New Desiderata for Direct Preference Optimization

0

Sign in to get full access
Overview
- Introduces new desiderata, or design principles, for directly optimizing preferences in machine learning models
- Focuses on addressing unobserved preference heterogeneity, where individual preferences are not fully observed
- Proposes a framework for incorporating these desiderata into preference optimization algorithms
Plain English Explanation
The paper explores ways to improve how machine learning models optimize for user preferences. Often, models can only partially observe or understand a user's true preferences. This is known as "unobserved preference heterogeneity."
The researchers suggest a set of new design principles, or "desiderata," to address this challenge. These principles aim to help models better capture and represent the full range of user preferences, even when they're not fully observed.
By incorporating these desiderata into preference optimization algorithms, the models can potentially make better decisions that align more closely with each individual user's preferences. This could lead to more personalized and satisfying experiences when using AI-powered systems.
The paper lays the groundwork for developing new preference optimization techniques that are more robust to unobserved preference heterogeneity. This is an important step towards creating AI systems that can truly understand and cater to the diverse needs and preferences of their users.
Technical Explanation
The paper introduces a set of new desiderata, or design principles, for directly optimizing user preferences in machine learning models. The focus is on addressing the challenge of "unobserved preference heterogeneity," where individual preferences are not fully observed by the model.
The key desiderata proposed include:
- Filtered Direct Preference Optimization: Accounting for limitations in the model's ability to observe preferences
- Hybrid Preference Optimization: Combining direct preference optimization with other techniques like inverse reinforcement learning
- Direct Alignment with Language Models: Aligning model outputs directly with user preferences expressed in natural language
- Active Preference Learning: Actively querying users to better understand their preferences
The paper provides a framework for incorporating these desiderata into preference optimization algorithms. This could lead to models that are more robust to unobserved preference heterogeneity and better able to personalize their outputs to individual users.
Critical Analysis
The paper provides a thoughtful set of design principles for improving preference optimization in machine learning, particularly in the face of unobserved preference heterogeneity. However, some potential limitations and areas for further research are:
- The proposed desiderata are still conceptual and would need to be carefully implemented and evaluated in practice. Their real-world impact remains to be seen.
- Actively querying users (as in the "Active Preference Learning" desideratum) could potentially be burdensome or intrusive, and the tradeoffs would need to be carefully considered.
- The paper does not address potential issues around fairness, bias, or transparency that could arise when optimizing for individual preferences in sensitive domains.
Overall, the paper lays important groundwork for advancing preference optimization in machine learning. Continued research and careful consideration of the practical implications will be crucial as these techniques are developed further.
Conclusion
This paper introduces a set of new desiderata, or design principles, to guide the development of machine learning models that can more effectively optimize for user preferences, even when those preferences are not fully observed.
By incorporating ideas like filtered direct preference optimization, hybrid preference optimization, direct alignment with language models, and active preference learning, the researchers aim to create models that are more robust to the challenge of unobserved preference heterogeneity.
Ultimately, these advances could lead to AI systems that are better able to personalize their outputs and decisions to the unique needs and preferences of individual users. This is an important step towards building more trustworthy and user-centric AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New Desiderata for Direct Preference Optimization
Xiangkun Hu, Tong He, David Wipf
Large language models in the past have typically relied on some form of reinforcement learning with human feedback (RLHF) to better align model responses with human preferences. However, because of oft-observed instabilities when implementing these RLHF pipelines, various reparameterization techniques have recently been introduced to sidestep the need for separately learning an RL reward model. Instead, directly fine-tuning for human preferences is achieved via the minimization of a single closed-form training objective, a process originally referred to as direct preference optimization (DPO) and followed by several notable descendants. Although effective in certain real-world settings, we introduce new evaluation criteria that serve to highlight unresolved shortcomings in the ability of existing DPO methods to interpolate between a pre-trained reference model and empirical measures of human preferences, as well as unavoidable trade-offs in how low- and high-quality responses are regularized and constraints are handled. Our insights then motivate an alternative DPO-like loss that provably mitigates these limitations. Empirical results serve to corroborate notable aspects of our analyses.
Read more7/15/2024

0
Direct Preference Optimization With Unobserved Preference Heterogeneity
Keertana Chidambaram, Karthik Vinay Seetharaman, Vasilis Syrgkanis
RLHF has emerged as a pivotal step in aligning language models with human objectives and values. It typically involves learning a reward model from human preference data and then using reinforcement learning to update the generative model accordingly. Conversely, Direct Preference Optimization (DPO) directly optimizes the generative model with preference data, skipping reinforcement learning. However, both RLHF and DPO assume uniform preferences, overlooking the reality of diverse human annotators. This paper presents a new method to align generative models with varied human preferences. We propose an Expectation-Maximization adaptation to DPO, generating a mixture of models based on latent preference types of the annotators. We then introduce a min-max regret ensemble learning model to produce a single generative method to minimize worst-case regret among annotator subgroups with similar latent factors. Our algorithms leverage the simplicity of DPO while accommodating diverse preferences. Experimental results validate the effectiveness of our approach in producing equitable generative policies.
Read more5/27/2024
💬
4
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
Read more7/31/2024
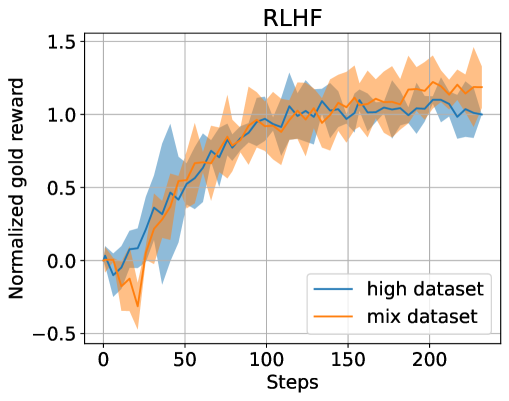
0
Filtered Direct Preference Optimization
Tetsuro Morimura, Mitsuki Sakamoto, Yuu Jinnai, Kenshi Abe, Kaito Ariu
Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on direct preference optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
Read more7/8/2024