Investigating the Effectiveness of Cross-Attention to Unlock Zero-Shot Editing of Text-to-Video Diffusion Models
2404.05519
0
1

Abstract
With recent advances in image and video diffusion models for content creation, a plethora of techniques have been proposed for customizing their generated content. In particular, manipulating the cross-attention layers of Text-to-Image (T2I) diffusion models has shown great promise in controlling the shape and location of objects in the scene. Transferring image-editing techniques to the video domain, however, is extremely challenging as object motion and temporal consistency are difficult to capture accurately. In this work, we take a first look at the role of cross-attention in Text-to-Video (T2V) diffusion models for zero-shot video editing. While one-shot models have shown potential in controlling motion and camera movement, we demonstrate zero-shot control over object shape, position and movement in T2V models. We show that despite the limitations of current T2V models, cross-attention guidance can be a promising approach for editing videos.
Create account to get full access
Overview
- This paper investigates how cross-attention mechanisms can be used to enable zero-shot editing of text-to-video diffusion models, which are AI systems that generate video from text prompts.
- The authors explore how cross-attention, a technique that allows models to focus on relevant parts of their input, can be leveraged to provide fine-grained control over the generated videos without the need for additional training.
- Key findings include insights into the trade-offs between expressive power and inference efficiency when using cross-attention, as well as strategies for mitigating intersectional bias in these types of models.
Plain English Explanation
The paper looks at how a technique called "cross-attention" can be used to give people more control over the videos generated by AI models that create video from text. These AI models, called "text-to-video diffusion models," are trained on a large amount of data to learn how to generate videos based on text descriptions.
The researchers found that cross-attention, which allows the AI model to focus on the most relevant parts of its input, can be used to fine-tune the generated videos without having to retrain the entire model. This could let people make more targeted edits, like changing the appearance of an object or the actions of a character, just by providing some additional text instructions.
However, the researchers also discovered that relying too heavily on cross-attention can make the video generation process slower and less efficient. They explored ways to balance the benefits of cross-attention with the need for the model to generate videos quickly and without introducing unwanted biases.
Overall, this work provides insights into how to unlock more powerful and customizable video generation capabilities, while also highlighting important practical and ethical considerations that need to be addressed as these AI technologies continue to advance.
Technical Explanation
The paper investigates the use of cross-attention mechanisms to enable zero-shot editing of text-to-video diffusion models, such as MIST and VideoEdit.
Cross-attention allows the model to dynamically focus on the most relevant parts of its input (e.g., the text prompt) when generating the output (the video). The authors hypothesize that by leveraging cross-attention, these models can be more easily fine-tuned for specific editing tasks without the need for additional training.
To test this, the researchers propose a novel cross-attention-based editing framework called CCEdit, which they evaluate on a range of text-to-video editing tasks. Their experiments show that cross-attention can indeed enable zero-shot editing capabilities, but also reveal important trade-offs between expressive power and inference efficiency.
The paper also explores strategies for mitigating intersectional biases in cross-attention-based text-to-video models, building on prior work like MIST. Key insights include the need to carefully design the cross-attention mechanism to avoid over-reliance on spurious correlations in the training data.
Critical Analysis
The paper provides a valuable exploration of the potential and challenges of using cross-attention to unlock more flexible and controllable text-to-video generation. The authors' insights into the tension between expressive power and inference efficiency are particularly noteworthy, as this is a crucial practical consideration for deploying these models in real-world applications.
That said, the paper's focus is primarily on the technical aspects of the problem, and it would be beneficial to see a more in-depth discussion of the broader societal implications of this technology. For example, the authors mention the importance of mitigating intersectional biases, but do not delve deeply into the potential harms that could arise from these models, such as the perpetuation of harmful stereotypes or the generation of misinformation.
Additionally, while the proposed CCEdit framework shows promise, it would be helpful to see more extensive evaluation, particularly in terms of the qualitative and subjective aspects of the generated videos (e.g., coherence, creativity, emotional impact).
Overall, the paper makes a valuable contribution to the understanding of cross-attention in text-to-video diffusion models, but could be strengthened by a more holistic consideration of the ethical and practical challenges that come with unlocking such powerful generative capabilities.
Conclusion
This paper investigates the use of cross-attention mechanisms to enable zero-shot editing of text-to-video diffusion models, which are AI systems that can generate videos from text prompts. The key findings include insights into the trade-offs between expressive power and inference efficiency when using cross-attention, as well as strategies for mitigating intersectional bias in these types of models.
The research provides a technical foundation for unlocking more flexible and controllable text-to-video generation, which could have important applications in areas like creative content production, education, and entertainment. However, the paper also highlights the need to carefully consider the broader societal implications of this technology, particularly around issues of bias, ethics, and the potential for misuse.
As the field of text-to-video AI continues to evolve, it will be crucial for researchers and developers to maintain a balanced and holistic perspective, weighing the benefits of these powerful generative capabilities against the potential risks and challenges they present.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
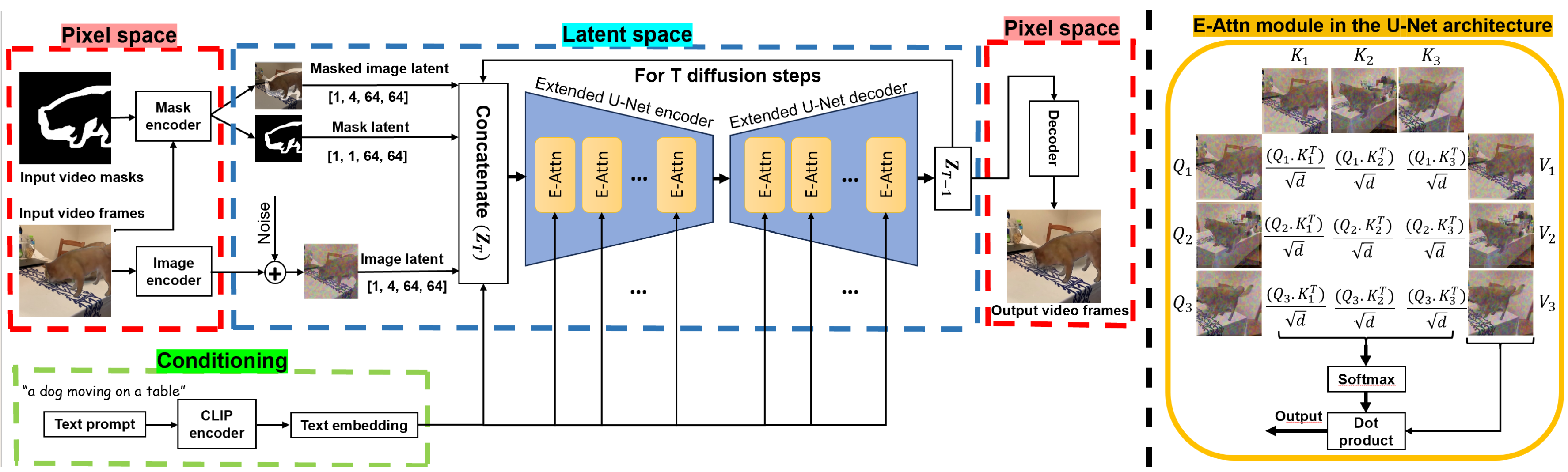
Temporally Consistent Object Editing in Videos using Extended Attention
AmirHossein Zamani, Amir G. Aghdam, Tiberiu Popa, Eugene Belilovsky
0
0
Image generation and editing have seen a great deal of advancements with the rise of large-scale diffusion models that allow user control of different modalities such as text, mask, depth maps, etc. However, controlled editing of videos still lags behind. Prior work in this area has focused on using 2D diffusion models to globally change the style of an existing video. On the other hand, in many practical applications, editing localized parts of the video is critical. In this work, we propose a method to edit videos using a pre-trained inpainting image diffusion model. We systematically redesign the forward path of the model by replacing the self-attention modules with an extended version of attention modules that creates frame-level dependencies. In this way, we ensure that the edited information will be consistent across all the video frames no matter what the shape and position of the masked area is. We qualitatively compare our results with state-of-the-art in terms of accuracy on several video editing tasks like object retargeting, object replacement, and object removal tasks. Simulations demonstrate the superior performance of the proposed strategy.
6/4/2024

Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection
Gihyun Kwon, Jangho Park, Jong Chul Ye
0
0
While text-to-image models have achieved impressive capabilities in image generation and editing, their application across various modalities often necessitates training separate models. Inspired by existing method of single image editing with self attention injection and video editing with shared attention, we propose a novel unified editing framework that combines the strengths of both approaches by utilizing only a basic 2D image text-to-image (T2I) diffusion model. Specifically, we design a sampling method that facilitates editing consecutive images while maintaining semantic consistency utilizing shared self-attention features during both reference and consecutive image sampling processes. Experimental results confirm that our method enables editing across diverse modalities including 3D scenes, videos, and panorama images.
5/28/2024

Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
Wentian Zhang, Haozhe Liu, Jinheng Xie, Francesco Faccio, Mike Zheng Shou, Jurgen Schmidhuber
0
0
This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after few inference steps. Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics. Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity, but also maintains model performance. This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness. The source code of TGATE is available at https://github.com/HaozheLiu-ST/T-GATE.
4/4/2024
🖼️
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models
Haomiao Ni, Bernhard Egger, Suhas Lohit, Anoop Cherian, Ye Wang, Toshiaki Koike-Akino, Sharon X. Huang, Tim K. Marks
0
0
Text-conditioned image-to-video generation (TI2V) aims to synthesize a realistic video starting from a given image (e.g., a woman's photo) and a text description (e.g., a woman is drinking water.). Existing TI2V frameworks often require costly training on video-text datasets and specific model designs for text and image conditioning. In this paper, we propose TI2V-Zero, a zero-shot, tuning-free method that empowers a pretrained text-to-video (T2V) diffusion model to be conditioned on a provided image, enabling TI2V generation without any optimization, fine-tuning, or introducing external modules. Our approach leverages a pretrained T2V diffusion foundation model as the generative prior. To guide video generation with the additional image input, we propose a repeat-and-slide strategy that modulates the reverse denoising process, allowing the frozen diffusion model to synthesize a video frame-by-frame starting from the provided image. To ensure temporal continuity, we employ a DDPM inversion strategy to initialize Gaussian noise for each newly synthesized frame and a resampling technique to help preserve visual details. We conduct comprehensive experiments on both domain-specific and open-domain datasets, where TI2V-Zero consistently outperforms a recent open-domain TI2V model. Furthermore, we show that TI2V-Zero can seamlessly extend to other tasks such as video infilling and prediction when provided with more images. Its autoregressive design also supports long video generation.
4/26/2024