Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
2404.02747
0
2

Abstract
This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after few inference steps. Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics. Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity, but also maintains model performance. This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness. The source code of TGATE is available at https://github.com/HaozheLiu-ST/T-GATE.
Create account to get full access
Overview
- This paper examines the role of cross-attention in text-to-image diffusion models, which are a type of machine learning model used to generate images from textual descriptions.
- The researchers found that the cross-attention mechanism, which allows the model to dynamically focus on relevant parts of the text when generating the image, can make the inference process cumbersome and computationally expensive.
- The paper proposes potential solutions to address this issue and explores the tradeoffs involved in designing efficient text-to-image diffusion models.
Plain English Explanation
Text-to-image diffusion models are a powerful type of machine learning system that can create images based on textual descriptions. These models work by breaking down the image generation process into a series of small, incremental steps, which allows them to produce highly detailed and realistic images.
One key component of these models is the cross-attention mechanism, which enables the model to dynamically focus on the most relevant parts of the text when generating each part of the image. This helps the model to ensure that the generated image is closely aligned with the textual description.
However, the researchers found that this cross-attention mechanism can also make the inference process, which is the step where the model generates the final image, quite cumbersome and computationally expensive. This is because the model needs to repeatedly compute the cross-attention weights between the text and the partially generated image at each step of the process.
The paper explores potential solutions to this problem, such as using more efficient attention mechanisms or finding ways to reduce the number of inference steps required. The researchers also discuss the tradeoffs involved in designing these text-to-image diffusion models, as optimizing for efficiency may come at the cost of other desirable qualities, such as image quality or flexibility.
Technical Explanation
The paper focuses on the role of cross-attention in text-to-image diffusion models, which are a type of generative model that can create images from textual descriptions. Diffusion models work by breaking down the image generation process into a series of small, iterative steps, where each step involves adding a small amount of noise to the partially generated image.
The key component that enables these models to generate images that closely match the textual input is the cross-attention mechanism. This mechanism allows the model to dynamically focus on the most relevant parts of the text when generating each part of the image. This helps to ensure that the generated image is closely aligned with the textual description.
However, the researchers found that this cross-attention mechanism can make the inference process, which is the step where the model generates the final image, quite cumbersome and computationally expensive. This is because the model needs to repeatedly compute the cross-attention weights between the text and the partially generated image at each step of the inference process.
To address this issue, the paper explores potential solutions, such as using more efficient attention mechanisms or finding ways to reduce the number of inference steps required. The researchers also discuss the tradeoffs involved in designing these text-to-image diffusion models, as optimizing for efficiency may come at the cost of other desirable qualities, such as image quality or flexibility.
Critical Analysis
The paper raises an important issue regarding the efficiency of text-to-image diffusion models, which are a rapidly advancing area of machine learning with significant potential applications. The researchers' observation that the cross-attention mechanism can make the inference process computationally expensive is a valid concern, as the ability to generate high-quality images efficiently is crucial for many real-world applications.
While the paper proposes potential solutions to address this issue, such as using more efficient attention mechanisms, it would be helpful to see a more in-depth exploration of the tradeoffs involved in these approaches. For example, the researchers could have delved deeper into the potential impact on image quality or flexibility, as optimizing for efficiency may come at the cost of other desirable model characteristics.
Additionally, the paper does not provide a comprehensive analysis of the broader implications of this research. It would be valuable to consider how the findings from this study could inform the design of future text-to-image diffusion models, and how the identified challenges might impact the wider field of generative AI.
Conclusion
This paper highlights an important challenge in the design of text-to-image diffusion models, namely the computational burden imposed by the cross-attention mechanism. The researchers' observation that this mechanism can make the inference process cumbersome is a significant finding, as it points to a potential bottleneck in the development of efficient and practical text-to-image generation systems.
The proposed solutions and the discussion of the tradeoffs involved provide a solid foundation for further research in this area. As the field of generative AI continues to evolve, addressing the efficiency and performance challenges of text-to-image diffusion models will be crucial in unlocking their full potential for a wide range of applications, from creative content generation to data visualization and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Investigating the Effectiveness of Cross-Attention to Unlock Zero-Shot Editing of Text-to-Video Diffusion Models
Saman Motamed, Wouter Van Gansbeke, Luc Van Gool
0
0
With recent advances in image and video diffusion models for content creation, a plethora of techniques have been proposed for customizing their generated content. In particular, manipulating the cross-attention layers of Text-to-Image (T2I) diffusion models has shown great promise in controlling the shape and location of objects in the scene. Transferring image-editing techniques to the video domain, however, is extremely challenging as object motion and temporal consistency are difficult to capture accurately. In this work, we take a first look at the role of cross-attention in Text-to-Video (T2V) diffusion models for zero-shot video editing. While one-shot models have shown potential in controlling motion and camera movement, we demonstrate zero-shot control over object shape, position and movement in T2V models. We show that despite the limitations of current T2V models, cross-attention guidance can be a promising approach for editing videos.
4/9/2024
📈
Diffusion Model with Cross Attention as an Inductive Bias for Disentanglement
Tao Yang, Cuiling Lan, Yan Lu, Nanning zheng
0
0
Disentangled representation learning strives to extract the intrinsic factors within observed data. Factorizing these representations in an unsupervised manner is notably challenging and usually requires tailored loss functions or specific structural designs. In this paper, we introduce a new perspective and framework, demonstrating that diffusion models with cross-attention can serve as a powerful inductive bias to facilitate the learning of disentangled representations. We propose to encode an image to a set of concept tokens and treat them as the condition of the latent diffusion for image reconstruction, where cross-attention over the concept tokens is used to bridge the interaction between the encoder and diffusion. Without any additional regularization, this framework achieves superior disentanglement performance on the benchmark datasets, surpassing all previous methods with intricate designs. We have conducted comprehensive ablation studies and visualization analysis, shedding light on the functioning of this model. This is the first work to reveal the potent disentanglement capability of diffusion models with cross-attention, requiring no complex designs. We anticipate that our findings will inspire more investigation on exploring diffusion for disentangled representation learning towards more sophisticated data analysis and understanding.
6/13/2024
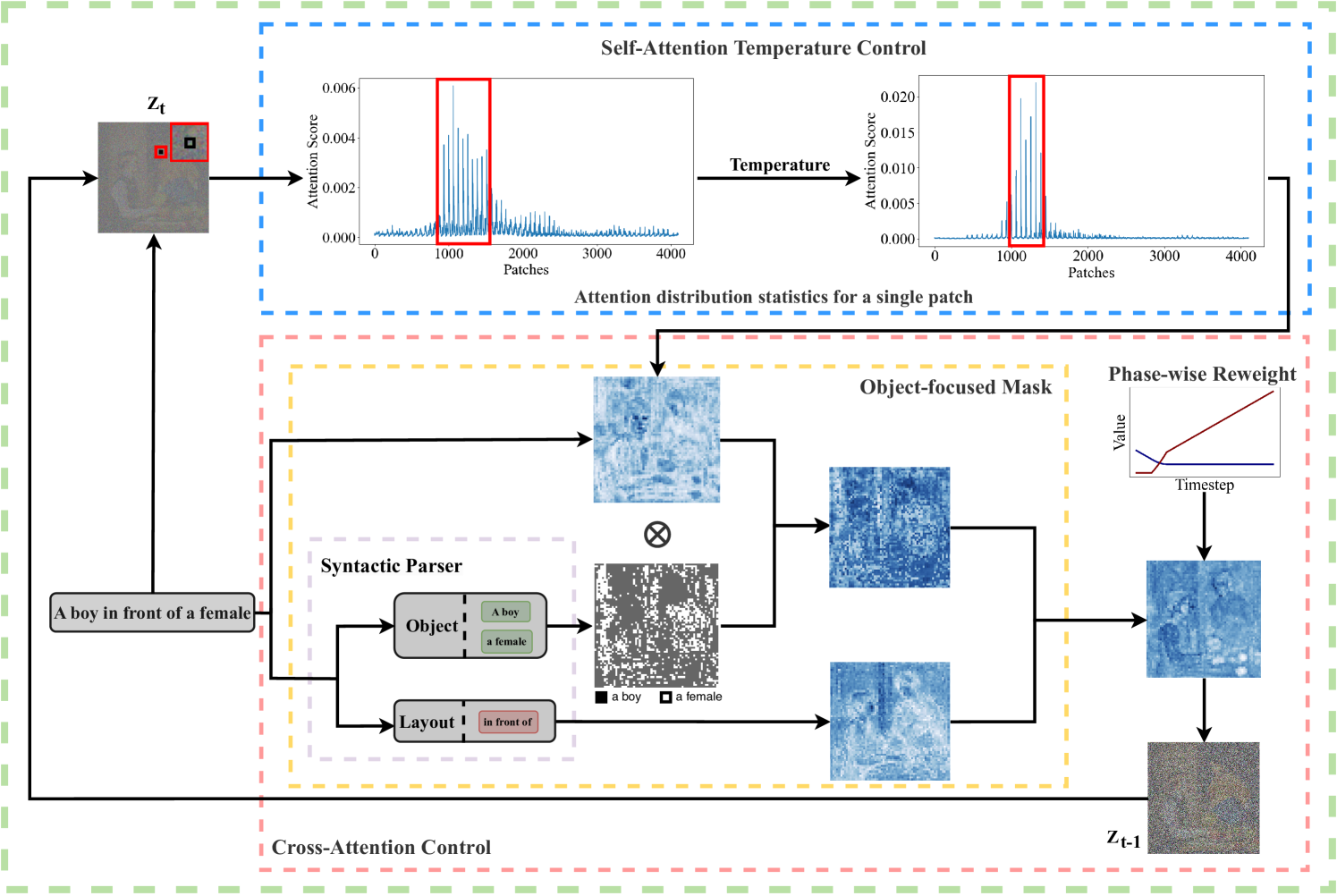
Towards Better Text-to-Image Generation Alignment via Attention Modulation
Yihang Wu, Xiao Cao, Kaixin Li, Zitan Chen, Haonan Wang, Lei Meng, Zhiyong Huang
0
0
In text-to-image generation tasks, the advancements of diffusion models have facilitated the fidelity of generated results. However, these models encounter challenges when processing text prompts containing multiple entities and attributes. The uneven distribution of attention results in the issues of entity leakage and attribute misalignment. Training from scratch to address this issue requires numerous labeled data and is resource-consuming. Motivated by this, we propose an attribution-focusing mechanism, a training-free phase-wise mechanism by modulation of attention for diffusion model. One of our core ideas is to guide the model to concentrate on the corresponding syntactic components of the prompt at distinct timesteps. To achieve this, we incorporate a temperature control mechanism within the early phases of the self-attention modules to mitigate entity leakage issues. An object-focused masking scheme and a phase-wise dynamic weight control mechanism are integrated into the cross-attention modules, enabling the model to discern the affiliation of semantic information between entities more effectively. The experimental results in various alignment scenarios demonstrate that our model attain better image-text alignment with minimal additional computational cost.
4/23/2024

MIST: Mitigating Intersectional Bias with Disentangled Cross-Attention Editing in Text-to-Image Diffusion Models
Hidir Yesiltepe, Kiymet Akdemir, Pinar Yanardag
0
0
Diffusion-based text-to-image models have rapidly gained popularity for their ability to generate detailed and realistic images from textual descriptions. However, these models often reflect the biases present in their training data, especially impacting marginalized groups. While prior efforts to debias language models have focused on addressing specific biases, such as racial or gender biases, efforts to tackle intersectional bias have been limited. Intersectional bias refers to the unique form of bias experienced by individuals at the intersection of multiple social identities. Addressing intersectional bias is crucial because it amplifies the negative effects of discrimination based on race, gender, and other identities. In this paper, we introduce a method that addresses intersectional bias in diffusion-based text-to-image models by modifying cross-attention maps in a disentangled manner. Our approach utilizes a pre-trained Stable Diffusion model, eliminates the need for an additional set of reference images, and preserves the original quality for unaltered concepts. Comprehensive experiments demonstrate that our method surpasses existing approaches in mitigating both single and intersectional biases across various attributes. We make our source code and debiased models for various attributes available to encourage fairness in generative models and to support further research.
4/1/2024