Cross-Task Defense: Instruction-Tuning LLMs for Content Safety
2405.15202
0
0

Abstract
Recent studies reveal that Large Language Models (LLMs) face challenges in balancing safety with utility, particularly when processing long texts for NLP tasks like summarization and translation. Despite defenses against malicious short questions, the ability of LLMs to safely handle dangerous long content, such as manuals teaching illicit activities, remains unclear. Our work aims to develop robust defenses for LLMs in processing malicious documents alongside benign NLP task queries. We introduce a defense dataset comprised of safety-related examples and propose single-task and mixed-task losses for instruction tuning. Our empirical results demonstrate that LLMs can significantly enhance their capacity to safely manage dangerous content with appropriate instruction tuning. Additionally, strengthening the defenses of tasks most susceptible to misuse is effective in protecting LLMs against processing harmful information. We also observe that trade-offs between utility and safety exist in defense strategies, where Llama2, utilizing our proposed approach, displays a significantly better balance compared to Llama1.
Create account to get full access
Overview
- This paper presents a novel approach to improving the safety and robustness of large language models (LLMs) through instruction-tuning.
- The researchers explore how instruction-tuning can help LLMs better detect and mitigate harmful or inappropriate content across a variety of tasks.
- The paper includes experiments and evaluations demonstrating the effectiveness of this approach in enhancing the content safety of LLMs.
Plain English Explanation
The researchers in this paper are trying to make large language models (LLMs) safer and more reliable. LLMs are powerful AI systems that can generate human-like text, but they can sometimes produce content that is harmful, biased, or inappropriate.
To address this, the researchers developed a new technique called "instruction-tuning." This involves training the LLM on a diverse set of instructions and tasks related to content safety, such as detecting hate speech, identifying misinformation, and avoiding biased or unethical language.
By exposing the LLM to these safety-oriented tasks during training, the researchers found that the model became much better at recognizing and avoiding problematic content across a wide range of applications. This could help make LLMs more trustworthy and reliable, especially for use cases where safety and responsibility are critical, such as [internal link: https://aimodels.fyi/papers/arxiv/towards-safe-large-language-models-medicine].
The paper presents experiments and evaluations that demonstrate the effectiveness of this instruction-tuning approach. The results suggest that it can significantly improve an LLM's ability to detect and mitigate harmful content, without compromising its overall performance on other tasks. This could be an important step towards building [internal link: https://aimodels.fyi/papers/arxiv/framework-real-time-safeguarding-text-generation-large] and [internal link: https://aimodels.fyi/papers/arxiv/llm-self-defense-by-self-examination-llms] that are more trustworthy and beneficial to society.
Technical Explanation
The researchers in this paper explored the use of "instruction-tuning" as a technique to enhance the content safety and robustness of large language models (LLMs). Instruction-tuning involves fine-tuning the LLM on a diverse set of tasks and instructions related to content safety, such as detecting hate speech, identifying misinformation, and avoiding biased or unethical language.
Through a series of experiments, the researchers evaluated the effectiveness of this approach across various safety-oriented benchmarks, including [internal link: https://aimodels.fyi/papers/arxiv/alert-comprehensive-benchmark-assessing-large-language-models] and [internal link: https://aimodels.fyi/papers/arxiv/evaluating-mitigating-linguistic-discrimination-large-language-models]. The results showed that instruction-tuned LLMs significantly outperformed their non-tuned counterparts in detecting and mitigating harmful content, while maintaining their overall performance on other tasks.
The researchers attribute the success of this approach to the LLM's ability to learn and generalize safety-critical principles and heuristics through the diverse set of instructions it is exposed to during training. This allows the model to develop a more nuanced understanding of what constitutes appropriate and inappropriate content, which it can then apply across a wide range of applications and scenarios.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in this paper. For example, they note that the effectiveness of instruction-tuning may vary depending on the specific tasks and instructions used, as well as the size and complexity of the LLM being trained.
Additionally, the researchers caution that while instruction-tuning can improve an LLM's content safety, it does not guarantee the complete elimination of harmful or biased outputs. There may still be edge cases or unanticipated scenarios where the model's responses could be problematic, and ongoing monitoring and refinement may be necessary.
Furthermore, the researchers highlight the importance of carefully designing the instruction-tuning process to avoid unintended consequences, such as the model becoming overly cautious or risk-averse in its language generation. There is a delicate balance to be struck between enhancing safety and maintaining the model's versatility and creativity.
[Internal link: https://aimodels.fyi/papers/arxiv/llm-self-defense-by-self-examination-llms] One potential area for further research could be exploring ways to make the instruction-tuning process more dynamic and responsive, allowing the LLM to continuously learn and adapt to evolving safety threats and societal norms.
Conclusion
This paper presents a promising approach to improving the safety and robustness of large language models through instruction-tuning. By exposing LLMs to a diverse set of safety-oriented tasks and instructions during training, the researchers demonstrated that these models can develop a more nuanced understanding of appropriate and inappropriate content, and apply this knowledge across a wide range of applications.
While the results are encouraging, the researchers acknowledge that ongoing research and refinement will be necessary to fully realize the potential of this approach. Nonetheless, this work represents an important step towards building [internal link: https://aimodels.fyi/papers/arxiv/framework-real-time-safeguarding-text-generation-large] that are more trustworthy, responsible, and beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SLM as Guardian: Pioneering AI Safety with Small Language Models
Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park
0
0
Most prior safety research of large language models (LLMs) has focused on enhancing the alignment of LLMs to better suit the safety requirements of humans. However, internalizing such safeguard features into larger models brought challenges of higher training cost and unintended degradation of helpfulness. To overcome such challenges, a modular approach employing a smaller LLM to detect harmful user queries is regarded as a convenient solution in designing LLM-based system with safety requirements. In this paper, we leverage a smaller LLM for both harmful query detection and safeguard response generation. We introduce our safety requirements and the taxonomy of harmfulness categories, and then propose a multi-task learning mechanism fusing the two tasks into a single model. We demonstrate the effectiveness of our approach, providing on par or surpassing harmful query detection and safeguard response performance compared to the publicly available LLMs.
5/31/2024
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
0
0
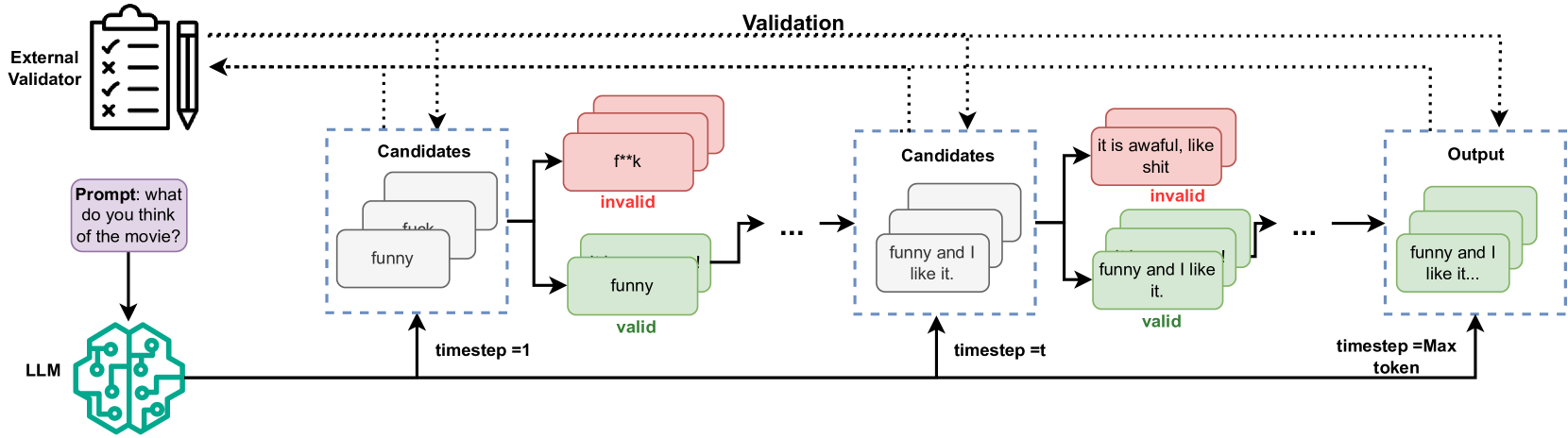
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
5/3/2024

MLLM-Protector: Ensuring MLLM's Safety without Hurting Performance
Renjie Pi, Tianyang Han, Jianshu Zhang, Yueqi Xie, Rui Pan, Qing Lian, Hanze Dong, Jipeng Zhang, Tong Zhang
0
0
The deployment of multimodal large language models (MLLMs) has brought forth a unique vulnerability: susceptibility to malicious attacks through visual inputs. This paper investigates the novel challenge of defending MLLMs against such attacks. Compared to large language models (LLMs), MLLMs include an additional image modality. We discover that images act as a ``foreign language that is not considered during safety alignment, making MLLMs more prone to producing harmful responses. Unfortunately, unlike the discrete tokens considered in text-based LLMs, the continuous nature of image signals presents significant alignment challenges, which poses difficulty to thoroughly cover all possible scenarios. This vulnerability is exacerbated by the fact that most state-of-the-art MLLMs are fine-tuned on limited image-text pairs that are much fewer than the extensive text-based pretraining corpus, which makes the MLLMs more prone to catastrophic forgetting of their original abilities during safety fine-tuning. To tackle these challenges, we introduce MLLM-Protector, a plug-and-play strategy that solves two subtasks: 1) identifying harmful responses via a lightweight harm detector, and 2) transforming harmful responses into harmless ones via a detoxifier. This approach effectively mitigates the risks posed by malicious visual inputs without compromising the original performance of MLLMs. Our results demonstrate that MLLM-Protector offers a robust solution to a previously unaddressed aspect of MLLM security.
6/18/2024
💬
Safety of Multimodal Large Language Models on Images and Texts
Xin Liu, Yichen Zhu, Yunshi Lan, Chao Yang, Yu Qiao
0
0
Attracted by the impressive power of Multimodal Large Language Models (MLLMs), the public is increasingly utilizing them to improve the efficiency of daily work. Nonetheless, the vulnerabilities of MLLMs to unsafe instructions bring huge safety risks when these models are deployed in real-world scenarios. In this paper, we systematically survey current efforts on the evaluation, attack, and defense of MLLMs' safety on images and text. We begin with introducing the overview of MLLMs on images and text and understanding of safety, which helps researchers know the detailed scope of our survey. Then, we review the evaluation datasets and metrics for measuring the safety of MLLMs. Next, we comprehensively present attack and defense techniques related to MLLMs' safety. Finally, we analyze several unsolved issues and discuss promising research directions. The latest papers are continually collected at https://github.com/isXinLiu/MLLM-Safety-Collection.
6/21/2024