Cross-lingual Human-Preference Alignment for Neural Machine Translation with Direct Quality Optimization

0
🧠
Sign in to get full access
Overview
- Cross-lingual human-preference alignment for neural machine translation (NMT) with direct quality optimization
- Task-data mismatch in NMT and how to address it
- Importance of aligning NMT models with human preferences for high-quality translations
Plain English Explanation
Neural machine translation (NMT) models are trained on large datasets of translated text, but this data may not always align with what humans actually prefer in translations. This "task-data mismatch" can lead to NMT models producing translations that are technically correct but don't meet human expectations.
To address this, the researchers in this paper propose a method for directly optimizing NMT models to match human preferences, rather than just optimizing for accuracy on the training data. This involves having humans provide feedback on the quality of translations, and then using that feedback to fine-tune the NMT model to produce translations that better align with human preferences.
The key insight is that by directly optimizing the model for human-preferred translations, rather than just the original training data, the resulting translations will be higher quality and more useful in real-world applications. This could have significant implications for improving the usability and impact of machine translation systems.
Technical Explanation
The researchers first identify the "task-data mismatch" as a key challenge in NMT - the fact that the training data used to build NMT models may not fully capture the nuances of what humans actually prefer in translation quality. To address this, they propose a direct quality optimization approach, where the NMT model is fine-tuned using human feedback on the quality of translations.
Specifically, the researchers collect human ratings of translation quality, and then use this human preference data to fine-tune the NMT model, optimizing it to produce translations that better align with human preferences. This is in contrast to the typical approach of just optimizing the model for accuracy on the original training data.
The experiments demonstrate that this direct quality optimization leads to significant improvements in translation quality as judged by human raters, across multiple language pairs. The researchers also show that this approach leads to better alignment between the model's outputs and human preferences, compared to models trained solely on the original data.
Critical Analysis
The researchers acknowledge several key limitations and areas for future work:
- The human preference data used for fine-tuning is still relatively limited in scope, and may not fully capture the diversity of human translation preferences.
- The direct quality optimization approach relies on the availability of human raters, which can be costly and time-consuming to scale.
- It's unclear how well this approach would generalize to low-resource language pairs with limited training data.
Additionally, while the results are promising, there may be other ways to address the task-data mismatch beyond just direct preference optimization. For example, incorporating more diverse training data sources or developing better unsupervised adaptation techniques could also help align NMT models with human preferences.
Overall, the researchers have made an important contribution by highlighting the task-data mismatch and proposing a novel approach to address it. However, further research is needed to fully understand the limitations and potential of this direct quality optimization methodology.
Conclusion
This paper presents a novel approach for aligning neural machine translation models with human preferences, rather than just optimizing for accuracy on the original training data. By fine-tuning the NMT model using human feedback on translation quality, the researchers demonstrate significant improvements in the perceived quality and usefulness of the translations.
While there are still some limitations and open questions, this work highlights the importance of considering human preferences in the design and optimization of NMT systems. As machine translation becomes more widely deployed, ensuring the resulting translations meet human needs and expectations will be crucial for achieving widespread adoption and real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Cross-lingual Human-Preference Alignment for Neural Machine Translation with Direct Quality Optimization
Kaden Uhlig, Joern Wuebker, Raphael Reinauer, John DeNero
Reinforcement Learning from Human Feedback (RLHF) and derivative techniques like Direct Preference Optimization (DPO) are task-alignment algorithms used to repurpose general, foundational models for specific tasks. We show that applying task-alignment to neural machine translation (NMT) addresses an existing task--data mismatch in NMT, leading to improvements across all languages of a multilingual model, even when task-alignment is only applied to a subset of those languages. We do so by introducing Direct Quality Optimization (DQO), a variant of DPO leveraging a pre-trained translation quality estimation model as a proxy for human preferences, and verify the improvements with both automatic metrics and human evaluation.
Read more9/27/2024

0
New Desiderata for Direct Preference Optimization
Xiangkun Hu, Tong He, David Wipf
Large language models in the past have typically relied on some form of reinforcement learning with human feedback (RLHF) to better align model responses with human preferences. However, because of oft-observed instabilities when implementing these RLHF pipelines, various reparameterization techniques have recently been introduced to sidestep the need for separately learning an RL reward model. Instead, directly fine-tuning for human preferences is achieved via the minimization of a single closed-form training objective, a process originally referred to as direct preference optimization (DPO) and followed by several notable descendants. Although effective in certain real-world settings, we introduce new evaluation criteria that serve to highlight unresolved shortcomings in the ability of existing DPO methods to interpolate between a pre-trained reference model and empirical measures of human preferences, as well as unavoidable trade-offs in how low- and high-quality responses are regularized and constraints are handled. Our insights then motivate an alternative DPO-like loss that provably mitigates these limitations. Empirical results serve to corroborate notable aspects of our analyses.
Read more7/15/2024
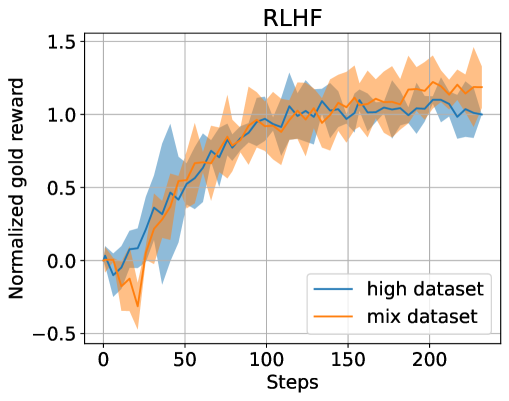
0
Filtered Direct Preference Optimization
Tetsuro Morimura, Mitsuki Sakamoto, Yuu Jinnai, Kenshi Abe, Kaito Ariu
Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on direct preference optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
Read more7/8/2024

0
Direct Alignment of Language Models via Quality-Aware Self-Refinement
Runsheng Yu, Yong Wang, Xiaoqi Jiao, Youzhi Zhang, James T. Kwok
Reinforcement Learning from Human Feedback (RLHF) has been commonly used to align the behaviors of Large Language Models (LLMs) with human preferences. Recently, a popular alternative is Direct Policy Optimization (DPO), which replaces an LLM-based reward model with the policy itself, thus obviating the need for extra memory and training time to learn the reward model. However, DPO does not consider the relative qualities of the positive and negative responses, and can lead to sub-optimal training outcomes. To alleviate this problem, we investigate the use of intrinsic knowledge within the on-the-fly fine-tuning LLM to obtain relative qualities and help to refine the loss function. Specifically, we leverage the knowledge of the LLM to design a refinement function to estimate the quality of both the positive and negative responses. We show that the constructed refinement function can help self-refine the loss function under mild assumptions. The refinement function is integrated into DPO and its variant Identity Policy Optimization (IPO). Experiments across various evaluators indicate that they can improve the performance of the fine-tuned models over DPO and IPO.
Read more6/3/2024