Crossmodal ASR Error Correction with Discrete Speech Units
2405.16677
0
0

Abstract
ASR remains unsatisfactory in scenarios where the speaking style diverges from that used to train ASR systems, resulting in erroneous transcripts. To address this, ASR Error Correction (AEC), a post-ASR processing approach, is required. In this work, we tackle an understudied issue: the Low-Resource Out-of-Domain (LROOD) problem, by investigating crossmodal AEC on very limited downstream data with 1-best hypothesis transcription. We explore pre-training and fine-tuning strategies and uncover an ASR domain discrepancy phenomenon, shedding light on appropriate training schemes for LROOD data. Moreover, we propose the incorporation of discrete speech units to align with and enhance the word embeddings for improving AEC quality. Results from multiple corpora and several evaluation metrics demonstrate the feasibility and efficacy of our proposed AEC approach on LROOD data, as well as its generalizability and superiority on large-scale data. Finally, a study on speech emotion recognition confirms that our model produces ASR error-robust transcripts suitable for downstream applications.
Create account to get full access
Overview
- This paper explores a novel approach to correcting errors in automatic speech recognition (ASR) systems using crossmodal information from visual and textual modalities.
- The researchers propose a method that leverages discrete speech units, which are small, discrete representations of speech, to improve ASR error correction.
- The paper evaluates the proposed approach on various ASR corpora and compares its performance to state-of-the-art ASR error correction models.
Plain English Explanation
Automatic speech recognition (ASR) systems, which convert spoken words into text, often make mistakes. This paper introduces a new way to correct these errors by using information from other sources, like video and text.
The key idea is to use "discrete speech units" - small, distinct representations of speech sounds. These speech units can provide additional context to help the ASR system figure out the correct words, even when it's initially unsure.
For example, if the ASR system thinks the speaker said "dog" but the video shows the speaker's mouth moving in a way that matches the sound for "cat", the system can use that visual information to correct the error and output "cat" instead.
The researchers tested this approach on several different datasets and found that it outperformed other state-of-the-art methods for fixing ASR mistakes. This suggests that incorporating crossmodal information, like video and text, can be a powerful way to improve the accuracy of speech recognition systems.
Technical Explanation
The paper proposes a novel Crossmodal ASR Error Correction with Discrete Speech Units approach that leverages discrete speech units to improve automatic speech recognition (ASR) error correction.
The method first trains an ASR model to produce a sequence of discrete speech units, which are small, distinct representations of speech sounds, rather than directly outputting words. Then, a crossmodal error correction model is trained to take the ASR output, along with associated visual and textual information, and predict the correct speech units.
The researchers evaluate this approach on several conversational speech recognition datasets and compare it to state-of-the-art ASR error correction models and multimodal speech recognition systems. They find that the proposed method outperforms these baselines, demonstrating the effectiveness of using crossmodal discrete speech units for ASR error correction.
The paper also provides an analysis of the industrial-scale multilingual ASR systems and the types of errors they commonly make, which provides helpful context for understanding the significance of the proposed approach.
Critical Analysis
The paper provides a compelling and well-designed study of using crossmodal information to improve ASR error correction. The researchers carefully evaluate their approach on multiple datasets and compare it to strong baselines, which strengthens the credibility of their findings.
One potential limitation is that the paper focuses on relatively constrained conversational tasks, and it's unclear how well the approach would scale to more open-ended, spontaneous speech scenarios. Additionally, the paper does not delve into the computational efficiency or real-world deployment challenges of the proposed method.
Further research could explore extending the crossmodal error correction approach to handle a broader range of speech domains, as well as investigating ways to make the method more computationally efficient for practical applications. It would also be interesting to see how the discrete speech unit representations compare to alternative approaches, such as end-to-end neural ASR models.
Overall, this paper presents an innovative and promising direction for improving the accuracy of speech recognition systems by leveraging crossmodal information, which could have significant implications for a wide range of speech-based applications.
Conclusion
This paper introduces a novel approach to automatic speech recognition (ASR) error correction that utilizes crossmodal information from visual and textual modalities, along with discrete speech units. The proposed method outperforms state-of-the-art ASR error correction models, demonstrating the value of incorporating crossmodal cues to improve the accuracy of speech recognition systems.
The findings of this research suggest that leveraging multimodal data can be a powerful way to enhance the performance of ASR systems, especially in noisy or ambiguous speech scenarios. As speech-based interfaces become increasingly ubiquitous, advancements in this area could have far-reaching implications for a wide range of applications, from virtual assistants to accessibility tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
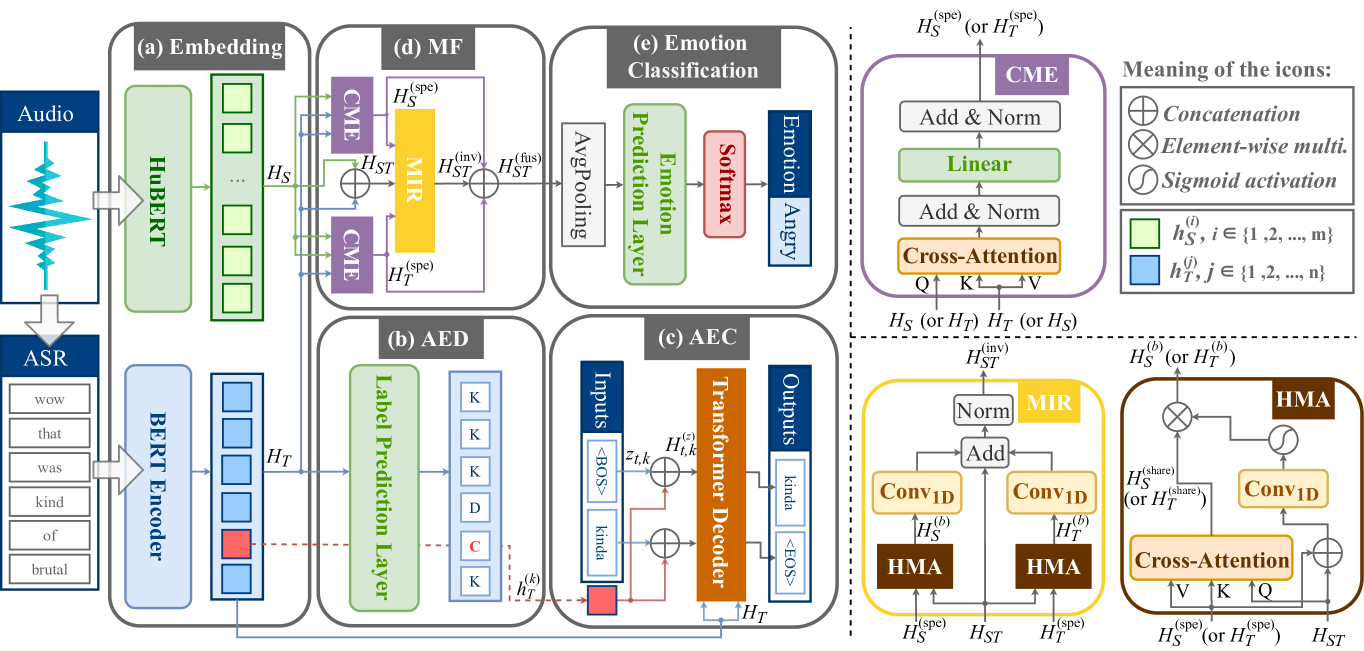
MF-AED-AEC: Speech Emotion Recognition by Leveraging Multimodal Fusion, Asr Error Detection, and Asr Error Correction
Jiajun He, Xiaohan Shi, Xingfeng Li, Tomoki Toda
0
0
The prevalent approach in speech emotion recognition (SER) involves integrating both audio and textual information to comprehensively identify the speaker's emotion, with the text generally obtained through automatic speech recognition (ASR). An essential issue of this approach is that ASR errors from the text modality can worsen the performance of SER. Previous studies have proposed using an auxiliary ASR error detection task to adaptively assign weights of each word in ASR hypotheses. However, this approach has limited improvement potential because it does not address the coherence of semantic information in the text. Additionally, the inherent heterogeneity of different modalities leads to distribution gaps between their representations, making their fusion challenging. Therefore, in this paper, we incorporate two auxiliary tasks, ASR error detection (AED) and ASR error correction (AEC), to enhance the semantic coherence of ASR text, and further introduce a novel multi-modal fusion (MF) method to learn shared representations across modalities. We refer to our method as MF-AED-AEC. Experimental results indicate that MF-AED-AEC significantly outperforms the baseline model by a margin of 4.1%.
5/29/2024

AG-LSEC: Audio Grounded Lexical Speaker Error Correction
Rohit Paturi, Xiang Li, Sundararajan Srinivasan
0
0
Speaker Diarization (SD) systems are typically audio-based and operate independently of the ASR system in traditional speech transcription pipelines and can have speaker errors due to SD and/or ASR reconciliation, especially around speaker turns and regions of speech overlap. To reduce these errors, a Lexical Speaker Error Correction (LSEC), in which an external language model provides lexical information to correct the speaker errors, was recently proposed. Though the approach achieves good Word Diarization error rate (WDER) improvements, it does not use any additional acoustic information and is prone to miscorrections. In this paper, we propose to enhance and acoustically ground the LSEC system with speaker scores directly derived from the existing SD pipeline. This approach achieves significant relative WDER reductions in the range of 25-40% over the audio-based SD, ASR system and beats the LSEC system by 15-25% relative on RT03-CTS, Callhome American English and Fisher datasets.
6/26/2024

Speech Emotion Recognition with ASR Transcripts: A Comprehensive Study on Word Error Rate and Fusion Techniques
Yuanchao Li, Peter Bell, Catherine Lai
0
0
Text data is commonly utilized as a primary input to enhance Speech Emotion Recognition (SER) performance and reliability. However, the reliance on human-transcribed text in most studies impedes the development of practical SER systems, creating a gap between in-lab research and real-world scenarios where Automatic Speech Recognition (ASR) serves as the text source. Hence, this study benchmarks SER performance using ASR transcripts with varying Word Error Rates (WERs) on well-known corpora: IEMOCAP, CMU-MOSI, and MSP-Podcast. Our evaluation includes text-only and bimodal SER with diverse fusion techniques, aiming for a comprehensive analysis that uncovers novel findings and challenges faced by current SER research. Additionally, we propose a unified ASR error-robust framework integrating ASR error correction and modality-gated fusion, achieving lower WER and higher SER results compared to the best-performing ASR transcript. This research is expected to provide insights into SER with ASR assistance, especially for real-world applications.
6/13/2024
🗣️
Conversational Speech Recognition by Learning Audio-textual Cross-modal Contextual Representation
Kun Wei, Bei Li, Hang Lv, Quan Lu, Ning Jiang, Lei Xie
0
0
Automatic Speech Recognition (ASR) in conversational settings presents unique challenges, including extracting relevant contextual information from previous conversational turns. Due to irrelevant content, error propagation, and redundancy, existing methods struggle to extract longer and more effective contexts. To address this issue, we introduce a novel conversational ASR system, extending the Conformer encoder-decoder model with cross-modal conversational representation. Our approach leverages a cross-modal extractor that combines pre-trained speech and text models through a specialized encoder and a modal-level mask input. This enables the extraction of richer historical speech context without explicit error propagation. We also incorporate conditional latent variational modules to learn conversational level attributes such as role preference and topic coherence. By introducing both cross-modal and conversational representations into the decoder, our model retains context over longer sentences without information loss, achieving relative accuracy improvements of 8.8% and 23% on Mandarin conversation datasets HKUST and MagicData-RAMC, respectively, compared to the standard Conformer model.
4/30/2024