Cross-modal Diffusion Modelling for Super-resolved Spatial Transcriptomics

0

Sign in to get full access
Overview
• This research paper proposes a novel cross-modal diffusion modeling approach for super-resolving spatial transcriptomics data.
• The method leverages the complementary information between high-resolution digital pathology images and low-resolution spatial transcriptomics data to enhance the spatial resolution of gene expression maps.
• The model learns a shared latent representation between the two modalities, enabling accurate super-resolution of the transcriptomics data using the pathology images as a reference.
Plain English Explanation
Spatial transcriptomics is a powerful technique that allows researchers to measure gene expression levels across different regions of a biological sample, such as a tissue section. However, the resolution of these measurements is often limited, making it difficult to study gene expression patterns at a fine-grained level.
This research tackles this challenge by developing a machine learning model that can "super-resolve" the spatial transcriptomics data using information from high-resolution digital pathology images of the same sample. The key idea is that the pathology images, which provide detailed visual information about the tissue structure, can help the model infer the missing details in the lower-resolution transcriptomics data.
The model works by learning a shared representation between the pathology images and the transcriptomics data, allowing it to effectively transfer information from one modality to the other. This enables the model to generate a high-resolution version of the gene expression map that is aligned with the underlying tissue structure revealed by the pathology images.
Technical Explanation
The proposed framework, known as Cross-modal Diffusion Modeling for Super-resolved Spatial Transcriptomics, consists of a cross-modal diffusion model that learns a shared latent representation between the high-resolution digital pathology images and the low-resolution spatial transcriptomics data.
The model is trained in a self-supervised manner, where the network is tasked with reconstructing the input pathology images and transcriptomics data from their respective diffused versions. This encourages the model to learn a robust and informative latent space that captures the underlying tissue structure and its associated gene expression patterns.
During inference, the trained model can then use the high-resolution pathology images as a reference to generate a super-resolved version of the spatial transcriptomics data, effectively enhancing the spatial resolution of the gene expression maps.
The researchers demonstrate the effectiveness of their approach on several real-world datasets, showing significant improvements in the quality of the super-resolved transcriptomics data compared to alternative methods.
Critical Analysis
The paper presents a compelling approach to addressing the resolution mismatch between digital pathology and spatial transcriptomics data. By leveraging the complementary information between the two modalities, the proposed cross-modal diffusion model is able to generate high-quality super-resolved gene expression maps.
One potential limitation of the method is its reliance on the availability of registered pathology and transcriptomics data for the same tissue samples. In practice, this data may not always be readily available, which could limit the broader applicability of the approach.
Additionally, the paper does not provide a detailed analysis of the types of tissue structures and gene expression patterns that the model is able to recover most effectively. Further research could explore the model's performance on different tissue types and biological processes.
Conclusion
This research presents a novel cross-modal diffusion modeling approach for enhancing the spatial resolution of spatial transcriptomics data using complementary information from high-resolution digital pathology images. The method learns a shared latent representation between the two modalities, enabling accurate super-resolution of the transcriptomics data.
The proposed framework has the potential to significantly improve our ability to study gene expression patterns at a fine-grained level, which could lead to new insights into tissue organization, cellular interactions, and disease pathogenesis. As spatial transcriptomics and digital pathology continue to evolve, this type of cross-modal integration will likely become an increasingly valuable tool in the biological and medical research communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-modal Diffusion Modelling for Super-resolved Spatial Transcriptomics
Xiaofei Wang, Xingxu Huang, Stephen J. Price, Chao Li
The recent advancement of spatial transcriptomics (ST) allows to characterize spatial gene expression within tissue for discovery research. However, current ST platforms suffer from low resolution, hindering in-depth understanding of spatial gene expression. Super-resolution approaches promise to enhance ST maps by integrating histology images with gene expressions of profiled tissue spots. However, current super-resolution methods are limited by restoration uncertainty and mode collapse. Although diffusion models have shown promise in capturing complex interactions between multi-modal conditions, it remains a challenge to integrate histology images and gene expression for super-resolved ST maps. This paper proposes a cross-modal conditional diffusion model for super-resolving ST maps with the guidance of histology images. Specifically, we design a multi-modal disentangling network with cross-modal adaptive modulation to utilize complementary information from histology images and spatial gene expression. Moreover, we propose a dynamic cross-attention modelling strategy to extract hierarchical cell-to-tissue information from histology images. Lastly, we propose a co-expression-based gene-correlation graph network to model the co-expression relationship of multiple genes. Experiments show that our method outperforms other state-of-the-art methods in ST super-resolution on three public datasets.
Read more5/28/2024
0
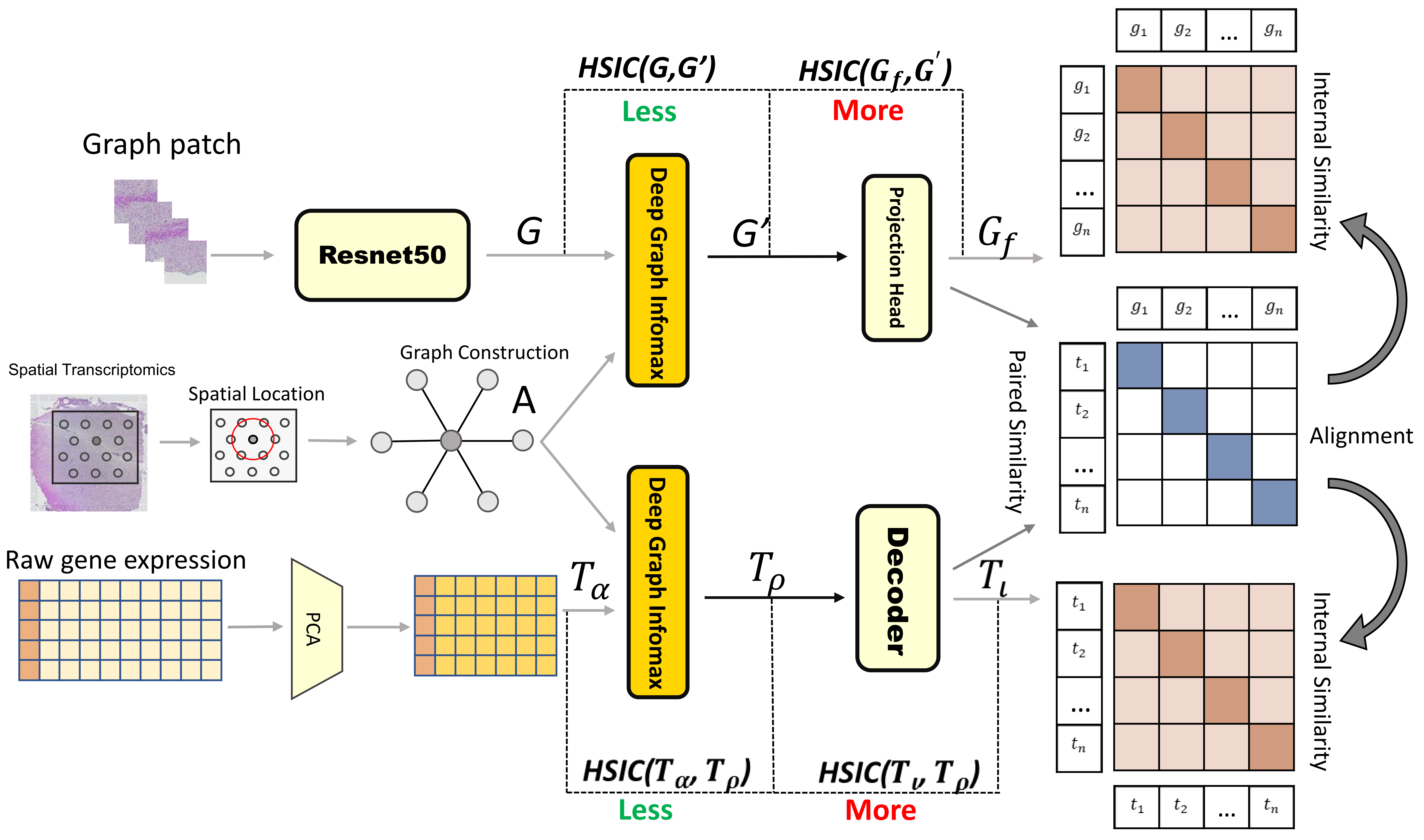
Spatially Resolved Gene Expression Prediction from Histology via Multi-view Graph Contrastive Learning with HSIC-bottleneck Regularization
Changxi Chi, Hang Shi, Qi Zhu, Daoqiang Zhang, Wei Shao
The rapid development of spatial transcriptomics(ST) enables the measurement of gene expression at spatial resolution, making it possible to simultaneously profile the gene expression, spatial locations of spots, and the matched histopathological images. However, the cost for collecting ST data is much higher than acquiring histopathological images, and thus several studies attempt to predict the gene expression on ST by leveraging their corresponding histopathological images. Most of the existing image-based gene prediction models treat the prediction task on each spot of ST data independently, which ignores the spatial dependency among spots. In addition, while the histology images share phenotypic characteristics with the ST data, it is still challenge to extract such common information to help align paired image and expression representations. To address the above issues, we propose a Multi-view Graph Contrastive Learning framework with HSIC-bottleneck Regularization(ST-GCHB) aiming at learning shared representation to help impute the gene expression of the queried imagingspots by considering their spatial dependency.
Read more6/19/2024

0
Multimodal contrastive learning for spatial gene expression prediction using histology images
Wenwen Min, Zhiceng Shi, Jun Zhang, Jun Wan, Changmiao Wang
In recent years, the advent of spatial transcriptomics (ST) technology has unlocked unprecedented opportunities for delving into the complexities of gene expression patterns within intricate biological systems. Despite its transformative potential, the prohibitive cost of ST technology remains a significant barrier to its widespread adoption in large-scale studies. An alternative, more cost-effective strategy involves employing artificial intelligence to predict gene expression levels using readily accessible whole-slide images (WSIs) stained with Hematoxylin and Eosin (H&E). However, existing methods have yet to fully capitalize on multimodal information provided by H&E images and ST data with spatial location. In this paper, we propose textbf{mclSTExp}, a multimodal contrastive learning with Transformer and Densenet-121 encoder for Spatial Transcriptomics Expression prediction. We conceptualize each spot as a word, integrating its intrinsic features with spatial context through the self-attention mechanism of a Transformer encoder. This integration is further enriched by incorporating image features via contrastive learning, thereby enhancing the predictive capability of our model. Our extensive evaluation of textbf{mclSTExp} on two breast cancer datasets and a skin squamous cell carcinoma dataset demonstrates its superior performance in predicting spatial gene expression. Moreover, mclSTExp has shown promise in interpreting cancer-specific overexpressed genes, elucidating immune-related genes, and identifying specialized spatial domains annotated by pathologists. Our source code is available at https://github.com/shizhiceng/mclSTExp.
Read more7/12/2024

0
High-Resolution Spatial Transcriptomics from Histology Images using HisToSGE
Zhiceng Shi, Shuailin Xue, Fangfang Zhu, Wenwen Min
Spatial transcriptomics (ST) is a groundbreaking genomic technology that enables spatial localization analysis of gene expression within tissue sections. However, it is significantly limited by high costs and sparse spatial resolution. An alternative, more cost-effective strategy is to use deep learning methods to predict high-density gene expression profiles from histological images. However, existing methods struggle to capture rich image features effectively or rely on low-dimensional positional coordinates, making it difficult to accurately predict high-resolution gene expression profiles. To address these limitations, we developed HisToSGE, a method that employs a Pathology Image Large Model (PILM) to extract rich image features from histological images and utilizes a feature learning module to robustly generate high-resolution gene expression profiles. We evaluated HisToSGE on four ST datasets, comparing its performance with five state-of-the-art baseline methods. The results demonstrate that HisToSGE excels in generating high-resolution gene expression profiles and performing downstream tasks such as spatial domain identification. All code and public datasets used in this paper are available at https://github.com/wenwenmin/HisToSGE and https://zenodo.org/records/12792163.
Read more7/31/2024