Cross-Domain Continual Learning via CLAMP
2405.07142
0
0
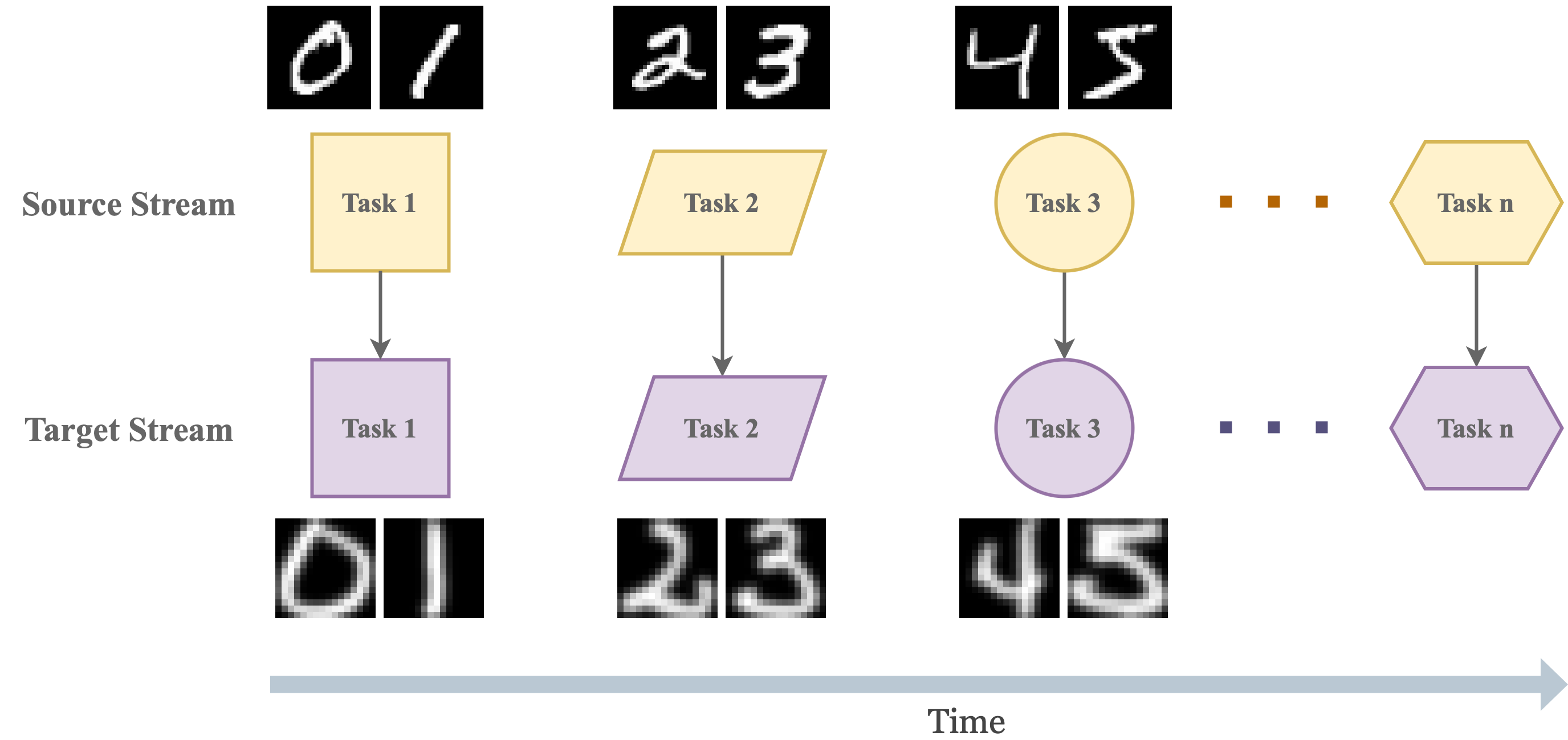
Abstract
Artificial neural networks, celebrated for their human-like cognitive learning abilities, often encounter the well-known catastrophic forgetting (CF) problem, where the neural networks lose the proficiency in previously acquired knowledge. Despite numerous efforts to mitigate CF, it remains the significant challenge particularly in complex changing environments. This challenge is even more pronounced in cross-domain adaptation following the continual learning (CL) setting, which is a more challenging and realistic scenario that is under-explored. To this end, this article proposes a cross-domain CL approach making possible to deploy a single model in such environments without additional labelling costs. Our approach, namely continual learning approach for many processes (CLAMP), integrates a class-aware adversarial domain adaptation strategy to align a source domain and a target domain. An assessor-guided learning process is put forward to navigate the learning process of a base model assigning a set of weights to every sample controlling the influence of every sample and the interactions of each loss function in such a way to balance the stability and plasticity dilemma thus preventing the CF problem. The first assessor focuses on the negative transfer problem rejecting irrelevant samples of the source domain while the second assessor prevents noisy pseudo labels of the target domain. Both assessors are trained in the meta-learning approach using random transformation techniques and similar samples of the source domain. Theoretical analysis and extensive numerical validations demonstrate that CLAMP significantly outperforms established baseline algorithms across all experiments by at least $10%$ margin.
Create account to get full access
Overview
- This paper proposes a novel approach called CLAMP (Cross-domain Continual Learning via Adversarial Mapping) that enables continual learning across different domains.
- The key idea is to learn a mapping function that can transfer knowledge between domains, allowing the model to adapt to new tasks without forgetting previous ones.
- CLAMP leverages adversarial training to learn this mapping function, which is crucial for effective cross-domain continual learning.
Plain English Explanation
The paper introduces a new technique called CLAMP that helps AI models learn continuously across different types of data or "domains." Typically, AI models struggle to learn new tasks without forgetting what they've learned before. CLAMP solves this problem by teaching the model to translate knowledge between domains.
Imagine an AI assistant that starts by learning to recognize images of cats and dogs. Then, you want it to learn to also recognize images of cars and trucks. Without CLAMP, the assistant might forget how to recognize cats and dogs as it learns the new car and truck task. But with CLAMP, the assistant can learn to map the knowledge it gained about cats and dogs onto the new car and truck domain. This allows it to continuously expand its capabilities without losing previous knowledge.
The key innovation in CLAMP is the use of "adversarial training," a technique that pits part of the AI model against another part, forcing it to learn a robust translation between domains. This adversarial process is crucial for the model to be able to effectively transfer its learning across different types of data.
Technical Explanation
The paper proposes a continual learning approach called CLAMP (Cross-domain Continual Learning via Adversarial Mapping) that can learn continuously across different domains. CLAMP learns a mapping function that can transfer knowledge between domains, enabling the model to adapt to new tasks without forgetting previous ones.
The core of CLAMP is an adversarial training process that learns this cross-domain mapping. Specifically, the model consists of a task-specific network and a domain mapping network. The task-specific network learns to perform the target task, while the domain mapping network learns to translate the task-specific representations between domains. These two networks are trained adversarially, with the task-specific network trying to fool the domain mapping network and the domain mapping network trying to correctly identify the domain of the task-specific representations.
This adversarial training process forces the domain mapping network to learn a robust transformation between domains, which is crucial for effective cross-domain continual learning. The authors demonstrate the effectiveness of CLAMP on various continual learning benchmarks, showing that it outperforms state-of-the-art continual learning methods.
Critical Analysis
The paper provides a compelling approach to the challenging problem of continual learning in cross-domain settings. The key strength of CLAMP is its ability to learn a mapping function that can transfer knowledge between domains, which is a crucial capability for real-world applications where the distribution of data is constantly changing.
However, the paper does not address some potential limitations of the approach. For example, the adversarial training process may be unstable and difficult to optimize, which could limit the practical applicability of CLAMP. Additionally, the paper does not explore the scalability of the approach to larger and more diverse datasets, or how it might perform in more realistic continual learning scenarios.
Further research is needed to address these limitations and explore the broader implications of the CLAMP approach. For example, it would be interesting to see how CLAMP compares to other continual learning methods that use different techniques, such as memory replay or network expansion, in cross-domain settings.
Conclusion
Overall, the CLAMP approach presented in this paper represents an important step forward in the field of continual learning. By learning a cross-domain mapping function, CLAMP enables AI models to continuously expand their capabilities without forgetting previous knowledge. This could have significant implications for the development of more flexible and adaptable AI systems that can operate effectively in complex, real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Overcoming Domain Drift in Online Continual Learning
Fan Lyu, Daofeng Liu, Linglan Zhao, Zhang Zhang, Fanhua Shang, Fuyuan Hu, Wei Feng, Liang Wang
0
0
Online Continual Learning (OCL) empowers machine learning models to acquire new knowledge online across a sequence of tasks. However, OCL faces a significant challenge: catastrophic forgetting, wherein the model learned in previous tasks is substantially overwritten upon encountering new tasks, leading to a biased forgetting of prior knowledge. Moreover, the continual doman drift in sequential learning tasks may entail the gradual displacement of the decision boundaries in the learned feature space, rendering the learned knowledge susceptible to forgetting. To address the above problem, in this paper, we propose a novel rehearsal strategy, termed Drift-Reducing Rehearsal (DRR), to anchor the domain of old tasks and reduce the negative transfer effects. First, we propose to select memory for more representative samples guided by constructed centroids in a data stream. Then, to keep the model from domain chaos in drifting, a two-level angular cross-task Contrastive Margin Loss (CML) is proposed, to encourage the intra-class and intra-task compactness, and increase the inter-class and inter-task discrepancy. Finally, to further suppress the continual domain drift, we present an optional Centorid Distillation Loss (CDL) on the rehearsal memory to anchor the knowledge in feature space for each previous old task. Extensive experimental results on four benchmark datasets validate that the proposed DRR can effectively mitigate the continual domain drift and achieve the state-of-the-art (SOTA) performance in OCL.
5/16/2024
💬
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Hao Wang
0
0
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
4/26/2024

Advancing Cross-domain Discriminability in Continual Learning of Vison-Language Models
Yicheng Xu, Yuxin Chen, Jiahao Nie, Yusong Wang, Huiping Zhuang, Manabu Okumura
0
0
Continual learning (CL) with Vision-Language Models (VLMs) has overcome the constraints of traditional CL, which only focuses on previously encountered classes. During the CL of VLMs, we need not only to prevent the catastrophic forgetting on incrementally learned knowledge but also to preserve the zero-shot ability of VLMs. However, existing methods require additional reference datasets to maintain such zero-shot ability and rely on domain-identity hints to classify images across different domains. In this study, we propose Regression-based Analytic Incremental Learning (RAIL), which utilizes a recursive ridge regression-based adapter to learn from a sequence of domains in a non-forgetting manner and decouple the cross-domain correlations by projecting features to a higher-dimensional space. Cooperating with a training-free fusion module, RAIL absolutely preserves the VLM's zero-shot ability on unseen domains without any reference data. Additionally, we introduce Cross-domain Task-Agnostic Incremental Learning (X-TAIL) setting. In this setting, a CL learner is required to incrementally learn from multiple domains and classify test images from both seen and unseen domains without any domain-identity hint. We theoretically prove RAIL's absolute memorization on incrementally learned domains. Experiment results affirm RAIL's state-of-the-art performance in both X-TAIL and existing Multi-domain Task-Incremental Learning settings. The code will be released upon acceptance.
6/28/2024
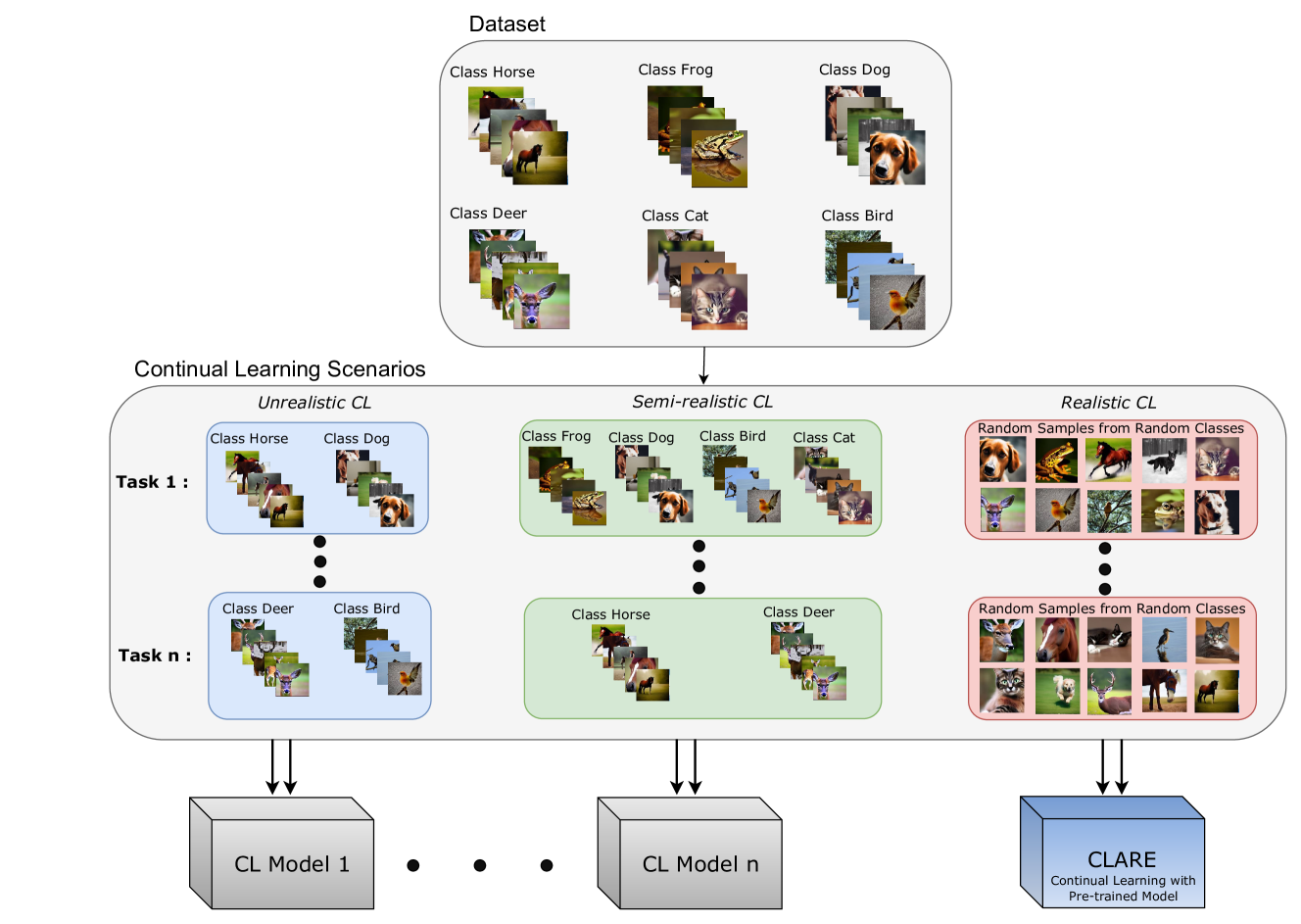
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
0
0
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
4/12/2024