Cross-sensor self-supervised training and alignment for remote sensing
2405.09922
0
0
🏋️
Abstract
Large-scale foundation models have gained traction as a way to leverage the vast amounts of unlabeled remote sensing data collected every day. However, due to the multiplicity of Earth Observation satellites, these models should learn sensor agnostic representations, that generalize across sensor characteristics with minimal fine-tuning. This is complicated by data availability, as low-resolution imagery, such as Sentinel-2 and Landsat-8 data, are available in large amounts, while very high-resolution aerial or satellite data is less common. To tackle these challenges, we introduce cross-sensor self-supervised training and alignment for remote sensing (X-STARS). We design a self-supervised training loss, the Multi-Sensor Alignment Dense loss (MSAD), to align representations across sensors, even with vastly different resolutions. Our X-STARS can be applied to train models from scratch, or to adapt large models pretrained on e.g low-resolution EO data to new high-resolution sensors, in a continual pretraining framework. We collect and release MSC-France, a new multi-sensor dataset, on which we train our X-STARS models, then evaluated on seven downstream classification and segmentation tasks. We demonstrate that X-STARS outperforms the state-of-the-art by a significant margin with less data across various conditions of data availability and resolutions.
Create account to get full access
Overview
- Large-scale foundation models have become a way to leverage the vast amounts of unlabeled remote sensing data collected every day.
- However, these models need to learn sensor-agnostic representations that generalize across sensor characteristics with minimal fine-tuning, due to the multiplicity of Earth Observation satellites.
- Data availability is a challenge, as low-resolution imagery is widely available, while high-resolution aerial or satellite data is less common.
- To address these challenges, the paper introduces Cross-sensor Self-supervised Training and Alignment for Remote Sensing (X-STARS).
Plain English Explanation
The paper focuses on developing a new approach to train large machine learning models for remote sensing applications. These models, known as "foundation models," can be used to extract insights from the vast amounts of satellite and aerial imagery data collected every day.
The key challenge is that this data comes from many different types of sensors, each with its own unique characteristics. To be truly useful, the models need to be able to work with data from a wide range of sensors without requiring a lot of additional training or fine-tuning.
The researchers address this by designing a "self-supervised" training approach called X-STARS. This allows the models to learn general representations that work across different sensors, even when the data has very different resolutions (e.g., low-resolution Sentinel-2 or Landsat-8 data versus high-resolution aerial imagery).
The researchers also create a new dataset called MSC-France, which contains multi-sensor imagery data, to train and evaluate their X-STARS models. They show that these models outperform existing state-of-the-art approaches on a variety of remote sensing tasks, while using less data.
Technical Explanation
The paper introduces Cross-sensor Self-supervised Training and Alignment for Remote Sensing (X-STARS), a new approach to train large-scale foundation models for remote sensing applications. These models need to learn sensor-agnostic representations that can generalize across the characteristics of different Earth Observation satellites, as described in related work on self-supervised modality fusion and cross-sensor super-resolution.
The key innovation in X-STARS is the design of a self-supervised training loss called the Multi-Sensor Alignment Dense (MSAD) loss. This loss function aligns the representations learned by the model across sensors, even when the data has vastly different resolutions, such as low-resolution Sentinel-2 or Landsat-8 imagery versus high-resolution aerial or satellite data.
The researchers also collect and release a new multi-sensor dataset called MSC-France, which they use to train and evaluate their X-STARS models. They show that X-STARS outperforms state-of-the-art approaches on a range of downstream classification and segmentation tasks, while requiring less data, as described in related work on semantic-guided remote sensing and cross-modal self-training.
Critical Analysis
The paper presents a compelling approach to address the challenges of learning sensor-agnostic representations for remote sensing applications. The self-supervised training strategy and the creation of the MSC-France dataset are significant contributions.
However, the paper does not provide a detailed analysis of the limitations or failure cases of the X-STARS approach. For example, it would be helpful to understand how the model performs on particularly challenging or noisy data, or how it handles sensor characteristics that are not well represented in the training data.
Additionally, the paper could have explored the potential trade-offs or downsides of the MSAD loss function, such as its computational complexity or the risk of negative transfer between sensors with very different characteristics.
Overall, the research is a valuable step forward in the development of large-scale foundation models for remote sensing, but further investigation into the model's robustness and limitations would strengthen the work.
Conclusion
The Cross-sensor Self-supervised Training and Alignment for Remote Sensing (X-STARS) approach introduced in this paper represents a significant advancement in the field of remote sensing AI. By designing a self-supervised training strategy that can align representations across sensors, even with vastly different resolutions, the researchers have developed a powerful tool for leveraging the vast amounts of unlabeled remote sensing data available.
The creation of the MSC-France dataset and the impressive performance of the X-STARS models on a range of downstream tasks suggest that this approach has the potential to unlock new insights and applications in areas like semantic-guided remote sensing and cross-modal self-training.
As the field of remote sensing continues to evolve, with an ever-increasing array of Earth Observation satellites and sensors, the ability to train models that can work seamlessly across this diverse landscape will become increasingly critical. The X-STARS approach represents an important step in this direction, and the insights and techniques developed in this paper are likely to have a significant impact on the future of remote sensing AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multi-Label Guided Soft Contrastive Learning for Efficient Earth Observation Pretraining
Yi Wang, Conrad M Albrecht, Xiao Xiang Zhu
0
0
Self-supervised pretraining on large-scale satellite data has raised great interest in building Earth observation (EO) foundation models. However, many important resources beyond pure satellite imagery, such as land-cover-land-use products that provide free global semantic information, as well as vision foundation models that hold strong knowledge of the natural world, tend to be overlooked. In this work, we show these free additional resources not only help resolve common contrastive learning bottlenecks, but also significantly boost the efficiency and effectiveness of EO pretraining. Specifically, we first propose soft contrastive learning that optimizes cross-scene soft similarity based on land-cover-generated multi-label supervision, naturally solving the issue of multiple positive samples and too strict positive matching in complex scenes. Second, we explore cross-domain continual pretraining for both multispectral and SAR imagery, building efficient EO foundation models from strongest vision models such as DINOv2. Integrating simple weight-initialization and Siamese masking strategies into our soft contrastive learning framework, we demonstrate impressive continual pretraining performance even when the input channels and modalities are not aligned. Without prohibitive training, we produce multispectral and SAR foundation models that achieve significantly better results in 9 out of 10 downstream tasks than most existing SOTA models. For example, our ResNet50/ViT-S achieve 84.8/85.0 linear probing mAP scores on BigEarthNet-10% which are better than most existing ViT-L models; under the same setting, our ViT-B sets a new record of 86.8 in multispectral, and 82.5 in SAR, the latter even better than many multispectral models. Dataset and models are available at https://github.com/zhu-xlab/softcon.
6/3/2024

S4: Self-Supervised Sensing Across the Spectrum
Jayanth Shenoy, Xingjian Davis Zhang, Shlok Mehrotra, Bill Tao, Rem Yang, Han Zhao, Deepak Vasisht
0
0
Satellite image time series (SITS) segmentation is crucial for many applications like environmental monitoring, land cover mapping and agricultural crop type classification. However, training models for SITS segmentation remains a challenging task due to the lack of abundant training data, which requires fine grained annotation. We propose S4 a new self-supervised pre-training approach that significantly reduces the requirement for labeled training data by utilizing two new insights: (a) Satellites capture images in different parts of the spectrum such as radio frequencies, and visible frequencies. (b) Satellite imagery is geo-registered allowing for fine-grained spatial alignment. We use these insights to formulate pre-training tasks in S4. We also curate m2s2-SITS, a large-scale dataset of unlabeled, spatially-aligned, multi-modal and geographic specific SITS that serves as representative pre-training data for S4. Finally, we evaluate S4 on multiple SITS segmentation datasets and demonstrate its efficacy against competing baselines while using limited labeled data.
6/28/2024
Single-Temporal Supervised Learning for Universal Remote Sensing Change Detection
Zhuo Zheng, Yanfei Zhong, Ailong Ma, Liangpei Zhang
0
0
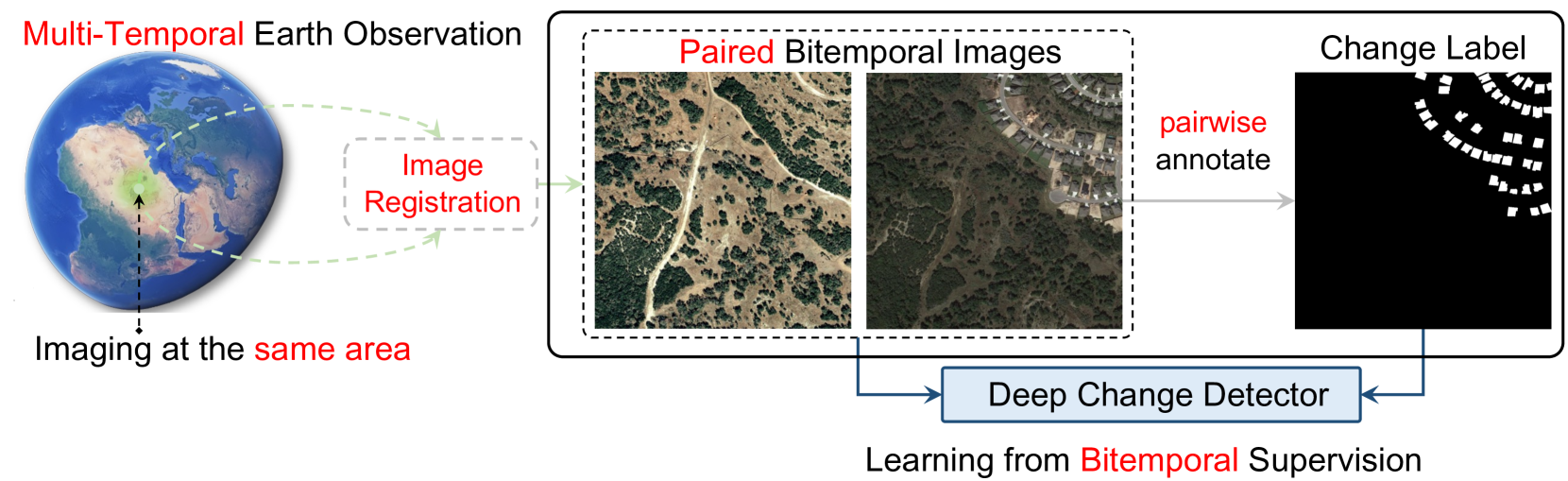
Bitemporal supervised learning paradigm always dominates remote sensing change detection using numerous labeled bitemporal image pairs, especially for high spatial resolution (HSR) remote sensing imagery. However, it is very expensive and labor-intensive to label change regions in large-scale bitemporal HSR remote sensing image pairs. In this paper, we propose single-temporal supervised learning (STAR) for universal remote sensing change detection from a new perspective of exploiting changes between unpaired images as supervisory signals. STAR enables us to train a high-accuracy change detector only using unpaired labeled images and can generalize to real-world bitemporal image pairs. To demonstrate the flexibility and scalability of STAR, we design a simple yet unified change detector, termed ChangeStar2, capable of addressing binary change detection, object change detection, and semantic change detection in one architecture. ChangeStar2 achieves state-of-the-art performances on eight public remote sensing change detection datasets, covering above two supervised settings, multiple change types, multiple scenarios. The code is available at https://github.com/Z-Zheng/pytorch-change-models.
6/26/2024
🔮
OmniSat: Self-Supervised Modality Fusion for Earth Observation
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, Loic Landrieu
0
0
The field of Earth Observations (EO) offers a wealth of data from diverse sensors, presenting a great opportunity for advancing self-supervised multimodal learning. However, current multimodal EO datasets and models focus on a single data type, either mono-date images or time series, which limits their expressivity. We introduce OmniSat, a novel architecture that exploits the spatial alignment between multiple EO modalities to learn expressive multimodal representations without labels. To demonstrate the advantages of combining modalities of different natures, we augment two existing datasets with new modalities. As demonstrated on three downstream tasks: forestry, land cover classification, and crop mapping. OmniSat can learn rich representations in an unsupervised manner, leading to improved performance in the semi- and fully-supervised settings, even when only one modality is available for inference. The code and dataset are available at github.com/gastruc/OmniSat.
4/15/2024