Cross-Domain Spatial Matching for Camera and Radar Sensor Data Fusion in Autonomous Vehicle Perception System
2404.16548
0
0

Abstract
In this paper, we propose a novel approach to address the problem of camera and radar sensor fusion for 3D object detection in autonomous vehicle perception systems. Our approach builds on recent advances in deep learning and leverages the strengths of both sensors to improve object detection performance. Precisely, we extract 2D features from camera images using a state-of-the-art deep learning architecture and then apply a novel Cross-Domain Spatial Matching (CDSM) transformation method to convert these features into 3D space. We then fuse them with extracted radar data using a complementary fusion strategy to produce a final 3D object representation. To demonstrate the effectiveness of our approach, we evaluate it on the NuScenes dataset. We compare our approach to both single-sensor performance and current state-of-the-art fusion methods. Our results show that the proposed approach achieves superior performance over single-sensor solutions and could directly compete with other top-level fusion methods.
Create account to get full access
Overview
- This paper presents a method for fusing data from camera and radar sensors in an autonomous vehicle perception system.
- The researchers developed a cross-domain spatial matching approach to align the data from these two different sensor modalities.
- The proposed technique improves the performance of 3D object detection and tracking in autonomous driving applications.
Plain English Explanation
The paper describes a way to combine information from two different types of sensors commonly used in self-driving cars - cameras and radar. Cameras provide detailed visual information about the surrounding environment, while radar detects the distance and movement of objects. <a href="https://aimodels.fyi/papers/arxiv/multimodal-3d-object-detection-unseen-domains">Fusing this data</a> can give a more complete understanding of the driving scene.
The key challenge is that the camera and radar have different reference frames and coordinate systems, so their data doesn't naturally align. The researchers developed a "cross-domain spatial matching" approach to map the sensor data into a common 3D space. This allows the system to accurately associate objects detected by the camera and radar, improving the overall perception capabilities.
By overcoming the sensor alignment problem, this fusion technique can enhance the performance of crucial autonomous driving tasks like <a href="https://aimodels.fyi/papers/arxiv/contextualfusion-context-based-multi-sensor-fusion-3d">3D object detection and tracking</a>. This is an important step towards building more reliable and capable self-driving vehicle systems.
Technical Explanation
The paper proposes a cross-domain spatial matching method to fuse data from camera and radar sensors in an autonomous vehicle perception system. The approach involves three main components:
-
Camera-Radar Extrinsic Calibration: The researchers estimate the 6-DoF transformation between the camera and radar coordinate systems using a optimization-based approach.
-
Cross-Domain Spatial Matching: A neural network is trained to learn the mapping between the camera image space and the radar 3D space, enabling accurate association of detected objects across the two modalities.
-
Multi-Modal 3D Object Detection: The fused camera and radar data is used to perform 3D object detection, leveraging the complementary strengths of the two sensors.
The proposed <a href="https://aimodels.fyi/papers/arxiv/enhanced-radar-perception-via-multi-task-learning">multi-task learning</a> architecture jointly optimizes for 3D object detection, orientation estimation, and confidence prediction. This allows the model to learn robust feature representations that enhance the overall perception performance.
Extensive experiments on the nuScenes dataset demonstrate the effectiveness of the cross-domain spatial matching approach, achieving state-of-the-art results for <a href="https://aimodels.fyi/papers/arxiv/dpft-dual-perspective-fusion-transformer-camera-radar">camera-radar fusion</a> in 3D object detection and tracking tasks.
Critical Analysis
The paper provides a well-designed solution for the important problem of fusing camera and radar data in autonomous driving perception systems. The cross-domain spatial matching technique is a novel and effective way to address the sensor alignment challenge.
One potential limitation is the reliance on the nuScenes dataset, which may not fully capture the diversity of real-world driving scenarios. Further testing on additional datasets or in real-world pilot studies could help validate the generalization of the proposed methods.
Additionally, the paper does not explore the robustness of the system to sensor failures or environmental conditions that may degrade the performance of either the camera or radar. <a href="https://aimodels.fyi/papers/arxiv/human-detection-from-4d-radar-data-low">Investigating the system's resilience</a> in such situations could be an area for future research.
Overall, this work demonstrates a significant advancement in sensor fusion for autonomous vehicles and lays the groundwork for further improvements in perception accuracy and reliability.
Conclusion
This paper presents a novel cross-domain spatial matching approach for fusing camera and radar sensor data in autonomous vehicle perception systems. By addressing the challenge of aligning the data from these two modalities, the proposed technique can enhance the performance of crucial tasks like 3D object detection and tracking.
The demonstrated improvements in perception capabilities represent an important step towards building more reliable and capable self-driving vehicle systems. As autonomous driving technology continues to evolve, techniques like the one described in this paper will play a crucial role in ensuring the safety and robustness of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
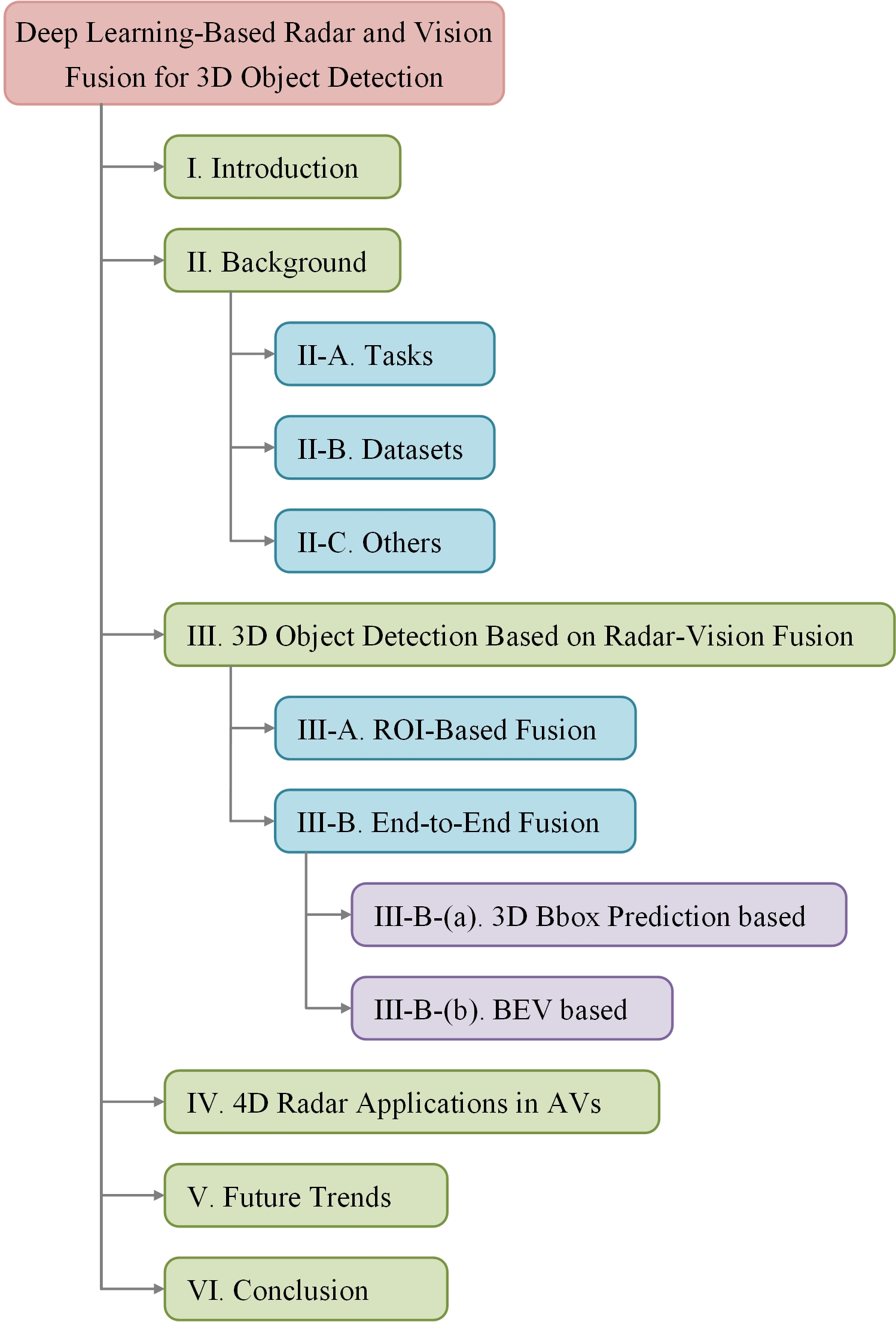
A Survey of Deep Learning Based Radar and Vision Fusion for 3D Object Detection in Autonomous Driving
Di Wu, Feng Yang, Benlian Xu, Pan Liao, Bo Liu
0
0
With the rapid advancement of autonomous driving technology, there is a growing need for enhanced safety and efficiency in the automatic environmental perception of vehicles during their operation. In modern vehicle setups, cameras and mmWave radar (radar), being the most extensively employed sensors, demonstrate complementary characteristics, inherently rendering them conducive to fusion and facilitating the achievement of both robust performance and cost-effectiveness. This paper focuses on a comprehensive survey of radar-vision (RV) fusion based on deep learning methods for 3D object detection in autonomous driving. We offer a comprehensive overview of each RV fusion category, specifically those employing region of interest (ROI) fusion and end-to-end fusion strategies. As the most promising fusion strategy at present, we provide a deeper classification of end-to-end fusion methods, including those 3D bounding box prediction based and BEV based approaches. Moreover, aligning with recent advancements, we delineate the latest information on 4D radar and its cutting-edge applications in autonomous vehicles (AVs). Finally, we present the possible future trends of RV fusion and summarize this paper.
6/4/2024
🔎
RCM-Fusion: Radar-Camera Multi-Level Fusion for 3D Object Detection
Jisong Kim, Minjae Seong, Geonho Bang, Dongsuk Kum, Jun Won Choi
0
0
While LiDAR sensors have been successfully applied to 3D object detection, the affordability of radar and camera sensors has led to a growing interest in fusing radars and cameras for 3D object detection. However, previous radar-camera fusion models were unable to fully utilize the potential of radar information. In this paper, we propose Radar-Camera Multi-level fusion (RCM-Fusion), which attempts to fuse both modalities at both feature and instance levels. For feature-level fusion, we propose a Radar Guided BEV Encoder which transforms camera features into precise BEV representations using the guidance of radar Bird's-Eye-View (BEV) features and combines the radar and camera BEV features. For instance-level fusion, we propose a Radar Grid Point Refinement module that reduces localization error by accounting for the characteristics of the radar point clouds. The experiments conducted on the public nuScenes dataset demonstrate that our proposed RCM-Fusion achieves state-of-the-art performances among single frame-based radar-camera fusion methods in the nuScenes 3D object detection benchmark. Code will be made publicly available.
5/17/2024

Multimodal 3D Object Detection on Unseen Domains
Deepti Hegde, Suhas Lohit, Kuan-Chuan Peng, Michael J. Jones, Vishal M. Patel
0
0
LiDAR datasets for autonomous driving exhibit biases in properties such as point cloud density, range, and object dimensions. As a result, object detection networks trained and evaluated in different environments often experience performance degradation. Domain adaptation approaches assume access to unannotated samples from the test distribution to address this problem. However, in the real world, the exact conditions of deployment and access to samples representative of the test dataset may be unavailable while training. We argue that the more realistic and challenging formulation is to require robustness in performance to unseen target domains. We propose to address this problem in a two-pronged manner. First, we leverage paired LiDAR-image data present in most autonomous driving datasets to perform multimodal object detection. We suggest that working with multimodal features by leveraging both images and LiDAR point clouds for scene understanding tasks results in object detectors more robust to unseen domain shifts. Second, we train a 3D object detector to learn multimodal object features across different distributions and promote feature invariance across these source domains to improve generalizability to unseen target domains. To this end, we propose CLIX$^text{3D}$, a multimodal fusion and supervised contrastive learning framework for 3D object detection that performs alignment of object features from same-class samples of different domains while pushing the features from different classes apart. We show that CLIX$^text{3D}$ yields state-of-the-art domain generalization performance under multiple dataset shifts.
4/19/2024
🔎
Timely Fusion of Surround Radar/Lidar for Object Detection in Autonomous Driving Systems
Wenjing Xie, Tao Hu, Neiwen Ling, Guoliang Xing, Chun Jason Xue, Nan Guan
0
0
Fusing Radar and Lidar sensor data can fully utilize their complementary advantages and provide more accurate reconstruction of the surrounding for autonomous driving systems. Surround Radar/Lidar can provide 360-degree view sampling with the minimal cost, which are promising sensing hardware solutions for autonomous driving systems. However, due to the intrinsic physical constraints, the rotating speed of surround Radar, and thus the frequency to generate Radar data frames, is much lower than surround Lidar. Existing Radar/Lidar fusion methods have to work at the low frequency of surround Radar, which cannot meet the high responsiveness requirement of autonomous driving systems.This paper develops techniques to fuse surround Radar/Lidar with working frequency only limited by the faster surround Lidar instead of the slower surround Radar, based on the state-of-the-art object detection model MVDNet. The basic idea of our approach is simple: we let MVDNet work with temporally unaligned data from Radar/Lidar, so that fusion can take place at any time when a new Lidar data frame arrives, instead of waiting for the slow Radar data frame. However, directly applying MVDNet to temporally unaligned Radar/Lidar data greatly degrades its object detection accuracy. The key information revealed in this paper is that we can achieve high output frequency with little accuracy loss by enhancing the training procedure to explore the temporal redundancy in MVDNet so that it can tolerate the temporal unalignment of input data. We explore several different ways of training enhancement and compare them quantitatively with experiments.
5/28/2024