OmniSat: Self-Supervised Modality Fusion for Earth Observation
2404.08351
0
0
🔮
Abstract
The field of Earth Observations (EO) offers a wealth of data from diverse sensors, presenting a great opportunity for advancing self-supervised multimodal learning. However, current multimodal EO datasets and models focus on a single data type, either mono-date images or time series, which limits their expressivity. We introduce OmniSat, a novel architecture that exploits the spatial alignment between multiple EO modalities to learn expressive multimodal representations without labels. To demonstrate the advantages of combining modalities of different natures, we augment two existing datasets with new modalities. As demonstrated on three downstream tasks: forestry, land cover classification, and crop mapping. OmniSat can learn rich representations in an unsupervised manner, leading to improved performance in the semi- and fully-supervised settings, even when only one modality is available for inference. The code and dataset are available at github.com/gastruc/OmniSat.
Create account to get full access
Overview
- This paper introduces OmniSat, a self-supervised learning framework for fusing multimodal Earth observation data.
- OmniSat leverages contrastive learning to learn representations that capture the underlying relationships between different data modalities, such as satellite imagery, weather data, and geographic features.
- The authors demonstrate that OmniSat outperforms state-of-the-art methods on a range of downstream tasks, including land cover classification, time series analysis, and high-resolution image generation.
Plain English Explanation
OmniSat is a new way of analyzing different types of data about the Earth, like satellite images, weather information, and geographic features. The key idea is to use a technique called "contrastive learning" to help the computer system understand how all these different data sources are related to each other.
By learning these relationships, the system can then be used to tackle a variety of real-world problems, like accurately classifying land cover types, analyzing how things change over time, and even generating high-resolution satellite images.
The advantage of OmniSat is that it can learn these relationships in a self-supervised way, meaning it can discover patterns in the data without needing a lot of manual labeling or supervision. This makes it a powerful tool for working with the massive amounts of Earth observation data that are available today.
Technical Explanation
The core of OmniSat is a contrastive learning framework that learns to fuse information from different modalities of Earth observation data. The authors leverage deep generative data assimilation techniques to learn joint representations that capture the underlying relationships between satellite imagery, weather data, and geographic features.
Specifically, the OmniSat architecture consists of modality-specific encoders that map the input data into a shared latent space. A contrastive loss function is used to encourage the model to learn representations where matching data samples from different modalities are pulled together, while non-matching samples are pushed apart.
The authors also incorporate relative positional encoding to capture the spatial relationships between different parts of the input data, which is shown to be more effective than absolute positional encoding in their ablation studies.
Critical Analysis
The authors provide a thorough evaluation of OmniSat, demonstrating its effectiveness on a range of downstream tasks compared to state-of-the-art methods. However, the paper does not address several potential limitations and areas for future research.
For example, the authors only consider a limited set of modalities (satellite imagery, weather, and geography) in their experiments. It would be interesting to see how OmniSat performs when incorporating additional data sources, such as socioeconomic indicators or ground-based sensor networks.
Additionally, the paper does not discuss the computational and memory requirements of OmniSat, which could be an important consideration for real-world deployment, especially in resource-constrained environments.
Finally, the authors do not provide any analysis of the learned representations or the specific relationships that OmniSat discovers between the different data modalities. A deeper investigation of the inner workings of the model could lead to additional insights and opportunities for improvement.
Conclusion
The OmniSat framework represents a significant advance in the field of self-supervised multimodal learning for Earth observation. By leveraging contrastive learning to fuse diverse data sources, the authors have developed a powerful tool that can tackle a wide range of problems, from land cover classification to high-resolution image generation.
The potential impact of OmniSat is far-reaching, as it could enable more efficient and effective monitoring and management of natural resources, infrastructure, and human activities on a global scale. As the authors continue to refine and expand the capabilities of this framework, it is likely to become an increasingly valuable asset for researchers, policymakers, and practitioners in the field of Earth observation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MMEarth: Exploring Multi-Modal Pretext Tasks For Geospatial Representation Learning
Vishal Nedungadi, Ankit Kariryaa, Stefan Oehmcke, Serge Belongie, Christian Igel, Nico Lang
0
0
The volume of unlabelled Earth observation (EO) data is huge, but many important applications lack labelled training data. However, EO data offers the unique opportunity to pair data from different modalities and sensors automatically based on geographic location and time, at virtually no human labor cost. We seize this opportunity to create a diverse multi-modal pretraining dataset at global scale. Using this new corpus of 1.2 million locations, we propose a Multi-Pretext Masked Autoencoder (MP-MAE) approach to learn general-purpose representations for optical satellite images. Our approach builds on the ConvNeXt V2 architecture, a fully convolutional masked autoencoder (MAE). Drawing upon a suite of multi-modal pretext tasks, we demonstrate that our MP-MAE approach outperforms both MAEs pretrained on ImageNet and MAEs pretrained on domain-specific satellite images. This is shown on several downstream tasks including image classification and semantic segmentation. We find that multi-modal pretraining notably improves the linear probing performance, e.g. 4pp on BigEarthNet and 16pp on So2Sat, compared to pretraining on optical satellite images only. We show that this also leads to better label and parameter efficiency which are crucial aspects in global scale applications.
5/7/2024

Multi-Label Guided Soft Contrastive Learning for Efficient Earth Observation Pretraining
Yi Wang, Conrad M Albrecht, Xiao Xiang Zhu
0
0
Self-supervised pretraining on large-scale satellite data has raised great interest in building Earth observation (EO) foundation models. However, many important resources beyond pure satellite imagery, such as land-cover-land-use products that provide free global semantic information, as well as vision foundation models that hold strong knowledge of the natural world, tend to be overlooked. In this work, we show these free additional resources not only help resolve common contrastive learning bottlenecks, but also significantly boost the efficiency and effectiveness of EO pretraining. Specifically, we first propose soft contrastive learning that optimizes cross-scene soft similarity based on land-cover-generated multi-label supervision, naturally solving the issue of multiple positive samples and too strict positive matching in complex scenes. Second, we explore cross-domain continual pretraining for both multispectral and SAR imagery, building efficient EO foundation models from strongest vision models such as DINOv2. Integrating simple weight-initialization and Siamese masking strategies into our soft contrastive learning framework, we demonstrate impressive continual pretraining performance even when the input channels and modalities are not aligned. Without prohibitive training, we produce multispectral and SAR foundation models that achieve significantly better results in 9 out of 10 downstream tasks than most existing SOTA models. For example, our ResNet50/ViT-S achieve 84.8/85.0 linear probing mAP scores on BigEarthNet-10% which are better than most existing ViT-L models; under the same setting, our ViT-B sets a new record of 86.8 in multispectral, and 82.5 in SAR, the latter even better than many multispectral models. Dataset and models are available at https://github.com/zhu-xlab/softcon.
6/3/2024
🏋️
Cross-sensor self-supervised training and alignment for remote sensing
Valerio Marsocci (CEDRIC - VERTIGO, CNAM), Nicolas Audebert (CEDRIC - VERTIGO, CNAM, LaSTIG, IGN)
0
0
Large-scale foundation models have gained traction as a way to leverage the vast amounts of unlabeled remote sensing data collected every day. However, due to the multiplicity of Earth Observation satellites, these models should learn sensor agnostic representations, that generalize across sensor characteristics with minimal fine-tuning. This is complicated by data availability, as low-resolution imagery, such as Sentinel-2 and Landsat-8 data, are available in large amounts, while very high-resolution aerial or satellite data is less common. To tackle these challenges, we introduce cross-sensor self-supervised training and alignment for remote sensing (X-STARS). We design a self-supervised training loss, the Multi-Sensor Alignment Dense loss (MSAD), to align representations across sensors, even with vastly different resolutions. Our X-STARS can be applied to train models from scratch, or to adapt large models pretrained on e.g low-resolution EO data to new high-resolution sensors, in a continual pretraining framework. We collect and release MSC-France, a new multi-sensor dataset, on which we train our X-STARS models, then evaluated on seven downstream classification and segmentation tasks. We demonstrate that X-STARS outperforms the state-of-the-art by a significant margin with less data across various conditions of data availability and resolutions.
5/17/2024
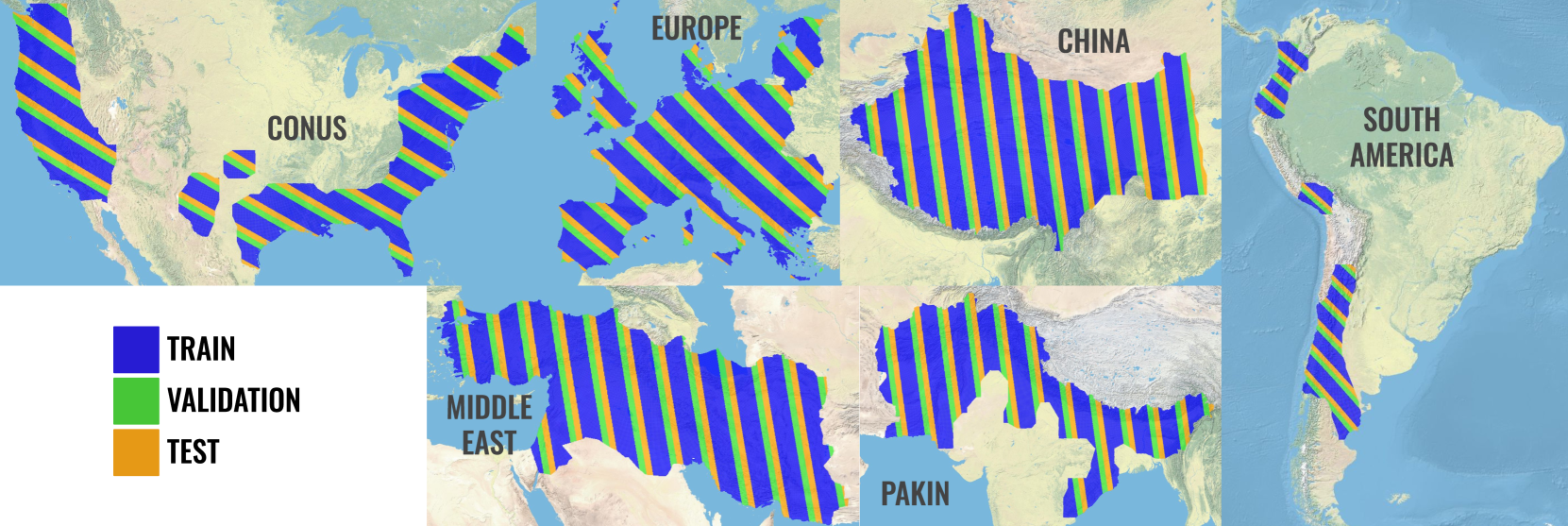
M3LEO: A Multi-Modal, Multi-Label Earth Observation Dataset Integrating Interferometric SAR and RGB Data
Matthew J Allen, Francisco Dorr, Joseph Alejandro Gallego Mejia, Laura Mart'inez-Ferrer, Anna Jungbluth, Freddie Kalaitzis, Ra'ul Ramos-Poll'an
0
0
Satellite-based remote sensing has revolutionised the way we address global challenges in a rapidly evolving world. Huge quantities of Earth Observation (EO) data are generated by satellite sensors daily, but processing these large datasets for use in ML pipelines is technically and computationally challenging. Specifically, different types of EO data are often hosted on a variety of platforms, with differing availability for Python preprocessing tools. In addition, spatial alignment across data sources and data tiling can present significant technical hurdles for novice users. While some preprocessed EO datasets exist, their content is often limited to optical or near-optical wavelength data, which is ineffective at night or in adverse weather conditions. Synthetic Aperture Radar (SAR), an active sensing technique based on microwave length radiation, offers a viable alternative. However, the application of machine learning to SAR has been limited due to a lack of ML-ready data and pipelines, particularly for the full diversity of SAR data, including polarimetry, coherence and interferometry. We introduce M3LEO, a multi-modal, multi-label EO dataset that includes polarimetric, interferometric, and coherence SAR data derived from Sentinel-1, alongside Sentinel-2 RGB imagery and a suite of labelled tasks for model evaluation. M3LEO spans 17.5TB and contains approximately 10M data chips across six geographic regions. The dataset is complemented by a flexible PyTorch Lightning framework, with configuration management using Hydra. We provide tools to process any dataset available on popular platforms such as Google Earth Engine for integration with our framework. Initial experiments validate the utility of our data and framework, showing that SAR imagery contains information additional to that extractable from RGB data. Data at huggingface.co/M3LEO, and code at github.com/spaceml-org/M3LEO.
6/7/2024