Timely Fusion of Surround Radar/Lidar for Object Detection in Autonomous Driving Systems
2309.04806
0
0
🔎
Abstract
Fusing Radar and Lidar sensor data can fully utilize their complementary advantages and provide more accurate reconstruction of the surrounding for autonomous driving systems. Surround Radar/Lidar can provide 360-degree view sampling with the minimal cost, which are promising sensing hardware solutions for autonomous driving systems. However, due to the intrinsic physical constraints, the rotating speed of surround Radar, and thus the frequency to generate Radar data frames, is much lower than surround Lidar. Existing Radar/Lidar fusion methods have to work at the low frequency of surround Radar, which cannot meet the high responsiveness requirement of autonomous driving systems.This paper develops techniques to fuse surround Radar/Lidar with working frequency only limited by the faster surround Lidar instead of the slower surround Radar, based on the state-of-the-art object detection model MVDNet. The basic idea of our approach is simple: we let MVDNet work with temporally unaligned data from Radar/Lidar, so that fusion can take place at any time when a new Lidar data frame arrives, instead of waiting for the slow Radar data frame. However, directly applying MVDNet to temporally unaligned Radar/Lidar data greatly degrades its object detection accuracy. The key information revealed in this paper is that we can achieve high output frequency with little accuracy loss by enhancing the training procedure to explore the temporal redundancy in MVDNet so that it can tolerate the temporal unalignment of input data. We explore several different ways of training enhancement and compare them quantitatively with experiments.
Create account to get full access
Overview
- This paper explores techniques to fuse data from radar and lidar sensors for autonomous driving systems.
- Radar and lidar are complementary sensing technologies that can provide a more complete view of the surrounding environment.
- Existing fusion methods are limited by the slower update rate of radar, which cannot meet the high responsiveness requirements of autonomous driving.
- The proposed approach aims to fuse radar and lidar data at the faster update rate of lidar, without sacrificing detection accuracy.
Plain English Explanation
Autonomous driving systems rely on a variety of sensors, including radar and lidar, to build a detailed understanding of the surrounding environment. Radar and lidar have complementary strengths - radar can detect objects at long range, while lidar provides higher-resolution 3D data. Fusing these sensor modalities can provide a more comprehensive and accurate view of the environment, which is crucial for safe and reliable autonomous driving.
However, due to their underlying technologies, radar and lidar have different update rates. Radar sensors typically update at a much slower rate than lidar, which can be problematic for autonomous driving systems that require fast, responsive decision-making. Existing fusion methods are limited by this mismatch, as they have to work at the slower radar update rate.
The key innovation in this paper is a technique that allows the fusion of radar and lidar data to occur at the faster lidar update rate, without sacrificing detection accuracy. The researchers achieve this by using a state-of-the-art object detection model called MVDNet that can handle temporally unaligned data from the two sensors. This means the model can fuse the data as soon as new lidar frames are available, rather than waiting for the slower radar updates.
To make this work, the researchers enhanced the training process of MVDNet to help it tolerate the temporal misalignment between the radar and lidar data. This allows the model to maintain high detection accuracy even when working with data that is not perfectly synchronized.
Technical Explanation
The paper proposes a technique to fuse data from surround radar and lidar sensors for autonomous driving applications. Surround radar and lidar provide a 360-degree view of the environment, which is essential for autonomous driving. However, due to physical constraints, the update rate of surround radar is much slower than that of surround lidar.
Existing radar/lidar fusion methods are limited by this mismatch in update rates, as they have to operate at the slower radar frequency. This cannot meet the high responsiveness requirements of autonomous driving systems. The key idea in this paper is to fuse the radar and lidar data at the faster lidar update rate, without compromising detection accuracy.
The researchers achieve this by using the MVDNet object detection model, which can handle temporally unaligned radar and lidar data. This means the fusion can occur as soon as new lidar frames are available, rather than waiting for the slower radar updates. However, directly applying MVDNet to temporally unaligned data leads to a significant degradation in detection accuracy.
To address this, the researchers enhance the training procedure of MVDNet to help the model tolerate the temporal misalignment between the radar and lidar inputs. They explore several different training enhancements and evaluate them quantitatively through experiments.
Critical Analysis
The proposed approach represents a significant advance in the field of sensor fusion for autonomous driving, as it addresses a key limitation of existing methods. By enabling the fusion of radar and lidar data at the faster lidar update rate, the system can meet the high responsiveness requirements of autonomous driving without sacrificing detection accuracy.
However, the paper does not provide a comprehensive analysis of the limitations and potential issues with the proposed approach. For example, it would be valuable to understand the performance of the system in challenging environmental conditions, such as inclement weather or complex urban scenarios, where the strengths and weaknesses of radar and lidar may become more pronounced.
Additionally, the paper does not discuss the computational overhead of the enhanced MVDNet model or the potential implications for real-time processing in an autonomous driving system. It would be helpful to understand the tradeoffs between the improved fusion performance and the increased computational requirements.
Further research could also explore the generalization of the proposed techniques to other sensor modalities or object detection models, as well as the potential for end-to-end optimization of the entire sensor fusion pipeline.
Conclusion
This paper presents a novel approach to fusing radar and lidar data for autonomous driving systems, which overcomes the limitations of existing fusion methods. By enhancing the training of the state-of-the-art MVDNet object detection model, the researchers have developed a technique that can fuse the sensor data at the faster lidar update rate, without sacrificing detection accuracy.
This innovation has the potential to significantly improve the responsiveness and reliability of autonomous driving systems, as it allows them to leverage the complementary strengths of radar and lidar sensors more effectively. The insights and techniques presented in this paper could also inspire further advancements in sensor fusion for a wide range of applications beyond autonomous driving, such as multi-object tracking and robotic perception.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
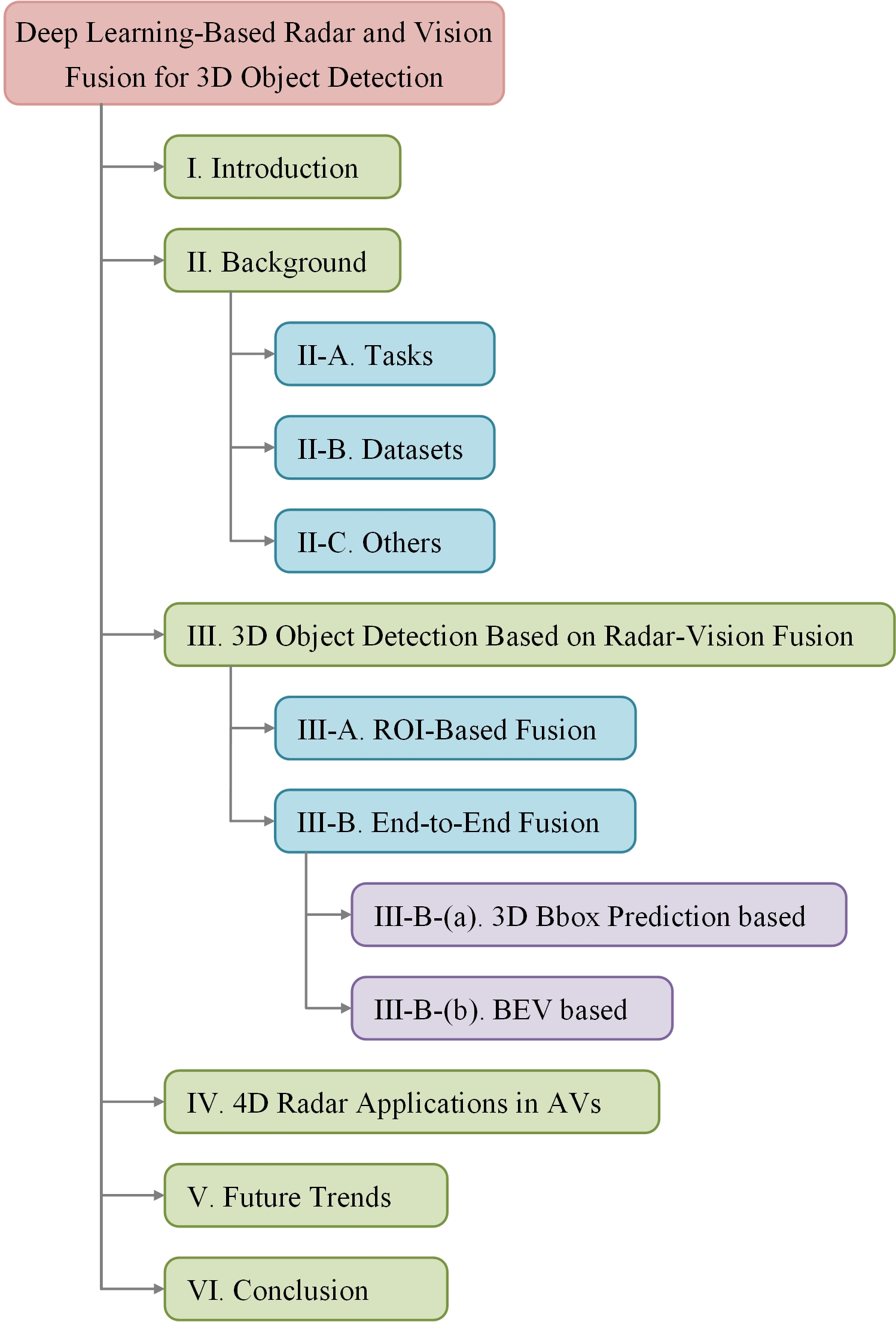
A Survey of Deep Learning Based Radar and Vision Fusion for 3D Object Detection in Autonomous Driving
Di Wu, Feng Yang, Benlian Xu, Pan Liao, Bo Liu
0
0
With the rapid advancement of autonomous driving technology, there is a growing need for enhanced safety and efficiency in the automatic environmental perception of vehicles during their operation. In modern vehicle setups, cameras and mmWave radar (radar), being the most extensively employed sensors, demonstrate complementary characteristics, inherently rendering them conducive to fusion and facilitating the achievement of both robust performance and cost-effectiveness. This paper focuses on a comprehensive survey of radar-vision (RV) fusion based on deep learning methods for 3D object detection in autonomous driving. We offer a comprehensive overview of each RV fusion category, specifically those employing region of interest (ROI) fusion and end-to-end fusion strategies. As the most promising fusion strategy at present, we provide a deeper classification of end-to-end fusion methods, including those 3D bounding box prediction based and BEV based approaches. Moreover, aligning with recent advancements, we delineate the latest information on 4D radar and its cutting-edge applications in autonomous vehicles (AVs). Finally, we present the possible future trends of RV fusion and summarize this paper.
6/4/2024

Lift-Attend-Splat: Bird's-eye-view camera-lidar fusion using transformers
James Gunn, Zygmunt Lenyk, Anuj Sharma, Andrea Donati, Alexandru Buburuzan, John Redford, Romain Mueller
0
0
Combining complementary sensor modalities is crucial to providing robust perception for safety-critical robotics applications such as autonomous driving (AD). Recent state-of-the-art camera-lidar fusion methods for AD rely on monocular depth estimation which is a notoriously difficult task compared to using depth information from the lidar directly. Here, we find that this approach does not leverage depth as expected and show that naively improving depth estimation does not lead to improvements in object detection performance. Strikingly, we also find that removing depth estimation altogether does not degrade object detection performance substantially, suggesting that relying on monocular depth could be an unnecessary architectural bottleneck during camera-lidar fusion. In this work, we introduce a novel fusion method that bypasses monocular depth estimation altogether and instead selects and fuses camera and lidar features in a bird's-eye-view grid using a simple attention mechanism. We show that our model can modulate its use of camera features based on the availability of lidar features and that it yields better 3D object detection on the nuScenes dataset than baselines relying on monocular depth estimation.
5/22/2024
🔎
Multi-Object Tracking based on Imaging Radar 3D Object Detection
Patrick Palmer, Martin Kruger, Richard Altendorfer, Torsten Bertram
0
0
Effective tracking of surrounding traffic participants allows for an accurate state estimation as a necessary ingredient for prediction of future behavior and therefore adequate planning of the ego vehicle trajectory. One approach for detecting and tracking surrounding traffic participants is the combination of a learning based object detector with a classical tracking algorithm. Learning based object detectors have been shown to work adequately on lidar and camera data, while learning based object detectors using standard radar data input have proven to be inferior. Recently, with the improvements to radar sensor technology in the form of imaging radars, the object detection performance on radar was greatly improved but is still limited compared to lidar sensors due to the sparsity of the radar point cloud. This presents a unique challenge for the task of multi-object tracking. The tracking algorithm must overcome the limited detection quality while generating consistent tracks. To this end, a comparison between different multi-object tracking methods on imaging radar data is required to investigate its potential for downstream tasks. The work at hand compares multiple approaches and analyzes their limitations when applied to imaging radar data. Furthermore, enhancements to the presented approaches in the form of probabilistic association algorithms are considered for this task.
6/4/2024

Cross-Domain Spatial Matching for Camera and Radar Sensor Data Fusion in Autonomous Vehicle Perception System
Daniel Dworak, Mateusz Komorkiewicz, Pawe{l} Skruch, Jerzy Baranowski
0
0
In this paper, we propose a novel approach to address the problem of camera and radar sensor fusion for 3D object detection in autonomous vehicle perception systems. Our approach builds on recent advances in deep learning and leverages the strengths of both sensors to improve object detection performance. Precisely, we extract 2D features from camera images using a state-of-the-art deep learning architecture and then apply a novel Cross-Domain Spatial Matching (CDSM) transformation method to convert these features into 3D space. We then fuse them with extracted radar data using a complementary fusion strategy to produce a final 3D object representation. To demonstrate the effectiveness of our approach, we evaluate it on the NuScenes dataset. We compare our approach to both single-sensor performance and current state-of-the-art fusion methods. Our results show that the proposed approach achieves superior performance over single-sensor solutions and could directly compete with other top-level fusion methods.
4/26/2024