Cross-Layer Feature Pyramid Transformer for Small Object Detection in Aerial Images

0
Sign in to get full access
Overview
- This paper proposes a novel "Cross-Layer Feature Pyramid Transformer" (CLFPT) architecture for small object detection in aerial images.
- The key innovations include a cross-layer feature pyramid and a vision transformer-based object detection head.
- The CLFPT model achieves state-of-the-art performance on several aerial image object detection benchmarks.
Plain English Explanation
The paper focuses on the challenge of detecting small objects in aerial images, such as cars, buildings, or people. This is an important task for applications like urban planning, disaster response, and autonomous vehicles.
The researchers developed a new deep learning model called the "Cross-Layer Feature Pyramid Transformer" (CLFPT). This model has two main components:
-
Cross-Layer Feature Pyramid: This part of the model takes the features extracted from different layers of a neural network and combines them in a smart way. This allows the model to capture both detailed local information and broader contextual information, which is crucial for detecting small objects.
-
Vision Transformer Object Detection Head: Instead of using a traditional convolutional neural network for object detection, the researchers used a transformer-based architecture. Transformers are a type of neural network that is particularly good at processing and understanding sequence data, like the spatial relationships in an image.
By using these novel components, the CLFPT model was able to outperform other state-of-the-art object detection models on several aerial image datasets. This suggests that the cross-layer feature pyramid and transformer-based detection head are effective techniques for identifying small objects in aerial imagery.
Technical Explanation
The paper proposes the Cross-Layer Feature Pyramid Transformer (CLFPT) architecture for small object detection in aerial images. The key innovations are:
-
Cross-Layer Feature Pyramid: The model extracts features from multiple layers of a backbone convolutional neural network (e.g., ResNet). These features, which capture information at different scales, are then combined using a series of feature pyramid network (FPN) modules. This allows the model to effectively fuse low-level detailed features and high-level contextual features, enabling robust detection of small objects.
-
Vision Transformer Object Detection Head: Instead of using a traditional convolutional neural network for the object detection head, the researchers employ a vision transformer (ViT) architecture. The ViT module takes the fused feature maps from the cross-layer FPN and processes them using self-attention mechanisms, which are particularly effective at modeling spatial relationships in image data.
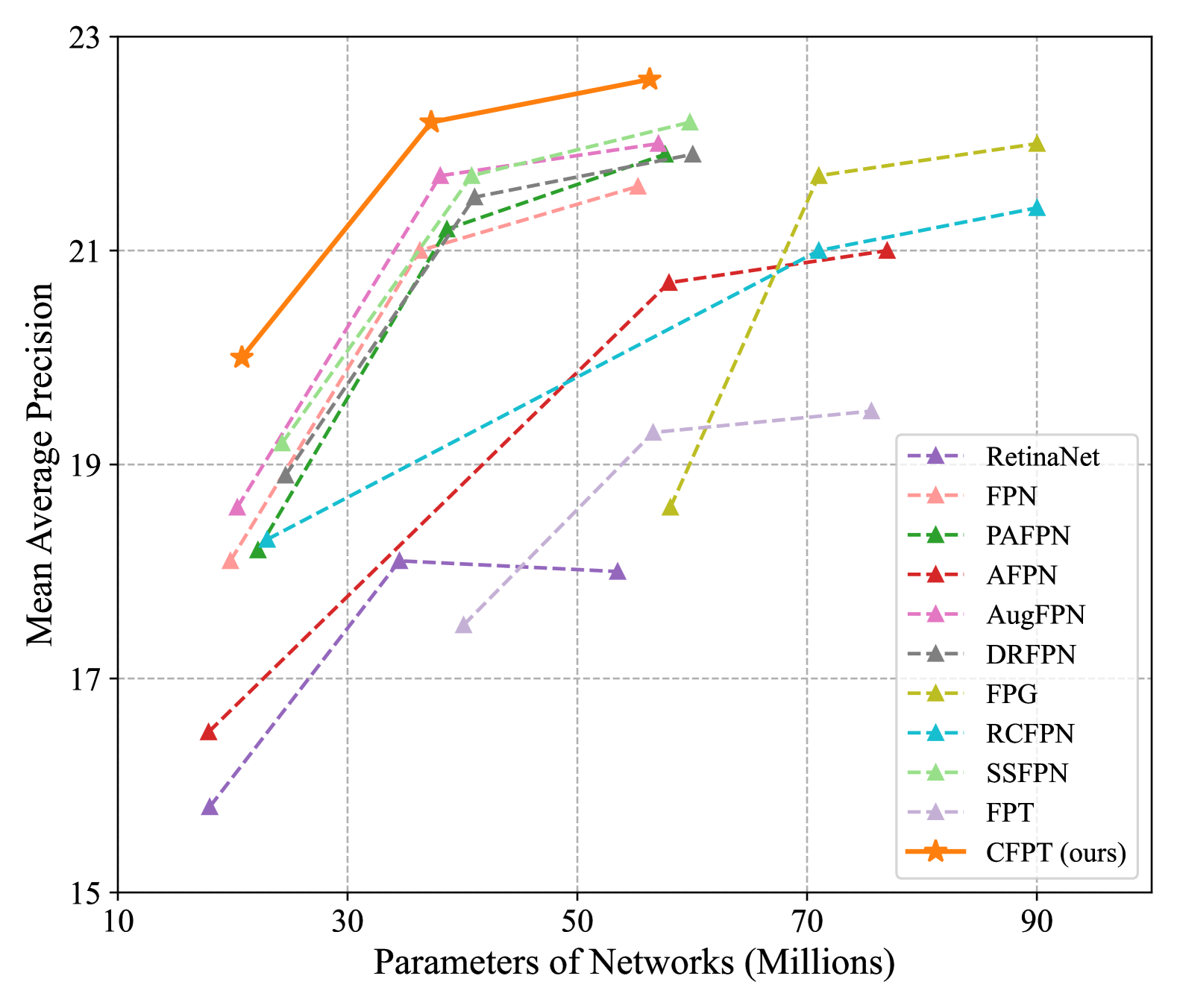
The CLFPT model is evaluated on several aerial image object detection benchmarks, including DOTA, UCAS-AOD, and HRSC2016. The experiments demonstrate that CLFPT outperforms other state-of-the-art object detection models, particularly for the task of detecting small objects.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach for small object detection in aerial imagery. The key strengths of the CLFPT model are:
- The cross-layer feature pyramid effectively combines low-level and high-level features, which is crucial for detecting small objects.
- The vision transformer-based detection head is a novel and promising approach for object detection, as it can better capture the spatial relationships in the input image.
- The model achieves state-of-the-art performance on several challenging aerial image benchmarks.
However, the paper also acknowledges some limitations and areas for future research:
- The computational complexity of the transformer-based detection head may be higher than traditional convolutional approaches, which could impact inference speed.
- The paper does not explore the impact of different backbone networks or various transformer architectures on the overall performance.
- The dataset-specific nature of the results suggests that further research is needed to understand the broader applicability of the CLFPT model.
Overall, the CLFPT model represents an interesting and effective approach to the problem of small object detection in aerial imagery, with several promising research directions for the future.
Conclusion
This paper presents the Cross-Layer Feature Pyramid Transformer (CLFPT) architecture, a novel deep learning model for small object detection in aerial images. The key innovations include a cross-layer feature pyramid and a vision transformer-based object detection head, which together enable the model to effectively capture both local and contextual information for accurately identifying small objects.
The experimental results demonstrate that CLFPT outperforms other state-of-the-art object detection models on several aerial image benchmarks, particularly for the task of detecting small objects. While the paper acknowledges some limitations, the CLFPT model represents an important step forward in the field of aerial image object detection and suggests promising avenues for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-Layer Feature Pyramid Transformer for Small Object Detection in Aerial Images
Zewen Du, Zhenjiang Hu, Guiyu Zhao, Ying Jin, Hongbin Ma
Object detection in aerial images has always been a challenging task due to the generally small size of the objects. Most current detectors prioritize novel detection frameworks, often overlooking research on fundamental components such as feature pyramid networks. In this paper, we introduce the Cross-Layer Feature Pyramid Transformer (CFPT), a novel upsampler-free feature pyramid network designed specifically for small object detection in aerial images. CFPT incorporates two meticulously designed attention blocks with linear computational complexity: the Cross-Layer Channel-Wise Attention (CCA) and the Cross-Layer Spatial-Wise Attention (CSA). CCA achieves cross-layer interaction by dividing channel-wise token groups to perceive cross-layer global information along the spatial dimension, while CSA completes cross-layer interaction by dividing spatial-wise token groups to perceive cross-layer global information along the channel dimension. By integrating these modules, CFPT enables cross-layer interaction in one step, thereby avoiding the semantic gap and information loss associated with element-wise summation and layer-by-layer transmission. Furthermore, CFPT incorporates global contextual information, which enhances detection performance for small objects. To further enhance location awareness during cross-layer interaction, we propose the Cross-Layer Consistent Relative Positional Encoding (CCPE) based on inter-layer mutual receptive fields. We evaluate the effectiveness of CFPT on two challenging object detection datasets in aerial images, namely VisDrone2019-DET and TinyPerson. Extensive experiments demonstrate the effectiveness of CFPT, which outperforms state-of-the-art feature pyramid networks while incurring lower computational costs. The code will be released at https://github.com/duzw9311/CFPT.
Read more7/30/2024

0
LR-FPN: Enhancing Remote Sensing Object Detection with Location Refined Feature Pyramid Network
Hanqian Li, Ruinan Zhang, Ye Pan, Junchi Ren, Fei Shen
Remote sensing target detection aims to identify and locate critical targets within remote sensing images, finding extensive applications in agriculture and urban planning. Feature pyramid networks (FPNs) are commonly used to extract multi-scale features. However, existing FPNs often overlook extracting low-level positional information and fine-grained context interaction. To address this, we propose a novel location refined feature pyramid network (LR-FPN) to enhance the extraction of shallow positional information and facilitate fine-grained context interaction. The LR-FPN consists of two primary modules: the shallow position information extraction module (SPIEM) and the contextual interaction module (CIM). Specifically, SPIEM first maximizes the retention of solid location information of the target by simultaneously extracting positional and saliency information from the low-level feature map. Subsequently, CIM injects this robust location information into different layers of the original FPN through spatial and channel interaction, explicitly enhancing the object area. Moreover, in spatial interaction, we introduce a simple local and non-local interaction strategy to learn and retain the saliency information of the object. Lastly, the LR-FPN can be readily integrated into common object detection frameworks to improve performance significantly. Extensive experiments on two large-scale remote sensing datasets (i.e., DOTAV1.0 and HRSC2016) demonstrate that the proposed LR-FPN is superior to state-of-the-art object detection approaches. Our code and models will be publicly available.
Read more4/3/2024

0
Relating CNN-Transformer Fusion Network for Change Detection
Yuhao Gao, Gensheng Pei, Mengmeng Sheng, Zeren Sun, Tao Chen, Yazhou Yao
While deep learning, particularly convolutional neural networks (CNNs), has revolutionized remote sensing (RS) change detection (CD), existing approaches often miss crucial features due to neglecting global context and incomplete change learning. Additionally, transformer networks struggle with low-level details. RCTNet addresses these limitations by introducing textbf{(1)} an early fusion backbone to exploit both spatial and temporal features early on, textbf{(2)} a Cross-Stage Aggregation (CSA) module for enhanced temporal representation, textbf{(3)} a Multi-Scale Feature Fusion (MSF) module for enriched feature extraction in the decoder, and textbf{(4)} an Efficient Self-deciphering Attention (ESA) module utilizing transformers to capture global information and fine-grained details for accurate change detection. Extensive experiments demonstrate RCTNet's clear superiority over traditional RS image CD methods, showing significant improvement and an optimal balance between accuracy and computational cost.
Read more7/4/2024

0
Multi-scale Feature Fusion with Point Pyramid for 3D Object Detection
Weihao Lu, Dezong Zhao, Cristiano Premebida, Li Zhang, Wenjing Zhao, Daxin Tian
Effective point cloud processing is crucial to LiDARbased autonomous driving systems. The capability to understand features at multiple scales is required for object detection of intelligent vehicles, where road users may appear in different sizes. Recent methods focus on the design of the feature aggregation operators, which collect features at different scales from the encoder backbone and assign them to the points of interest. While efforts are made into the aggregation modules, the importance of how to fuse these multi-scale features has been overlooked. This leads to insufficient feature communication across scales. To address this issue, this paper proposes the Point Pyramid RCNN (POP-RCNN), a feature pyramid-based framework for 3D object detection on point clouds. POP-RCNN consists of a Point Pyramid Feature Enhancement (PPFE) module to establish connections across spatial scales and semantic depths for information exchange. The PPFE module effectively fuses multi-scale features for rich information without the increased complexity in feature aggregation. To remedy the impact of inconsistent point densities, a point density confidence module is deployed. This design integration enables the use of a lightweight feature aggregator, and the emphasis on both shallow and deep semantics, realising a detection framework for 3D object detection. With great adaptability, the proposed method can be applied to a variety of existing frameworks to increase feature richness, especially for long-distance detection. By adopting the PPFE in the voxel-based and point-voxel-based baselines, experimental results on KITTI and Waymo Open Dataset show that the proposed method achieves remarkable performance even with limited computational headroom.
Read more9/10/2024