best performing baselines.
Read more7/29/2024

0
Claim Verification in the Age of Large Language Models: A Survey
Alphaeus Dmonte, Roland Oruche, Marcos Zampieri, Prasad Calyam, Isabelle Augenstein
The large and ever-increasing amount of data available on the Internet coupled with the laborious task of manual claim and fact verification has sparked the interest in the development of automated claim verification systems. Several deep learning and transformer-based models have been proposed for this task over the years. With the introduction of Large Language Models (LLMs) and their superior performance in several NLP tasks, we have seen a surge of LLM-based approaches to claim verification along with the use of novel methods such as Retrieval Augmented Generation (RAG). In this survey, we present a comprehensive account of recent claim verification frameworks using LLMs. We describe the different components of the claim verification pipeline used in these frameworks in detail including common approaches to retrieval, prompting, and fine-tuning. Finally, we describe publicly available English datasets created for this task.
Read more8/27/2024

0
RAGAR, Your Falsehood RADAR: RAG-Augmented Reasoning for Political Fact-Checking using Multimodal Large Language Models
M. Abdul Khaliq, P. Chang, M. Ma, B. Pflugfelder, F. Mileti'c
The escalating challenge of misinformation, particularly in political discourse, requires advanced fact-checking solutions; this is even clearer in the more complex scenario of multimodal claims. We tackle this issue using a multimodal large language model in conjunction with retrieval-augmented generation (RAG), and introduce two novel reasoning techniques: Chain of RAG (CoRAG) and Tree of RAG (ToRAG). They fact-check multimodal claims by extracting both textual and image content, retrieving external information, and reasoning subsequent questions to be answered based on prior evidence. We achieve a weighted F1-score of 0.85, surpassing a baseline reasoning technique by 0.14 points. Human evaluation confirms that the vast majority of our generated fact-check explanations contain all information from gold standard data.
Read more7/15/2024