Uncertainty in Language Models: Assessment through Rank-Calibration
2404.03163
0
0
Abstract
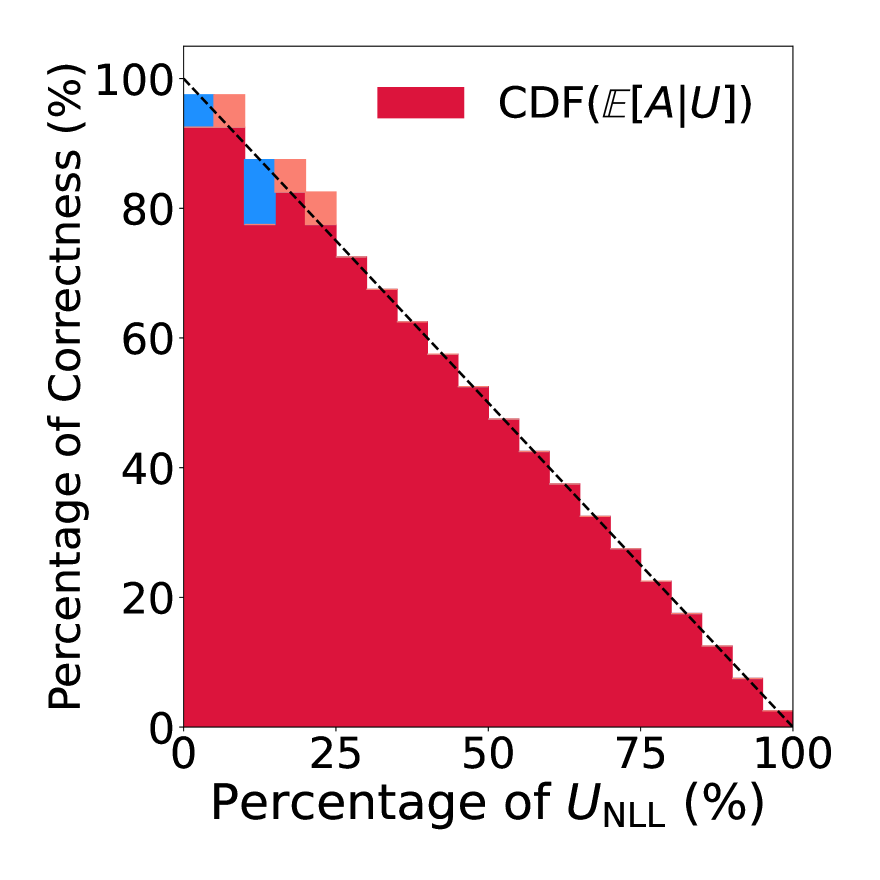
Language Models (LMs) have shown promising performance in natural language generation. However, as LMs often generate incorrect or hallucinated responses, it is crucial to correctly quantify their uncertainty in responding to given inputs. In addition to verbalized confidence elicited via prompting, many uncertainty measures ($e.g.$, semantic entropy and affinity-graph-based measures) have been proposed. However, these measures can differ greatly, and it is unclear how to compare them, partly because they take values over different ranges ($e.g.$, $[0,infty)$ or $[0,1]$). In this work, we address this issue by developing a novel and practical framework, termed $Rank$-$Calibration$, to assess uncertainty and confidence measures for LMs. Our key tenet is that higher uncertainty (or lower confidence) should imply lower generation quality, on average. Rank-calibration quantifies deviations from this ideal relationship in a principled manner, without requiring ad hoc binary thresholding of the correctness score ($e.g.$, ROUGE or METEOR). The broad applicability and the granular interpretability of our methods are demonstrated empirically.
Create account to get full access
Overview
- The paper explores ways to assess the uncertainty of language models (LMs) using a technique called "rank-calibration"
- It identifies limitations in existing approaches for evaluating LM correctness and uncertainty
- The paper proposes a new assessment framework that provides a more nuanced understanding of LM capabilities and limitations
Plain English Explanation
Language models (LMs) are AI systems that can generate human-like text. They are trained on massive amounts of text data and can be used for tasks like language translation, summarization, and answering questions. However, it's important to understand not just how accurate LMs are, but also how certain they are about their outputs.
The researchers in this paper found that existing methods for evaluating LM correctness and uncertainty have important limitations. For example, simply looking at the model's predicted probability for the correct answer doesn't fully capture its uncertainty. The researchers propose a new approach called "rank-calibration" that provides a more nuanced way to assess an LM's understanding and confidence.
Rank-calibration looks at not just the model's top prediction, but also how it ranks the alternatives. A highly uncertain model may still predict the correct answer, but it will also assign similar probabilities to other plausible options. By analyzing the full ranking, the researchers can get a better sense of the model's true level of certainty.
Using this new framework, the researchers were able to uncover interesting insights about the strengths and weaknesses of different language models. For example, they found that large, powerful LMs like GPT-3 are often overconfident, assigning unrealistically high probabilities to their top predictions even when they are wrong. In contrast, smaller models may be more appropriately uncertain about their outputs.
Understanding the uncertainty of language models is crucial as they become more widely deployed in real-world applications. The rank-calibration approach provides a valuable new tool for probing the inner workings of these AI systems and ensuring they are used in a responsible and transparent manner.
Technical Explanation
The paper begins by discussing the importance of assessing both the correctness and uncertainty of language models (LMs). While existing evaluation metrics like accuracy and perplexity provide some insights, the authors argue that they have important limitations.
To address this, the paper introduces a new assessment framework based on "rank-calibration." This approach looks not just at the model's top prediction, but also how it ranks the alternatives. The key idea is that a highly uncertain model will often assign similar probabilities to multiple plausible options, rather than concentrating all of its confidence in a single answer.
The authors conduct extensive experiments using a variety of LM architectures, including GPT-3, BART, and T5. They evaluate the models on a suite of question-answering and language understanding tasks, comparing their rank-calibration profiles to traditional metrics like accuracy.
The results reveal interesting patterns. For example, the authors find that large, powerful LMs like GPT-3 tend to be overconfident, assigning unrealistically high probabilities to their top predictions even when they are incorrect. In contrast, smaller models may be more appropriately uncertain about their outputs.
The paper also discusses the limitations of the rank-calibration approach, noting that it relies on having access to the full ranking of model outputs, which may not always be feasible in real-world applications. Additionally, the authors acknowledge that their analysis is focused on a limited set of tasks and datasets, and further research is needed to fully understand the uncertainty characteristics of LMs in diverse real-world scenarios.
Critical Analysis
The rank-calibration framework proposed in this paper represents a valuable addition to the toolkit for evaluating language models. By looking beyond just the top prediction and analyzing the full ranking of outputs, the approach provides a more nuanced understanding of an LM's capabilities and limitations.
One of the key insights from the paper is the discovery that large, powerful LMs like GPT-3 can be overconfident in their predictions, even when they are incorrect. This is an important finding, as it highlights the need for caution when deploying these models in high-stakes applications where accurate uncertainty quantification is crucial.
However, it's worth noting that the paper's analysis is focused on a relatively narrow set of tasks and datasets. While the authors acknowledge this limitation, it raises questions about the broader applicability of the rank-calibration approach. Further research is needed to understand how LM uncertainty profiles may vary across different domains and use cases.
Additionally, the reliance on having access to the full ranking of model outputs could be a practical limitation in real-world settings, where only the top prediction may be available. The authors briefly discuss this issue, but more work is needed to explore alternative approaches that can provide useful uncertainty assessments without requiring the complete output ranking.
Overall, this paper makes a valuable contribution to the ongoing efforts to better understand and evaluate the capabilities and limitations of language models. The rank-calibration framework represents an important step forward, but there is still much work to be done to ensure these powerful AI systems are deployed in a responsible and transparent manner.
Conclusion
This paper introduces a new framework for assessing the uncertainty of language models (LMs) using a technique called "rank-calibration." By looking beyond just the top prediction and analyzing how the model ranks the alternatives, the researchers were able to uncover important insights about the strengths and weaknesses of different LM architectures.
The key finding is that large, powerful LMs like GPT-3 can be overconfident in their outputs, assigning unrealistically high probabilities to their top predictions even when they are incorrect. In contrast, smaller models may be more appropriately uncertain about their capabilities.
These insights have important implications for the responsible deployment of language models in real-world applications, where accurate uncertainty quantification is crucial. The rank-calibration approach provides a valuable new tool for probing the inner workings of these AI systems and ensuring they are used in a transparent and trustworthy manner.
While the paper represents an important step forward, the authors acknowledge that further research is needed to fully understand the uncertainty characteristics of LMs across diverse domains and use cases. Continued efforts in this direction will be crucial as language models become increasingly integrated into our daily lives and decision-making processes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
On Subjective Uncertainty Quantification and Calibration in Natural Language Generation
Ziyu Wang, Chris Holmes
0
0
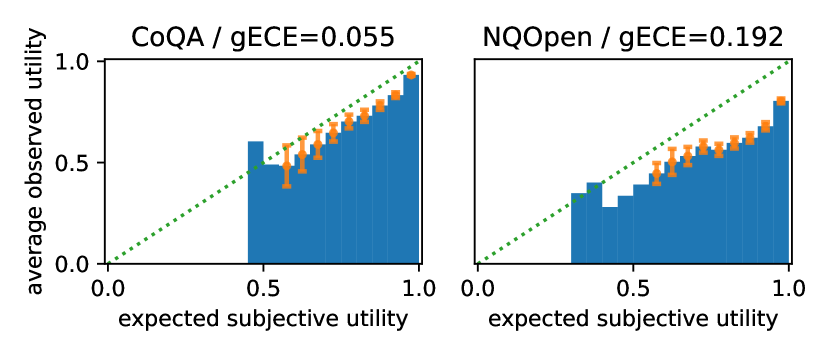
Applications of large language models often involve the generation of free-form responses, in which case uncertainty quantification becomes challenging. This is due to the need to identify task-specific uncertainties (e.g., about the semantics) which appears difficult to define in general cases. This work addresses these challenges from a perspective of Bayesian decision theory, starting from the assumption that our utility is characterized by a similarity measure that compares a generated response with a hypothetical true response. We discuss how this assumption enables principled quantification of the model's subjective uncertainty and its calibration. We further derive a measure for epistemic uncertainty, based on a missing data perspective and its characterization as an excess risk. The proposed measures can be applied to black-box language models. We demonstrate the proposed methods on question answering and machine translation tasks, where they extract broadly meaningful uncertainty estimates from GPT and Gemini models and quantify their calibration.
6/11/2024
💬
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models
Zhen Lin, Shubhendu Trivedi, Jimeng Sun
0
0
Large language models (LLMs) specializing in natural language generation (NLG) have recently started exhibiting promising capabilities across a variety of domains. However, gauging the trustworthiness of responses generated by LLMs remains an open challenge, with limited research on uncertainty quantification (UQ) for NLG. Furthermore, existing literature typically assumes white-box access to language models, which is becoming unrealistic either due to the closed-source nature of the latest LLMs or computational constraints. In this work, we investigate UQ in NLG for *black-box* LLMs. We first differentiate *uncertainty* vs *confidence*: the former refers to the ``dispersion'' of the potential predictions for a fixed input, and the latter refers to the confidence on a particular prediction/generation. We then propose and compare several confidence/uncertainty measures, applying them to *selective NLG* where unreliable results could either be ignored or yielded for further assessment. Experiments were carried out with several popular LLMs on question-answering datasets (for evaluation purposes). Results reveal that a simple measure for the semantic dispersion can be a reliable predictor of the quality of LLM responses, providing valuable insights for practitioners on uncertainty management when adopting LLMs. The code to replicate our experiments is available at https://github.com/zlin7/UQ-NLG.
5/21/2024
💬
Prediction-Powered Ranking of Large Language Models
Ivi Chatzi, Eleni Straitouri, Suhas Thejaswi, Manuel Gomez Rodriguez
0
0
Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a (small) set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with the distribution of human pairwise preferences asymptotically. Using pairwise comparisons made by humans in the LMSYS Chatbot Arena platform and pairwise comparisons made by three strong large language models, we empirically demonstrate the effectivity of our framework and show that the rank-sets constructed using only pairwise comparisons by the strong large language models are often inconsistent with (the distribution of) human pairwise preferences.
5/24/2024

An Empirical Study Into What Matters for Calibrating Vision-Language Models
Weijie Tu, Weijian Deng, Dylan Campbell, Stephen Gould, Tom Gedeon
0
0
Vision-Language Models (VLMs) have emerged as the dominant approach for zero-shot recognition, adept at handling diverse scenarios and significant distribution changes. However, their deployment in risk-sensitive areas requires a deeper understanding of their uncertainty estimation capabilities, a relatively uncharted area. In this study, we explore the calibration properties of VLMs across different architectures, datasets, and training strategies. In particular, we analyze the uncertainty estimation performance of VLMs when calibrated in one domain, label set or hierarchy level, and tested in a different one. Our findings reveal that while VLMs are not inherently calibrated for uncertainty, temperature scaling significantly and consistently improves calibration, even across shifts in distribution and changes in label set. Moreover, VLMs can be calibrated with a very small set of examples. Through detailed experimentation, we highlight the potential applications and importance of our insights, aiming for more reliable and effective use of VLMs in critical, real-world scenarios.
6/17/2024