RCM-Fusion: Radar-Camera Multi-Level Fusion for 3D Object Detection
2307.10249
0
0
🔎
Abstract
While LiDAR sensors have been successfully applied to 3D object detection, the affordability of radar and camera sensors has led to a growing interest in fusing radars and cameras for 3D object detection. However, previous radar-camera fusion models were unable to fully utilize the potential of radar information. In this paper, we propose Radar-Camera Multi-level fusion (RCM-Fusion), which attempts to fuse both modalities at both feature and instance levels. For feature-level fusion, we propose a Radar Guided BEV Encoder which transforms camera features into precise BEV representations using the guidance of radar Bird's-Eye-View (BEV) features and combines the radar and camera BEV features. For instance-level fusion, we propose a Radar Grid Point Refinement module that reduces localization error by accounting for the characteristics of the radar point clouds. The experiments conducted on the public nuScenes dataset demonstrate that our proposed RCM-Fusion achieves state-of-the-art performances among single frame-based radar-camera fusion methods in the nuScenes 3D object detection benchmark. Code will be made publicly available.
Create account to get full access
Overview
- LiDAR sensors have been successfully used for 3D object detection, but radar and camera sensors are more affordable
- This has led to growing interest in fusing radar and camera data for 3D object detection
- Previous radar-camera fusion models were unable to fully utilize the potential of radar information
- This paper proposes a new approach called Radar-Camera Multi-level fusion (RCM-Fusion) that fuses both modalities at both feature and instance levels
Plain English Explanation
The paper explores a new way to combine radar and camera data for 3D object detection, which is the process of identifying and localizing objects in 3D space. While 3D object detection has traditionally been done using more expensive LiDAR sensors, the affordability of radar and camera sensors has made them an attractive alternative.
However, previous attempts to fuse radar and camera data for 3D object detection have struggled to fully take advantage of the information provided by radar. This paper introduces a new approach called Radar-Camera Multi-level fusion (RCM-Fusion) that aims to address this limitation.
The key ideas behind RCM-Fusion are:
-
Feature-level Fusion: Transforming the camera's visual features into a top-down "bird's-eye-view" (BEV) representation, and then combining this with the BEV features from the radar data. This allows the model to learn from both modalities at a low level.
-
Instance-level Fusion: Refining the location of detected objects by accounting for the unique characteristics of radar point clouds. Radar data can be less precise than other sensors, so this step helps improve the accuracy of object localization.
By fusing the radar and camera data at both the feature and instance levels, the RCM-Fusion approach is able to more effectively leverage the strengths of each sensor and achieve state-of-the-art performance on the public nuScenes 3D object detection benchmark.
Technical Explanation
The RCM-Fusion approach consists of two key components:
-
Radar Guided BEV Encoder: This module takes the camera's visual features and transforms them into a top-down "bird's-eye-view" (BEV) representation. It uses the BEV features from the radar data as a guide to help the camera features better capture the 3D structure of the scene.
-
Radar Grid Point Refinement: This module refines the localization of detected objects by accounting for the unique characteristics of radar point clouds. Radar data can be less precise than other sensors, so this step helps improve the accuracy of object localization.
The authors evaluate RCM-Fusion on the nuScenes dataset, a large-scale benchmark for 3D object detection that includes synchronized camera and radar data. The experiments show that RCM-Fusion outperforms previous radar-camera fusion methods on this benchmark.
Critical Analysis
The paper presents a compelling approach for fusing radar and camera data to achieve state-of-the-art 3D object detection performance. The authors make a convincing case that previous fusion methods were unable to fully utilize the potential of radar information, and that their proposed RCM-Fusion can address this limitation.
One potential area for further research mentioned in the paper is extending the approach to incorporate additional sensor modalities, such as LiDAR or motion cues from the scene. Integrating more diverse sensor data could potentially lead to even greater improvements in 3D object detection accuracy.
Additionally, the paper focuses on single-frame 3D object detection, but extending the approach to multi-frame fusion could also be an interesting area for future work. Leveraging temporal information could help address some of the limitations of individual sensor modalities.
Overall, the RCM-Fusion approach represents an important step forward in the field of 3D object detection, demonstrating the value of carefully designed sensor fusion techniques. The results on the nuScenes benchmark are impressive, and the open-sourcing of the code will likely spur further research and development in this area.
Conclusion
This paper introduces Radar-Camera Multi-level fusion (RCM-Fusion), a new approach for fusing radar and camera data to achieve state-of-the-art performance in 3D object detection. By combining the modalities at both the feature and instance levels, RCM-Fusion is able to more effectively leverage the strengths of each sensor type.
The results on the nuScenes benchmark demonstrate the potential of this approach, and the open-sourcing of the code will likely lead to further advancements in radar-camera fusion for 3D object detection. As the field continues to evolve, integrating additional sensor modalities and exploiting temporal information could be promising areas for future research.
Overall, this work represents an important contribution to the ongoing effort to develop affordable and accurate 3D object detection systems, with potential applications in autonomous vehicles, robotics, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!BiCo-Fusion: Bidirectional Complementary LiDAR-Camera Fusion for Semantic- and Spatial-Aware 3D Object Detection
Yang Song, Lin Wang
0
0
3D object detection is an important task that has been widely applied in autonomous driving. Recently, fusing multi-modal inputs, i.e., LiDAR and camera data, to perform this task has become a new trend. Existing methods, however, either ignore the sparsity of Lidar features or fail to preserve the original spatial structure of LiDAR and the semantic density of camera features simultaneously due to the modality gap. To address issues, this letter proposes a novel bidirectional complementary Lidar-camera fusion framework, called BiCo-Fusion that can achieve robust semantic- and spatial-aware 3D object detection. The key insight is to mutually fuse the multi-modal features to enhance the semantics of LiDAR features and the spatial awareness of the camera features and adaptatively select features from both modalities to build a unified 3D representation. Specifically, we introduce Pre-Fusion consisting of a Voxel Enhancement Module (VEM) to enhance the semantics of voxel features from 2D camera features and Image Enhancement Module (IEM) to enhance the spatial characteristics of camera features from 3D voxel features. Both VEM and IEM are bidirectionally updated to effectively reduce the modality gap. We then introduce Unified Fusion to adaptively weight to select features from the enchanted Lidar and camera features to build a unified 3D representation. Extensive experiments demonstrate the superiority of our BiCo-Fusion against the prior arts. Project page: https://t-ys.github.io/BiCo-Fusion/.
6/28/2024
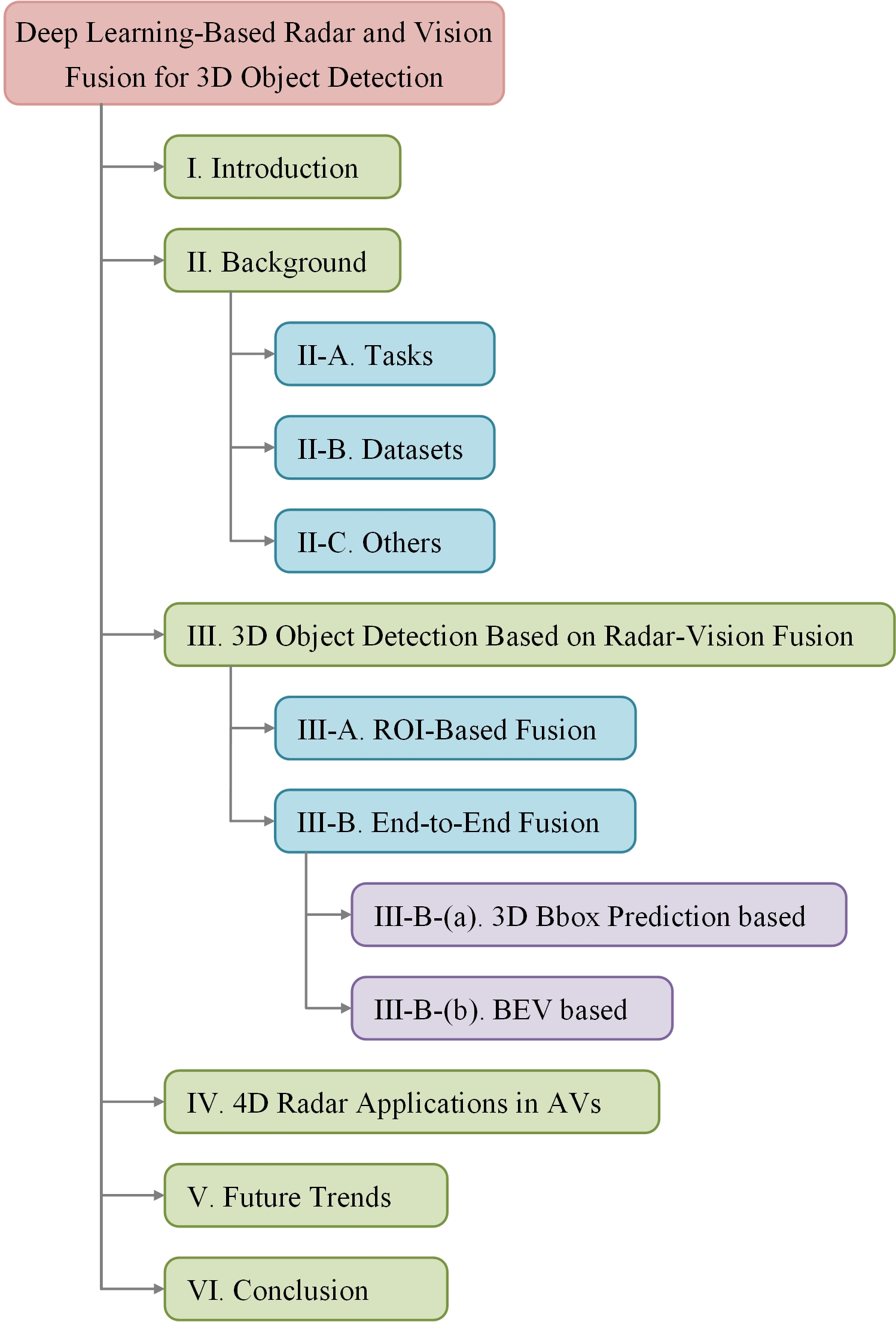
A Survey of Deep Learning Based Radar and Vision Fusion for 3D Object Detection in Autonomous Driving
Di Wu, Feng Yang, Benlian Xu, Pan Liao, Bo Liu
0
0
With the rapid advancement of autonomous driving technology, there is a growing need for enhanced safety and efficiency in the automatic environmental perception of vehicles during their operation. In modern vehicle setups, cameras and mmWave radar (radar), being the most extensively employed sensors, demonstrate complementary characteristics, inherently rendering them conducive to fusion and facilitating the achievement of both robust performance and cost-effectiveness. This paper focuses on a comprehensive survey of radar-vision (RV) fusion based on deep learning methods for 3D object detection in autonomous driving. We offer a comprehensive overview of each RV fusion category, specifically those employing region of interest (ROI) fusion and end-to-end fusion strategies. As the most promising fusion strategy at present, we provide a deeper classification of end-to-end fusion methods, including those 3D bounding box prediction based and BEV based approaches. Moreover, aligning with recent advancements, we delineate the latest information on 4D radar and its cutting-edge applications in autonomous vehicles (AVs). Finally, we present the possible future trends of RV fusion and summarize this paper.
6/4/2024

Cross-Domain Spatial Matching for Camera and Radar Sensor Data Fusion in Autonomous Vehicle Perception System
Daniel Dworak, Mateusz Komorkiewicz, Pawe{l} Skruch, Jerzy Baranowski
0
0
In this paper, we propose a novel approach to address the problem of camera and radar sensor fusion for 3D object detection in autonomous vehicle perception systems. Our approach builds on recent advances in deep learning and leverages the strengths of both sensors to improve object detection performance. Precisely, we extract 2D features from camera images using a state-of-the-art deep learning architecture and then apply a novel Cross-Domain Spatial Matching (CDSM) transformation method to convert these features into 3D space. We then fuse them with extracted radar data using a complementary fusion strategy to produce a final 3D object representation. To demonstrate the effectiveness of our approach, we evaluate it on the NuScenes dataset. We compare our approach to both single-sensor performance and current state-of-the-art fusion methods. Our results show that the proposed approach achieves superior performance over single-sensor solutions and could directly compete with other top-level fusion methods.
4/26/2024

Lift-Attend-Splat: Bird's-eye-view camera-lidar fusion using transformers
James Gunn, Zygmunt Lenyk, Anuj Sharma, Andrea Donati, Alexandru Buburuzan, John Redford, Romain Mueller
0
0
Combining complementary sensor modalities is crucial to providing robust perception for safety-critical robotics applications such as autonomous driving (AD). Recent state-of-the-art camera-lidar fusion methods for AD rely on monocular depth estimation which is a notoriously difficult task compared to using depth information from the lidar directly. Here, we find that this approach does not leverage depth as expected and show that naively improving depth estimation does not lead to improvements in object detection performance. Strikingly, we also find that removing depth estimation altogether does not degrade object detection performance substantially, suggesting that relying on monocular depth could be an unnecessary architectural bottleneck during camera-lidar fusion. In this work, we introduce a novel fusion method that bypasses monocular depth estimation altogether and instead selects and fuses camera and lidar features in a bird's-eye-view grid using a simple attention mechanism. We show that our model can modulate its use of camera features based on the availability of lidar features and that it yields better 3D object detection on the nuScenes dataset than baselines relying on monocular depth estimation.
5/22/2024