On the Limits of Multi-modal Meta-Learning with Auxiliary Task Modulation Using Conditional Batch Normalization

0
Sign in to get full access
Overview
- Explores the limits of multi-modal meta-learning with auxiliary task modulation using conditional batch normalization
- Investigates the ability of multi-modal models to generalize and adapt to new tasks and data distributions
- Proposes a novel approach that leverages conditional batch normalization to modulate network activations based on auxiliary task information
Plain English Explanation
This research paper examines the capabilities and limitations of multi-modal machine learning models that are trained to perform a wide variety of tasks. These models aim to learn general representations that can be adapted to new tasks and data, a process known as "meta-learning."
The key idea explored in this paper is the use of "conditional batch normalization" to help the model adapt to new tasks. Batch normalization is a common technique in deep learning that helps stabilize and accelerate the training process. The researchers hypothesized that by conditioning the batch normalization on additional task-specific information, the model could more effectively adjust its internal representations to handle new scenarios.
The paper presents experiments comparing this conditional batch normalization approach to other meta-learning techniques across a range of multi-modal tasks, such as image classification, video understanding, and zero-shot learning. The results provide insights into the strengths and limitations of this meta-learning approach, and the authors discuss potential avenues for further improving the model's generalization capabilities.
Technical Explanation
The paper proposes a novel meta-learning approach that utilizes conditional batch normalization to modulate the feature representations of a multi-modal neural network based on auxiliary task information. This is motivated by the intuition that by explicitly conditioning the network's internal representations on task-specific metadata, the model can more effectively adapt to new tasks and data distributions.
The researchers design a series of experiments to evaluate this approach on various multi-modal learning tasks, including image classification, video understanding, and zero-shot learning. The model is trained on a diverse set of tasks and then evaluated on its ability to quickly adapt to new, unseen tasks through few-shot learning and semi-supervised learning.
The results demonstrate that the proposed conditional batch normalization approach can improve the model's adaptation capabilities compared to standard meta-learning techniques. However, the paper also highlights the inherent challenges in achieving truly general multi-modal meta-learning, as the model still struggles to fully leverage auxiliary task information across a wide range of scenarios.
Critical Analysis
The paper provides a thoughtful and rigorous exploration of the limits of multi-modal meta-learning. While the conditional batch normalization approach shows promise, the authors are careful to note that there are still significant challenges in developing models that can truly generalize across diverse tasks and data distributions.
One potential limitation raised in the paper is the reliance on manually-specified auxiliary task information, which may not be readily available in all real-world scenarios. An interesting area for future research could be investigating methods for automatically inferring or learning relevant task-specific metadata to drive the conditional batch normalization process.
Additionally, the experiments focus on a relatively narrow set of multi-modal tasks, and it would be valuable to see the approach evaluated on an even wider range of applications to better understand its broader applicability and limitations. Expanding the evaluation to include more complex, real-world tasks could also reveal additional challenges that need to be addressed.
Overall, this paper makes a valuable contribution to the ongoing research on multi-modal meta-learning. The insights and recommendations provided can help guide future work in this important and rapidly evolving field of study.
Conclusion
This research paper explores the limits of multi-modal meta-learning through the lens of conditional batch normalization. The proposed approach demonstrates the potential benefits of explicitly conditioning a model's internal representations on auxiliary task information, allowing for more effective adaptation to new scenarios.
While the results are promising, the paper also highlights the inherent challenges in achieving truly general multi-modal meta-learning. Continued research in this area, exploring alternative conditioning mechanisms, automated task inference, and a broader range of applications, could lead to further advancements in the field and bring us closer to the goal of building highly versatile and adaptable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Limits of Multi-modal Meta-Learning with Auxiliary Task Modulation Using Conditional Batch Normalization
Jordi Armengol-Estap'e, Vincent Michalski, Ramnath Kumar, Pierre-Luc St-Charles, Doina Precup, Samira Ebrahimi Kahou
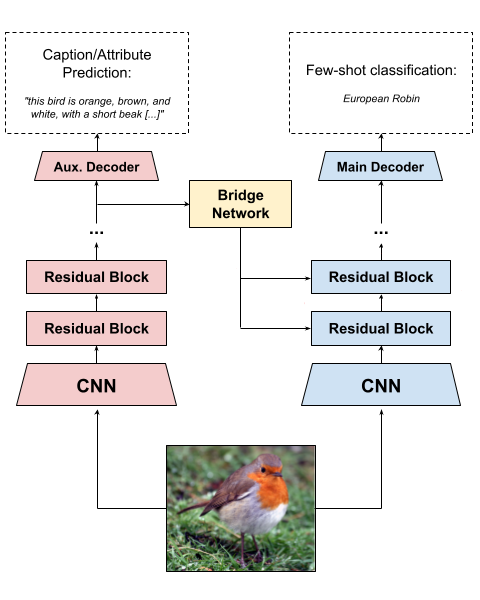
Few-shot learning aims to learn representations that can tackle novel tasks given a small number of examples. Recent studies show that cross-modal learning can improve representations for few-shot classification. More specifically, language is a rich modality that can be used to guide visual learning. In this work, we experiment with a multi-modal architecture for few-shot learning that consists of three components: a classifier, an auxiliary network, and a bridge network. While the classifier performs the main classification task, the auxiliary network learns to predict language representations from the same input, and the bridge network transforms high-level features of the auxiliary network into modulation parameters for layers of the few-shot classifier using conditional batch normalization. The bridge should encourage a form of lightweight semantic alignment between language and vision which could be useful for the classifier. However, after evaluating the proposed approach on two popular few-shot classification benchmarks we find that a) the improvements do not reproduce across benchmarks, and b) when they do, the improvements are due to the additional compute and parameters introduced by the bridge network. We contribute insights and recommendations for future work in multi-modal meta-learning, especially when using language representations.
Read more5/31/2024
📊
0
Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models
Zhiqiu Lin, Samuel Yu, Zhiyi Kuang, Deepak Pathak, Deva Ramanan
The ability to quickly learn a new task with minimal instruction - known as few-shot learning - is a central aspect of intelligent agents. Classical few-shot benchmarks make use of few-shot samples from a single modality, but such samples may not be sufficient to characterize an entire concept class. In contrast, humans use cross-modal information to learn new concepts efficiently. In this work, we demonstrate that one can indeed build a better ${bf visual}$ dog classifier by ${bf read}$ing about dogs and ${bf listen}$ing to them bark. To do so, we exploit the fact that recent multimodal foundation models such as CLIP learn cross-modal encoders that map different modalities to the same representation space. Specifically, we propose a simple strategy for ${bf cross-modal}$ ${bf adaptation}$: we treat examples from different modalities as additional few-shot examples. For example, by simply repurposing class names as an additional training sample, we trivially turn any n-shot learning problem into a (n+1)-shot problem. This allows us to produce SOTA results with embarrassingly simple linear classifiers. We show that our approach can be combined with existing methods such as prefix tuning, adapters, and classifier ensembling. Finally, to explore other modalities beyond vision and language, we construct the first (to our knowledge) audiovisual few-shot benchmark and use cross-modal training to improve the performance of both image and audio classification.
Read more8/29/2024
🤯
0
Multimodal CLIP Inference for Meta-Few-Shot Image Classification
Constance Ferragu, Philomene Chagniot, Vincent Coyette
In recent literature, few-shot classification has predominantly been defined by the N-way k-shot meta-learning problem. Models designed for this purpose are usually trained to excel on standard benchmarks following a restricted setup, excluding the use of external data. Given the recent advancements in large language and vision models, a question naturally arises: can these models directly perform well on meta-few-shot learning benchmarks? Multimodal foundation models like CLIP, which learn a joint (image, text) embedding, are of particular interest. Indeed, multimodal training has proven to enhance model robustness, especially regarding ambiguities, a limitation frequently observed in the few-shot setup. This study demonstrates that combining modalities from CLIP's text and image encoders outperforms state-of-the-art meta-few-shot learners on widely adopted benchmarks, all without additional training. Our results confirm the potential and robustness of multimodal foundation models like CLIP and serve as a baseline for existing and future approaches leveraging such models.
Read more5/21/2024
🌐
0
Multimodal Guidance Network for Missing-Modality Inference in Content Moderation
Zhuokai Zhao, Harish Palani, Tianyi Liu, Lena Evans, Ruth Toner
Multimodal deep learning, especially vision-language models, have gained significant traction in recent years, greatly improving performance on many downstream tasks, including content moderation and violence detection. However, standard multimodal approaches often assume consistent modalities between training and inference, limiting applications in many real-world use cases, as some modalities may not be available during inference. While existing research mitigates this problem through reconstructing the missing modalities, they unavoidably increase unnecessary computational cost, which could be just as critical, especially for large, deployed infrastructures in industry. To this end, we propose a novel guidance network that promotes knowledge sharing during training, taking advantage of the multimodal representations to train better single-modality models to be used for inference. Real-world experiments in violence detection shows that our proposed framework trains single-modality models that significantly outperform traditionally trained counterparts, while avoiding increases in computational cost for inference.
Read more8/6/2024