Cross-Modal Augmentation for Few-Shot Multimodal Fake News Detection

0

Sign in to get full access
Overview
- This paper explores a cross-modal augmentation approach to improve few-shot multimodal fake news detection.
- The researchers propose a method to generate synthetic multimodal samples by combining text and image data to augment the training dataset.
- The goal is to enhance the model's ability to accurately detect fake news articles using both textual and visual information, even with limited training data.
Plain English Explanation
The paper focuses on the challenge of detecting fake news, which is a growing problem in the digital age. Fake news can spread quickly online and have real-world consequences, so being able to accurately identify it is important. However, training machine learning models to detect fake news can be difficult, especially when there is limited labeled data available.
To address this, the researchers developed a technique called "cross-modal augmentation." The idea is to generate new, realistic-looking fake news samples by combining text and images from real news articles. This is similar to how some AI models can generate synthetic images or text.
By having more training data, the model can learn the patterns and characteristics of fake news more effectively. Even with a small initial dataset, the cross-modal augmentation approach allows the model to "see" more examples and improve its ability to detect fake news articles, including those containing both text and images.
The researchers tested their approach on several benchmark datasets and found that it outperformed other methods, especially when there was limited training data available. This suggests that cross-modal augmentation could be a valuable technique for building accurate fake news detection systems, even in situations where labeled data is scarce.
Technical Explanation
The paper proposes a cross-modal augmentation approach to improve few-shot multimodal fake news detection. The key idea is to generate synthetic multimodal samples by combining text and image data from real news articles to augment the training dataset.
The researchers developed a cross-modal generative adversarial network (CM-GAN) architecture to generate these synthetic samples. The generator takes in a real news article text and a random noise vector, and outputs a corresponding fake image. Simultaneously, the discriminator tries to classify the generated images as real or fake.
By training this CM-GAN model, the researchers were able to produce realistic-looking fake news images that match the textual content. They then combined these synthetic images with the original text to create augmented multimodal training samples.
The augmented dataset was then used to fine-tune a multimodal fake news detection model, which takes both the text and image as input and predicts whether the article is real or fake. The researchers evaluated this approach on several benchmark datasets and found that it outperformed other few-shot learning and data augmentation techniques, especially when the initial training dataset was small.
The cross-modal augmentation approach is similar to techniques used in other multimodal AI models, such as those that fuse text and image data dynamically. It allows the model to "see" more diverse examples of fake news, even with limited labeled data, which improves its generalization and performance.
Critical Analysis
The paper makes a compelling case for the effectiveness of cross-modal augmentation in few-shot multimodal fake news detection. However, there are a few potential limitations and areas for further research:
-
The quality and realism of the generated synthetic samples are crucial for the approach to be effective. While the researchers demonstrate promising results, there may still be room for improvement in the generation quality.
-
The paper focuses on text and image modalities, but real-world fake news may involve other data types, such as audio or video. Extending the cross-modal augmentation approach to handle more diverse inputs could be an important next step.
-
The evaluation is limited to specific benchmark datasets, and the researchers acknowledge that more diverse real-world testing is needed to fully understand the approach's strengths and limitations.
-
There are still open questions around the interpretability and transparency of deep learning-based fake news detection systems. Investigating ways to make the model's decision-making process more explainable could be valuable.
Overall, the cross-modal augmentation technique presented in this paper is a promising approach for improving few-shot multimodal fake news detection. Further research and development in this area could lead to more robust and reliable systems for combating the spread of misinformation online.
Conclusion
This paper introduces a cross-modal augmentation method to enhance few-shot multimodal fake news detection. By generating synthetic multimodal samples that combine text and image data, the researchers were able to improve the performance of fake news detection models, even when limited labeled training data was available.
The results suggest that cross-modal augmentation could be a valuable tool for building accurate and generalizable fake news detection systems. As the problem of misinformation continues to grow, techniques like this that can leverage multimodal data and adapt to limited training scenarios may become increasingly important. Further research and real-world testing could help unlock the full potential of this approach and its applications in the fight against fake news.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-Modal Augmentation for Few-Shot Multimodal Fake News Detection
Ye Jiang, Taihang Wang, Xiaoman Xu, Yimin Wang, Xingyi Song, Diana Maynard
The nascent topic of fake news requires automatic detection methods to quickly learn from limited annotated samples. Therefore, the capacity to rapidly acquire proficiency in a new task with limited guidance, also known as few-shot learning, is critical for detecting fake news in its early stages. Existing approaches either involve fine-tuning pre-trained language models which come with a large number of parameters, or training a complex neural network from scratch with large-scale annotated datasets. This paper presents a multimodal fake news detection model which augments multimodal features using unimodal features. For this purpose, we introduce Cross-Modal Augmentation (CMA), a simple approach for enhancing few-shot multimodal fake news detection by transforming n-shot classification into a more robust (n $times$ z)-shot problem, where z represents the number of supplementary features. The proposed CMA achieves SOTA results over three benchmark datasets, utilizing a surprisingly simple linear probing method to classify multimodal fake news with only a few training samples. Furthermore, our method is significantly more lightweight than prior approaches, particularly in terms of the number of trainable parameters and epoch times. The code is available here: url{https://github.com/zgjiangtoby/FND_fewshot}
Read more7/19/2024
📊
0
Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models
Zhiqiu Lin, Samuel Yu, Zhiyi Kuang, Deepak Pathak, Deva Ramanan
The ability to quickly learn a new task with minimal instruction - known as few-shot learning - is a central aspect of intelligent agents. Classical few-shot benchmarks make use of few-shot samples from a single modality, but such samples may not be sufficient to characterize an entire concept class. In contrast, humans use cross-modal information to learn new concepts efficiently. In this work, we demonstrate that one can indeed build a better ${bf visual}$ dog classifier by ${bf read}$ing about dogs and ${bf listen}$ing to them bark. To do so, we exploit the fact that recent multimodal foundation models such as CLIP learn cross-modal encoders that map different modalities to the same representation space. Specifically, we propose a simple strategy for ${bf cross-modal}$ ${bf adaptation}$: we treat examples from different modalities as additional few-shot examples. For example, by simply repurposing class names as an additional training sample, we trivially turn any n-shot learning problem into a (n+1)-shot problem. This allows us to produce SOTA results with embarrassingly simple linear classifiers. We show that our approach can be combined with existing methods such as prefix tuning, adapters, and classifier ensembling. Finally, to explore other modalities beyond vision and language, we construct the first (to our knowledge) audiovisual few-shot benchmark and use cross-modal training to improve the performance of both image and audio classification.
Read more8/29/2024
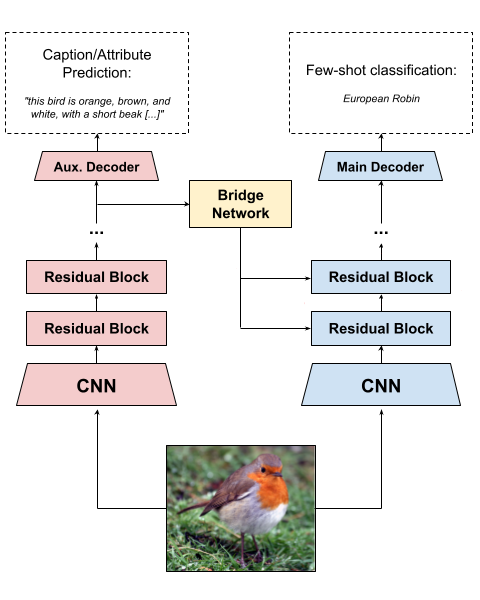
0
On the Limits of Multi-modal Meta-Learning with Auxiliary Task Modulation Using Conditional Batch Normalization
Jordi Armengol-Estap'e, Vincent Michalski, Ramnath Kumar, Pierre-Luc St-Charles, Doina Precup, Samira Ebrahimi Kahou
Few-shot learning aims to learn representations that can tackle novel tasks given a small number of examples. Recent studies show that cross-modal learning can improve representations for few-shot classification. More specifically, language is a rich modality that can be used to guide visual learning. In this work, we experiment with a multi-modal architecture for few-shot learning that consists of three components: a classifier, an auxiliary network, and a bridge network. While the classifier performs the main classification task, the auxiliary network learns to predict language representations from the same input, and the bridge network transforms high-level features of the auxiliary network into modulation parameters for layers of the few-shot classifier using conditional batch normalization. The bridge should encourage a form of lightweight semantic alignment between language and vision which could be useful for the classifier. However, after evaluating the proposed approach on two popular few-shot classification benchmarks we find that a) the improvements do not reproduce across benchmarks, and b) when they do, the improvements are due to the additional compute and parameters introduced by the bridge network. We contribute insights and recommendations for future work in multi-modal meta-learning, especially when using language representations.
Read more5/31/2024
🌐
0
GAME-ON: Graph Attention Network based Multimodal Fusion for Fake News Detection
Mudit Dhawan, Shakshi Sharma, Aditya Kadam, Rajesh Sharma, Ponnurangam Kumaraguru
Social media in present times has a significant and growing influence. Fake news being spread on these platforms have a disruptive and damaging impact on our lives. Furthermore, as multimedia content improves the visibility of posts more than text data, it has been observed that often multimedia is being used for creating fake content. A plethora of previous multimodal-based work has tried to address the problem of modeling heterogeneous modalities in identifying fake content. However, these works have the following limitations: (1) inefficient encoding of inter-modal relations by utilizing a simple concatenation operator on the modalities at a later stage in a model, which might result in information loss; (2) training very deep neural networks with a disproportionate number of parameters on small but complex real-life multimodal datasets result in higher chances of overfitting. To address these limitations, we propose GAME-ON, a Graph Neural Network based end-to-end trainable framework that allows granular interactions within and across different modalities to learn more robust data representations for multimodal fake news detection. We use two publicly available fake news datasets, Twitter and Weibo, for evaluations. Our model outperforms on Twitter by an average of 11% and keeps competitive performance on Weibo, within a 2.6% margin, while using 65% fewer parameters than the best comparable state-of-the-art baseline.
Read more6/13/2024