Towards Better Text-to-Image Generation Alignment via Attention Modulation
2404.13899
0
0
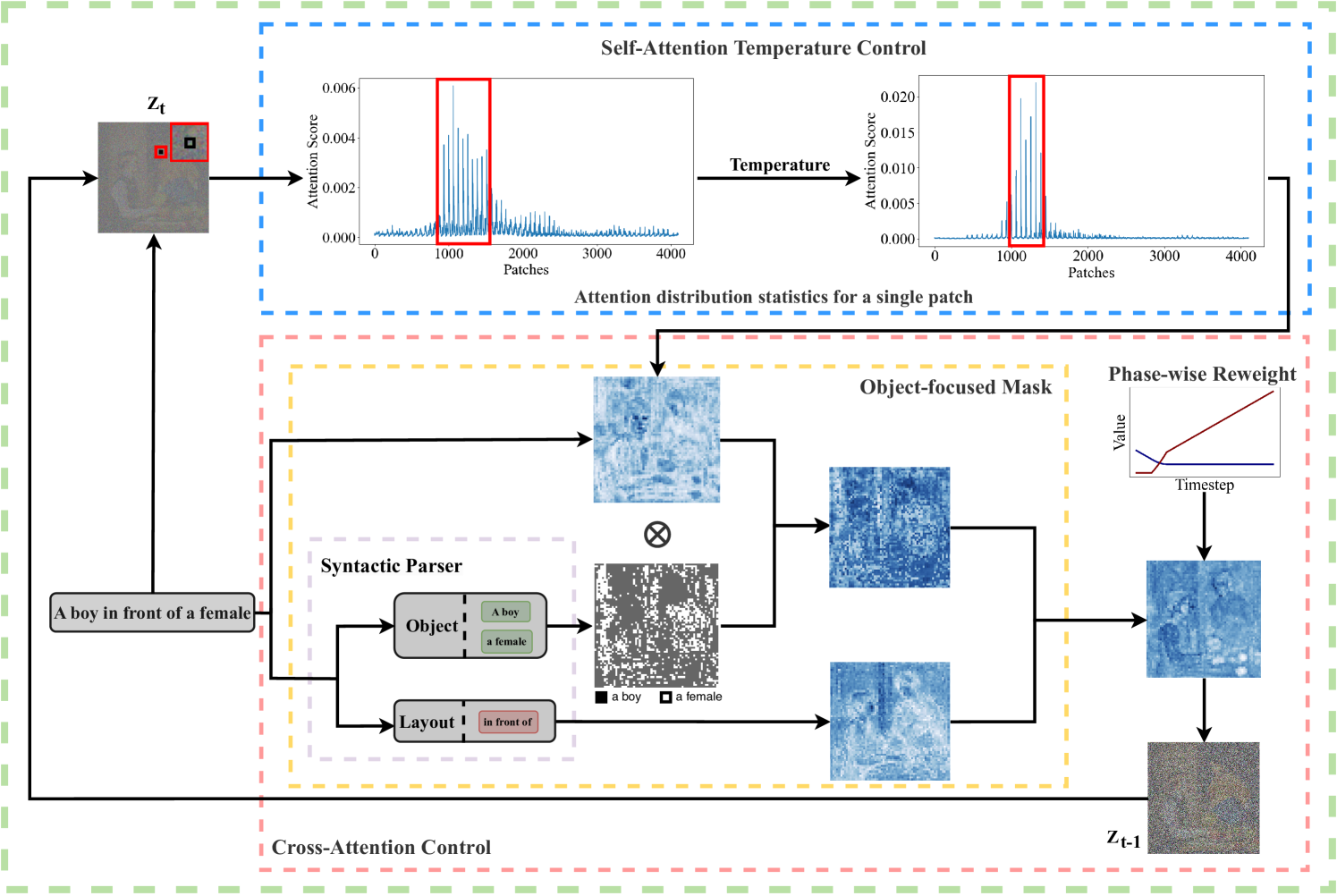
Abstract
In text-to-image generation tasks, the advancements of diffusion models have facilitated the fidelity of generated results. However, these models encounter challenges when processing text prompts containing multiple entities and attributes. The uneven distribution of attention results in the issues of entity leakage and attribute misalignment. Training from scratch to address this issue requires numerous labeled data and is resource-consuming. Motivated by this, we propose an attribution-focusing mechanism, a training-free phase-wise mechanism by modulation of attention for diffusion model. One of our core ideas is to guide the model to concentrate on the corresponding syntactic components of the prompt at distinct timesteps. To achieve this, we incorporate a temperature control mechanism within the early phases of the self-attention modules to mitigate entity leakage issues. An object-focused masking scheme and a phase-wise dynamic weight control mechanism are integrated into the cross-attention modules, enabling the model to discern the affiliation of semantic information between entities more effectively. The experimental results in various alignment scenarios demonstrate that our model attain better image-text alignment with minimal additional computational cost.
Create account to get full access
Overview
- This paper proposes a method to improve the alignment between text and generated images in text-to-image generation models.
- The key idea is to modulate the attention mechanism in the model to better capture the relevant visual features corresponding to the input text.
- The authors demonstrate the effectiveness of their approach on several text-to-image generation benchmarks, showing improved performance compared to previous methods.
Plain English Explanation
Text-to-image generation models, which can create images from textual descriptions, have made significant progress in recent years. However, one challenge is ensuring that the generated images are well-aligned with the input text, meaning the visual content accurately reflects the semantic meaning of the text.
The authors of this paper have developed a new technique to address this challenge. Their approach focuses on the attention mechanism, a key component of many text-to-image generation models. Attention allows the model to dynamically focus on the most relevant parts of the text when generating each part of the image.
The researchers found that by carefully modulating or adjusting the attention mechanism, they could improve the alignment between the text and the generated images. This means the model is better able to capture the relevant visual features that correspond to the input text, leading to images that more closely match the semantic meaning of the description.
The authors evaluated their method on several standard text-to-image benchmarks and showed that it outperformed previous approaches in generating images that are well-aligned with the input text. This is an important advance, as improving text-to-image alignment can lead to more accurate and useful generation models.
Technical Explanation
The paper introduces a novel attention modulation technique to enhance the alignment between text and generated images in text-to-image diffusion models. Diffusion models are a type of generative model that generate images by iteratively adding and then removing noise from an input image.
The key innovation is the attention modulation module, which is inserted into the diffusion model's attention layers. This module dynamically adjusts the attention weights during the diffusion process to better capture the visual features relevant to the input text. The authors hypothesize that this targeted attention control can lead to generated images that are more semantically aligned with the textual description.
Experiments on several text-to-image benchmarks, including COCO and Conceptual Captions, demonstrate the effectiveness of the proposed attention modulation approach. The method outperforms previous state-of-the-art techniques, such as attention calibration and swap attention, in terms of various text-to-image alignment metrics.
Critical Analysis
The paper presents a promising approach for improving text-to-image alignment, but there are a few areas that could be further explored or addressed:
-
Generalization: While the method shows strong performance on the evaluated benchmarks, it would be valuable to assess its robustness and generalization to a wider range of text-to-image tasks, including personalized generation or text-to-video generation.
-
Computational Efficiency: The attention modulation module introduces additional computational complexity to the diffusion model. The authors could investigate ways to make the approach more efficient, particularly for real-world applications where inference speed is crucial.
-
Interpretability: Further research could explore ways to make the attention modulation process more interpretable, allowing users to understand how the model is prioritizing different aspects of the text when generating the corresponding visual features.
-
Multimodal Alignment: The current work focuses on improving text-to-image alignment, but it would be interesting to see if the attention modulation approach could be extended to enhance alignment across other modalities, such as text-to-speech or text-to-video generation.
Overall, the proposed attention modulation technique is a valuable contribution to the field of text-to-image generation, and the authors have demonstrated its effectiveness through rigorous experimentation. Further research building on this work could lead to even more accurate and useful multimodal generation models.
Conclusion
This paper presents a novel attention modulation approach to improve the alignment between text and generated images in diffusion-based text-to-image models. By dynamically adjusting the attention weights during the diffusion process, the method is able to better capture the visual features that correspond to the input text, leading to generated images that are more semantically aligned with the textual descriptions.
The authors have shown the effectiveness of their approach on several text-to-image benchmarks, outperforming previous state-of-the-art techniques. This work represents an important advancement in the field of text-to-image generation, with the potential to enable more accurate and useful multimodal generation models. Further research building on this foundation could explore ways to improve the method's generalization, efficiency, and interpretability, as well as extend the approach to other multimodal tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Attribute-Aware Implicit Modality Alignment for Text Attribute Person Search
Xin Wang, Fangfang Liu, Zheng Li, Caili Guo
0
0
Text attribute person search aims to find specific pedestrians through given textual attributes, which is very meaningful in the scene of searching for designated pedestrians through witness descriptions. The key challenge is the significant modality gap between textual attributes and images. Previous methods focused on achieving explicit representation and alignment through unimodal pre-trained models. Nevertheless, the absence of inter-modality correspondence in these models may lead to distortions in the local information of intra-modality. Moreover, these methods only considered the alignment of inter-modality and ignored the differences between different attribute categories. To mitigate the above problems, we propose an Attribute-Aware Implicit Modality Alignment (AIMA) framework to learn the correspondence of local representations between textual attributes and images and combine global representation matching to narrow the modality gap. Firstly, we introduce the CLIP model as the backbone and design prompt templates to transform attribute combinations into structured sentences. This facilitates the model's ability to better understand and match image details. Next, we design a Masked Attribute Prediction (MAP) module that predicts the masked attributes after the interaction of image and masked textual attribute features through multi-modal interaction, thereby achieving implicit local relationship alignment. Finally, we propose an Attribute-IoU Guided Intra-Modal Contrastive (A-IoU IMC) loss, aligning the distribution of different textual attributes in the embedding space with their IoU distribution, achieving better semantic arrangement. Extensive experiments on the Market-1501 Attribute, PETA, and PA100K datasets show that the performance of our proposed method significantly surpasses the current state-of-the-art methods.
6/7/2024

Object-Attribute Binding in Text-to-Image Generation: Evaluation and Control
Maria Mihaela Trusca, Wolf Nuyts, Jonathan Thomm, Robert Honig, Thomas Hofmann, Tinne Tuytelaars, Marie-Francine Moens
0
0
Current diffusion models create photorealistic images given a text prompt as input but struggle to correctly bind attributes mentioned in the text to the right objects in the image. This is evidenced by our novel image-graph alignment model called EPViT (Edge Prediction Vision Transformer) for the evaluation of image-text alignment. To alleviate the above problem, we propose focused cross-attention (FCA) that controls the visual attention maps by syntactic constraints found in the input sentence. Additionally, the syntax structure of the prompt helps to disentangle the multimodal CLIP embeddings that are commonly used in T2I generation. The resulting DisCLIP embeddings and FCA are easily integrated in state-of-the-art diffusion models without additional training of these models. We show substantial improvements in T2I generation and especially its attribute-object binding on several datasets.footnote{Code and data will be made available upon acceptance.
4/23/2024
🛸
Training-free Subject-Enhanced Attention Guidance for Compositional Text-to-image Generation
Shengyuan Liu, Bo Wang, Ye Ma, Te Yang, Xipeng Cao, Quan Chen, Han Li, Di Dong, Peng Jiang
0
0
Existing subject-driven text-to-image generation models suffer from tedious fine-tuning steps and struggle to maintain both text-image alignment and subject fidelity. For generating compositional subjects, it often encounters problems such as object missing and attribute mixing, where some subjects in the input prompt are not generated or their attributes are incorrectly combined. To address these limitations, we propose a subject-driven generation framework and introduce training-free guidance to intervene in the generative process during inference time. This approach strengthens the attention map, allowing for precise attribute binding and feature injection for each subject. Notably, our method exhibits exceptional zero-shot generation ability, especially in the challenging task of compositional generation. Furthermore, we propose a novel metric GroundingScore to evaluate subject alignment thoroughly. The obtained quantitative results serve as compelling evidence showcasing the effectiveness of our proposed method. The code will be released soon.
5/14/2024

Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
Wentian Zhang, Haozhe Liu, Jinheng Xie, Francesco Faccio, Mike Zheng Shou, Jurgen Schmidhuber
0
0
This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after few inference steps. Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics. Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity, but also maintains model performance. This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness. The source code of TGATE is available at https://github.com/HaozheLiu-ST/T-GATE.
4/4/2024