Remembering Transformer for Continual Learning
2404.07518
0
0
Abstract
Neural networks encounter the challenge of Catastrophic Forgetting (CF) in continual learning, where new task learning interferes with previously learned knowledge. Existing data fine-tuning and regularization methods necessitate task identity information during inference and cannot eliminate interference among different tasks, while soft parameter sharing approaches encounter the problem of an increasing model parameter size. To tackle these challenges, we propose the Remembering Transformer, inspired by the brain's Complementary Learning Systems (CLS). Remembering Transformer employs a mixture-of-adapters architecture and a generative model-based novelty detection mechanism in a pretrained Transformer to alleviate CF. Remembering Transformer dynamically routes task data to the most relevant adapter with enhanced parameter efficiency based on knowledge distillation. We conducted extensive experiments, including ablation studies on the novelty detection mechanism and model capacity of the mixture-of-adapters, in a broad range of class-incremental split tasks and permutation tasks. Our approach demonstrated SOTA performance surpassing the second-best method by 15.90% in the split tasks, reducing the memory footprint from 11.18M to 0.22M in the five splits CIFAR10 task.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel approach called "Remembering Transformer" to address the problem of catastrophic forgetting in continual learning.
- Continual learning is the ability of a model to learn new tasks sequentially without forgetting previously learned information.
- Catastrophic forgetting is a common issue in continual learning, where a model forgets previously learned knowledge when trained on new tasks.
Plain English Explanation
The paper introduces a new technique called "Remembering Transformer" to help AI models learn new skills without forgetting what they've already learned. This is an important problem in the field of continual learning, where models are trained on a series of tasks one after the other.
The key challenge is that when a model learns a new task, it can often forget the information it learned for previous tasks. This is known as catastrophic forgetting. The "Remembering Transformer" approach aims to address this by helping the model retain its memory of past tasks while also learning new ones.
The paper explains the technical details of how this works, but the core idea is to give the model a way to remember and reuse the knowledge it's gained from earlier tasks. This allows the model to build on its previous learning rather than starting from scratch each time, which helps prevent forgetting.
Technical Explanation
The paper introduces a continual learning task setting where a model is trained on a sequence of tasks, and the goal is to maintain high performance on all tasks without forgetting previous knowledge. This is a common problem in continual learning, known as catastrophic forgetting.
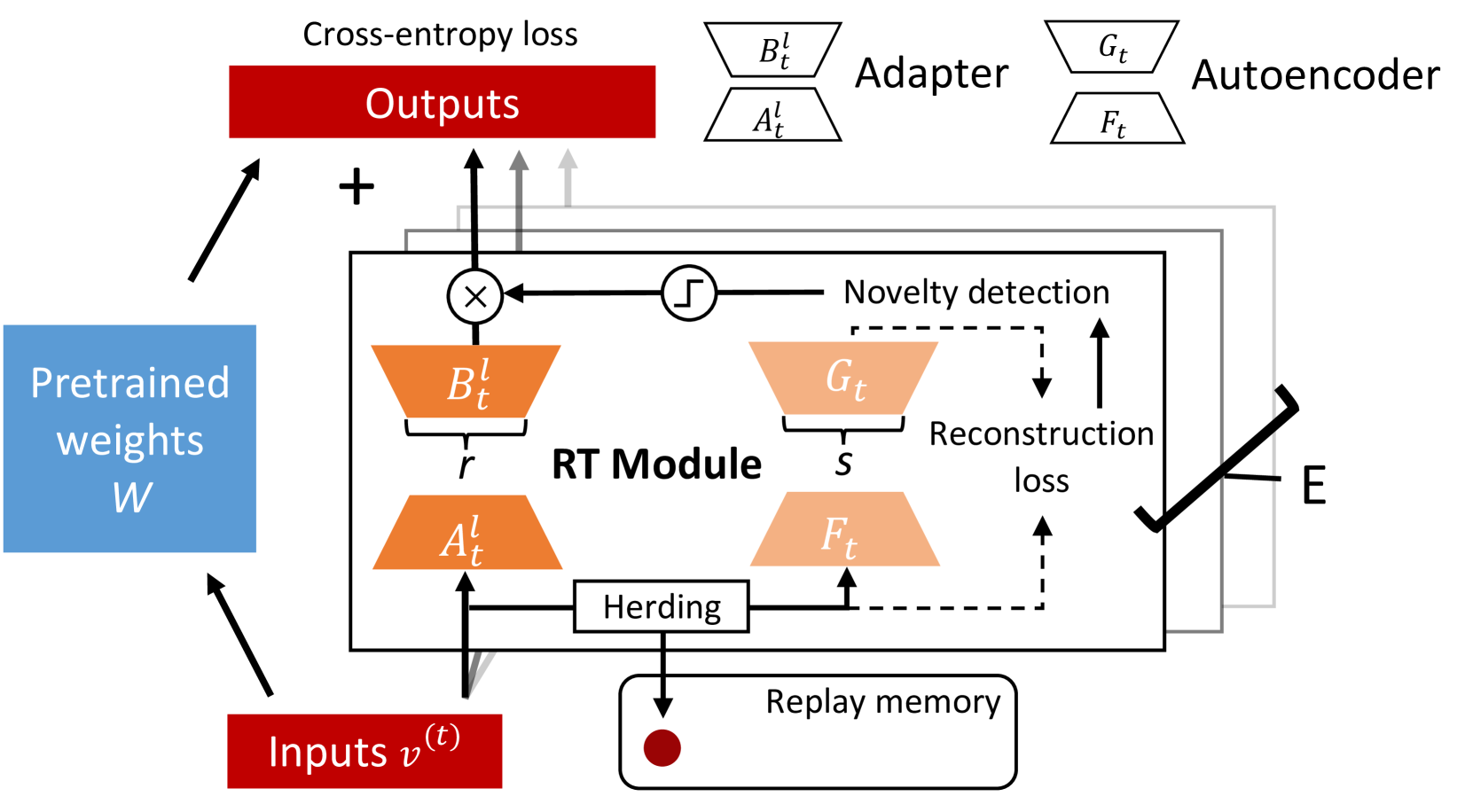
To address this, the authors propose a novel architecture called the "Remembering Transformer." This model consists of a standard Transformer encoder-decoder, along with an additional "Remembering Module" that is designed to selectively remember and reuse relevant knowledge from previous tasks.
The key innovation is the Remembering Module, which maintains a memory bank of task-specific parameters. When the model is trained on a new task, it learns which parameters in the memory bank are relevant and should be reused, rather than discarding all previous knowledge. This helps the model build upon its existing knowledge rather than starting from scratch, mitigating catastrophic forgetting.
The paper evaluates the Remembering Transformer on several continual learning benchmarks and demonstrates significant improvements over existing approaches, such as CORE and RLCA. The results suggest that the Remembering Module is an effective way to selectively remember and reuse relevant knowledge, leading to better continual learning performance.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Remembering Transformer, exploring its performance across a range of continual learning tasks and comparing it to state-of-the-art methods. The authors acknowledge some limitations, such as the potential for the memory bank to become unwieldy as the number of tasks increases, and suggest future work to address this.
One potential concern is the computational overhead of the Remembering Module, which adds additional complexity to the model. The authors do not provide a detailed analysis of the runtime and memory requirements of their approach, which would be helpful for understanding its practical feasibility.
Additionally, while the paper demonstrates the Remembering Transformer's effectiveness on standard continual learning benchmarks, it would be valuable to see how the model performs on more realistic, large-scale continual learning scenarios, such as those explored in the Realistic Continual Learning paper.
Conclusion
The Remembering Transformer proposed in this paper represents a promising approach to addressing the challenge of catastrophic forgetting in continual learning. By selectively remembering and reusing relevant knowledge from previous tasks, the model is able to learn new skills while maintaining high performance on earlier tasks.
The paper's thorough evaluation and comparison to state-of-the-art methods suggest that the Remembering Module is an effective technique for continual learning. While further research is needed to address scalability and real-world deployment concerns, this work contributes valuable insights and a novel architecture to the ongoing efforts to develop AI systems that can learn continuously without forgetting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Cross-Domain Continual Learning via CLAMP
Weiwei Weng, Mahardhika Pratama, Jie Zhang, Chen Chen, Edward Yapp Kien Yee, Ramasamy Savitha
0
0
Artificial neural networks, celebrated for their human-like cognitive learning abilities, often encounter the well-known catastrophic forgetting (CF) problem, where the neural networks lose the proficiency in previously acquired knowledge. Despite numerous efforts to mitigate CF, it remains the significant challenge particularly in complex changing environments. This challenge is even more pronounced in cross-domain adaptation following the continual learning (CL) setting, which is a more challenging and realistic scenario that is under-explored. To this end, this article proposes a cross-domain CL approach making possible to deploy a single model in such environments without additional labelling costs. Our approach, namely continual learning approach for many processes (CLAMP), integrates a class-aware adversarial domain adaptation strategy to align a source domain and a target domain. An assessor-guided learning process is put forward to navigate the learning process of a base model assigning a set of weights to every sample controlling the influence of every sample and the interactions of each loss function in such a way to balance the stability and plasticity dilemma thus preventing the CF problem. The first assessor focuses on the negative transfer problem rejecting irrelevant samples of the source domain while the second assessor prevents noisy pseudo labels of the target domain. Both assessors are trained in the meta-learning approach using random transformation techniques and similar samples of the source domain. Theoretical analysis and extensive numerical validations demonstrate that CLAMP significantly outperforms established baseline algorithms across all experiments by at least $10%$ margin.
5/14/2024

Adaptive Memory Replay for Continual Learning
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vyshnavi Gutta, Rogerio Feris, Zsolt Kira, Leonid Karlinsky
0
0
Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
4/22/2024
💬
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, Yue Zhang
0
0
Catastrophic forgetting (CF) is a phenomenon that occurs in machine learning when a model forgets previously learned information while acquiring new knowledge. As large language models (LLMs) have demonstrated remarkable performance, it is intriguing to investigate whether CF exists during the continual instruction tuning of LLMs. This study empirically evaluates the forgetting phenomenon in LLMs' knowledge during continual instruction tuning from the perspectives of domain knowledge, reasoning, and reading comprehension. The experiments reveal that catastrophic forgetting is generally observed in LLMs ranging from 1b to 7b parameters. Moreover, as the model scale increases, the severity of forgetting intensifies. Comparing the decoder-only model BLOOMZ with the encoder-decoder model mT0, BLOOMZ exhibits less forgetting and retains more knowledge. Interestingly, we also observe that LLMs can mitigate language biases, such as gender bias, during continual fine-tuning. Furthermore, our findings indicate that ALPACA maintains more knowledge and capacity compared to LLAMA during continual fine-tuning, suggesting that general instruction tuning can help alleviate the forgetting phenomenon in LLMs during subsequent fine-tuning processes.
4/3/2024
On the Convergence of Continual Learning with Adaptive Methods
Seungyub Han, Yeongmo Kim, Taehyun Cho, Jungwoo Lee
0
0
One of the objectives of continual learning is to prevent catastrophic forgetting in learning multiple tasks sequentially, and the existing solutions have been driven by the conceptualization of the plasticity-stability dilemma. However, the convergence of continual learning for each sequential task is less studied so far. In this paper, we provide a convergence analysis of memory-based continual learning with stochastic gradient descent and empirical evidence that training current tasks causes the cumulative degradation of previous tasks. We propose an adaptive method for nonconvex continual learning (NCCL), which adjusts step sizes of both previous and current tasks with the gradients. The proposed method can achieve the same convergence rate as the SGD method when the catastrophic forgetting term which we define in the paper is suppressed at each iteration. Further, we demonstrate that the proposed algorithm improves the performance of continual learning over existing methods for several image classification tasks.
4/16/2024