Cryptographic Hardness of Score Estimation

0
Sign in to get full access
Overview
- This research paper explores the cryptographic hardness of score estimation, a fundamental problem in machine learning and data analysis.
- The authors prove that accurately estimating certain types of scores is computationally intractable, even for simple models and datasets.
- This has implications for the design and deployment of machine learning systems, as it suggests inherent limitations in our ability to reliably estimate key performance metrics.
Plain English Explanation
Score estimation is a crucial task in many areas of data analysis and machine learning. Imagine you have a model that tries to predict whether an email is spam or not. You would want to know how well that model is performing - what percentage of spam emails it correctly identifies, and what percentage of non-spam emails it incorrectly flags as spam. This performance metric is the model's "score."
The researchers in this paper show that precisely calculating certain types of scores can be an inherently difficult computational problem, even for simple models and datasets. It's as if there is an underlying mathematical barrier that prevents us from perfectly evaluating the performance of our predictive models.
This is an important finding because it means we have to be very careful when relying on score estimates to make decisions. If the scores are fundamentally hard to compute, then the numbers we get may not be as accurate or trustworthy as we'd like. It introduces an element of uncertainty that has to be carefully considered, especially in high-stakes applications like medical diagnosis or financial risk assessment.
Technical Explanation
The paper focuses on the problem of estimating the area under the receiver operating characteristic (AUC-ROC) curve, a common performance metric for binary classification models. The authors prove that accurately computing the AUC-ROC score is computationally intractable in the worst case, even for simple linear threshold models and datasets.
Specifically, they show that the problem is as hard as solving the "Nearest Codeword Problem" in coding theory, which is known to be NP-hard. This means that unless P=NP (a major open question in computer science), there is no efficient algorithm that can precisely calculate the AUC-ROC score for arbitrary models and data.
The authors also explore the hardness of estimating other common performance metrics, such as the F-score and precision-recall curves. They demonstrate that these problems are computationally difficult as well, suggesting inherent limitations in our ability to reliably evaluate machine learning models.
Critical Analysis
The results in this paper highlight fundamental challenges in the field of machine learning evaluation. The authors provide a rigorous theoretical foundation for the intuition that precisely quantifying model performance is an inherently difficult task.
That said, the hardness results are derived in the worst-case setting, which may not always reflect real-world scenarios. In practice, many machine learning models and datasets may exhibit sufficient structure or simplicity to allow for more efficient score estimation. The authors acknowledge this limitation and suggest exploring average-case or parametrized complexity as an area for future research.
Additionally, the paper focuses solely on the computational hardness of score estimation, without delving into the practical implications or potential mitigations. It would be valuable to see further discussion on how these findings should inform the design of machine learning systems, evaluation methodologies, and decision-making processes.
Conclusion
This research paper makes an important contribution to the foundations of machine learning by demonstrating the cryptographic hardness of score estimation, a core problem in model evaluation. The results highlight inherent limitations in our ability to reliably quantify the performance of predictive models, which has significant implications for the development and deployment of machine learning systems.
While the theoretical insights are compelling, the authors acknowledge that the practical impact of these findings warrants further exploration. Investigating average-case complexity, as well as exploring mitigation strategies and practical guidelines, could help bridge the gap between the theoretical limitations and real-world machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cryptographic Hardness of Score Estimation
Min Jae Song
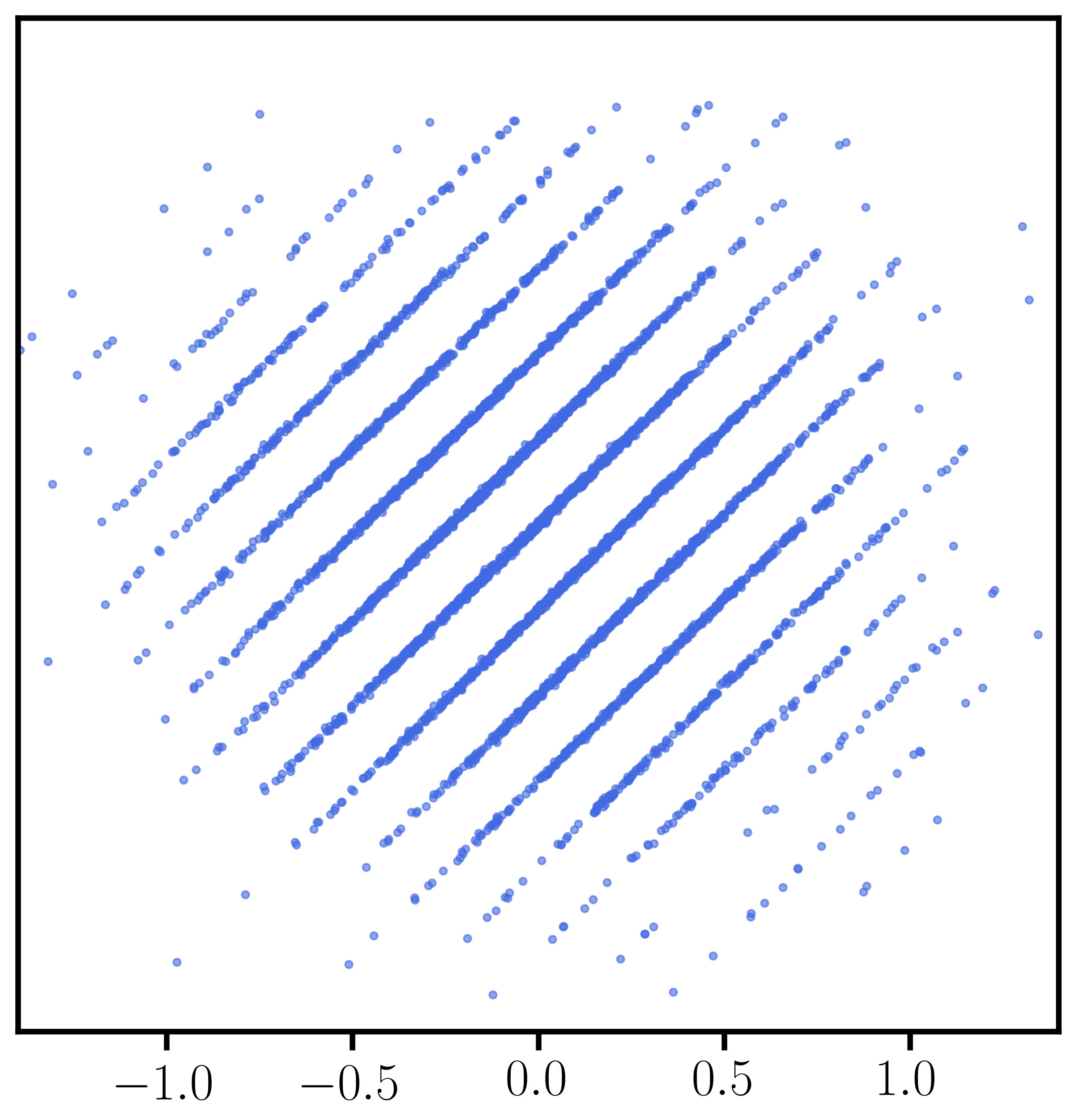
We show that $L^2$-accurate score estimation, in the absence of strong assumptions on the data distribution, is computationally hard even when sample complexity is polynomial in the relevant problem parameters. Our reduction builds on the result of Chen et al. (ICLR 2023), who showed that the problem of generating samples from an unknown data distribution reduces to $L^2$-accurate score estimation. Our hard-to-estimate distributions are the Gaussian pancakes distributions, originally due to Diakonikolas et al. (FOCS 2017), which have been shown to be computationally indistinguishable from the standard Gaussian under widely believed hardness assumptions from lattice-based cryptography (Bruna et al., STOC 2021; Gupte et al., FOCS 2022).
Read more4/5/2024
🧠
0
From optimal score matching to optimal sampling
Zehao Dou, Subhodh Kotekal, Zhehao Xu, Harrison H. Zhou
The recent, impressive advances in algorithmic generation of high-fidelity image, audio, and video are largely due to great successes in score-based diffusion models. A key implementing step is score matching, that is, the estimation of the score function of the forward diffusion process from training data. As shown in earlier literature, the total variation distance between the law of a sample generated from the trained diffusion model and the ground truth distribution can be controlled by the score matching risk. Despite the widespread use of score-based diffusion models, basic theoretical questions concerning exact optimal statistical rates for score estimation and its application to density estimation remain open. We establish the sharp minimax rate of score estimation for smooth, compactly supported densities. Formally, given (n) i.i.d. samples from an unknown (alpha)-H{o}lder density (f) supported on ([-1, 1]), we prove the minimax rate of estimating the score function of the diffused distribution (f * mathcal{N}(0, t)) with respect to the score matching loss is (frac{1}{nt^2} wedge frac{1}{nt^{3/2}} wedge (t^{alpha-1} + n^{-2(alpha-1)/(2alpha+1)})) for all (alpha > 0) and (t ge 0). As a consequence, it is shown the law (hat{f}) of a sample generated from the diffusion model achieves the sharp minimax rate (bE(dTV(hat{f}, f)^2) lesssim n^{-2alpha/(2alpha+1)}) for all (alpha > 0) without any extraneous logarithmic terms which are prevalent in the literature, and without the need for early stopping which has been required for all existing procedures to the best of our knowledge.
Read more9/12/2024
0
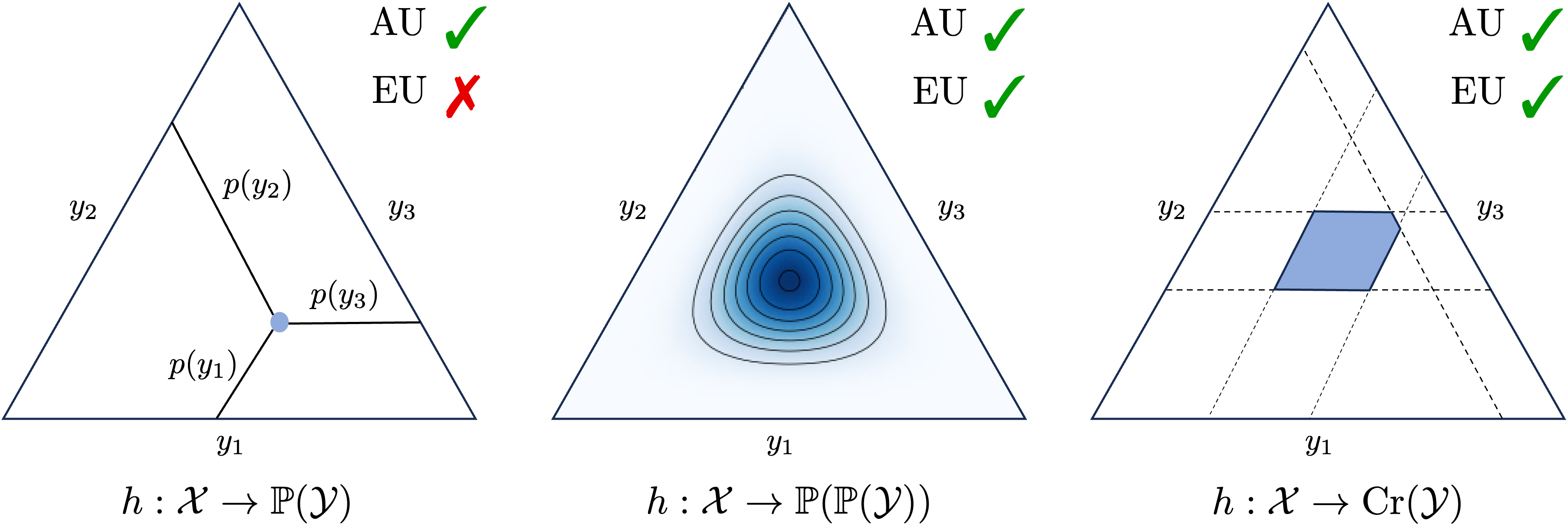
Quantifying Aleatoric and Epistemic Uncertainty with Proper Scoring Rules
Paul Hofman, Yusuf Sale, Eyke Hullermeier
Uncertainty representation and quantification are paramount in machine learning and constitute an important prerequisite for safety-critical applications. In this paper, we propose novel measures for the quantification of aleatoric and epistemic uncertainty based on proper scoring rules, which are loss functions with the meaningful property that they incentivize the learner to predict ground-truth (conditional) probabilities. We assume two common representations of (epistemic) uncertainty, namely, in terms of a credal set, i.e. a set of probability distributions, or a second-order distribution, i.e., a distribution over probability distributions. Our framework establishes a natural bridge between these representations. We provide a formal justification of our approach and introduce new measures of epistemic and aleatoric uncertainty as concrete instantiations.
Read more4/22/2024
0
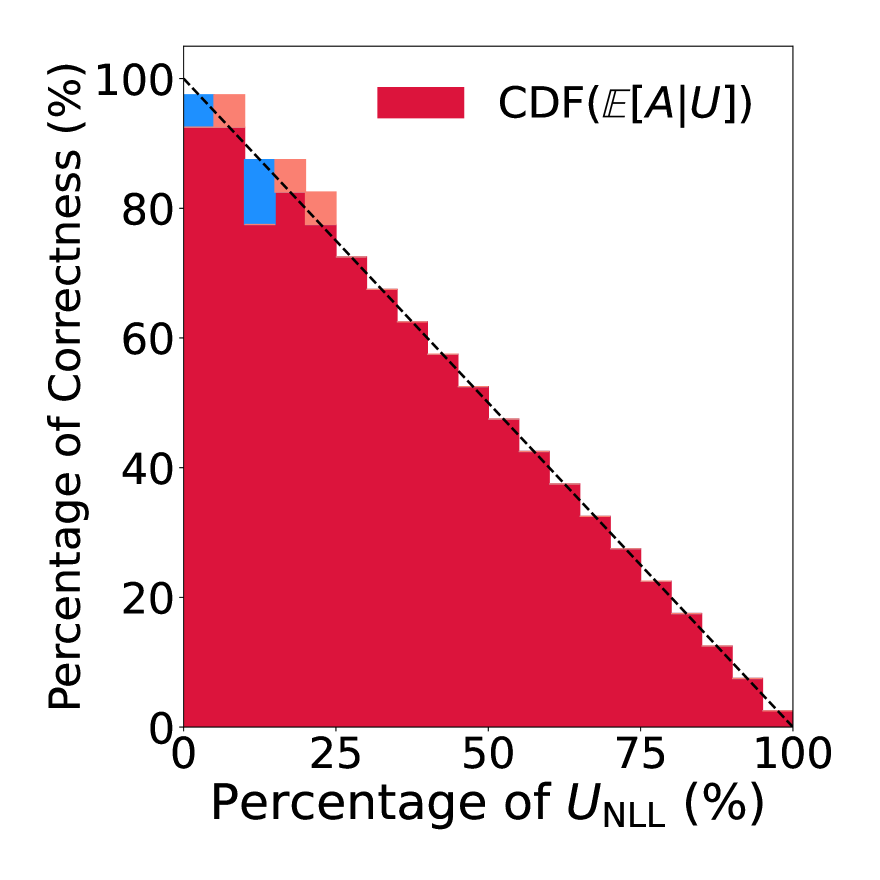
Uncertainty in Language Models: Assessment through Rank-Calibration
Xinmeng Huang, Shuo Li, Mengxin Yu, Matteo Sesia, Hamed Hassani, Insup Lee, Osbert Bastani, Edgar Dobriban
Language Models (LMs) have shown promising performance in natural language generation. However, as LMs often generate incorrect or hallucinated responses, it is crucial to correctly quantify their uncertainty in responding to given inputs. In addition to verbalized confidence elicited via prompting, many uncertainty measures ($e.g.$, semantic entropy and affinity-graph-based measures) have been proposed. However, these measures can differ greatly, and it is unclear how to compare them, partly because they take values over different ranges ($e.g.$, $[0,infty)$ or $[0,1]$). In this work, we address this issue by developing a novel and practical framework, termed $Rank$-$Calibration$, to assess uncertainty and confidence measures for LMs. Our key tenet is that higher uncertainty (or lower confidence) should imply lower generation quality, on average. Rank-calibration quantifies deviations from this ideal relationship in a principled manner, without requiring ad hoc binary thresholding of the correctness score ($e.g.$, ROUGE or METEOR). The broad applicability and the granular interpretability of our methods are demonstrated empirically.
Read more9/17/2024