CubicML: Automated ML for Distributed ML Systems Co-design with ML Prediction of Performance

0

Sign in to get full access
Overview
- The paper introduces CubicML, an automated machine learning (AutoML) framework for distributed machine learning (ML) systems.
- CubicML aims to automate the co-design of ML models and distributed ML systems to optimize performance.
- The framework uses ML-based performance prediction to guide the co-design process.
Plain English Explanation
CubicML: Automated ML for Distributed ML Systems Co-design with ML Prediction of Performance describes a new approach to building effective machine learning (ML) systems. Typically, ML models and the underlying computing infrastructure are designed separately. This can lead to suboptimal performance, as the models may not be well-suited for the available hardware and network resources.
The CubicML framework tackles this problem by automating the co-design of the ML models and the distributed computing system that runs them. This means the framework can simultaneously optimize the machine learning algorithms and the computational resources they'll run on, to get the best overall performance.
A key part of CubicML is its use of machine learning to predict the performance of different model and system configurations. This allows the framework to explore many potential design options and choose the one that's predicted to work best, without having to actually test them all. The performance prediction model is itself trained using machine learning, so it gets better over time at forecasting real-world performance.
By automating the co-design of models and systems, CubicML aims to make it easier to build high-performing distributed ML applications, without requiring deep expertise in both machine learning and distributed systems.
Technical Explanation
CubicML: Automated ML for Distributed ML Systems Co-design with ML Prediction of Performance presents a framework that jointly optimizes machine learning (ML) models and the distributed computing infrastructure they run on.
The core idea is to leverage machine learning itself to guide the co-design process. CubicML uses a performance prediction model, also built with ML techniques, to forecast the runtime performance of different combinations of ML models and distributed system configurations. This allows the framework to explore a large design space and identify the optimal co-design, without having to physically test every possibility.
The CubicML workflow consists of three main steps:
- Model Encoding: The ML model architecture is encoded into a numerical representation that can be used by the performance prediction model.
- Infrastructure Encoding: The key properties of the distributed computing infrastructure, such as hardware specs and network topology, are also encoded numerically.
- Performance Prediction and Optimization: The encoded model and infrastructure information is fed into the performance prediction model, which outputs a predicted runtime. An optimization algorithm then searches for the best co-design that maximizes performance.
The authors demonstrate CubicML on several real-world distributed ML tasks, showing that it can outperform traditional approaches that design models and systems separately.
Critical Analysis
The CubicML paper presents a promising approach to the challenge of co-designing ML models and distributed computing systems. By using machine learning to predict performance, the framework can efficiently explore a large design space without extensive empirical testing.
However, the authors acknowledge some limitations. The performance prediction model may not perfectly capture all the complexities of real-world distributed systems, so its predictions could have errors. Additionally, the encoding schemes used for models and infrastructure may not be able to capture all the relevant details that impact performance.
Further research could explore ways to improve the robustness and accuracy of the performance prediction, perhaps by incorporating more system-level details or using more advanced ML techniques. It would also be valuable to test CubicML on a wider range of distributed ML applications to better understand its strengths and weaknesses.
Overall, the CubicML framework represents an interesting step towards streamlining the development of high-performing distributed ML systems. As machine learning continues to advance, techniques like this may become increasingly important for building efficient, scalable AI applications.
Conclusion
CubicML: Automated ML for Distributed ML Systems Co-design with ML Prediction of Performance introduces an innovative framework that jointly optimizes machine learning models and the distributed computing infrastructure they run on. By using machine learning to predict the runtime performance of different co-design options, CubicML can efficiently explore a large design space without extensive empirical testing.
This approach has the potential to make it much easier to build high-performing distributed ML applications, without requiring deep expertise in both machine learning and distributed systems. While the framework has some limitations, the core idea of using ML-based performance prediction to guide system co-design represents an interesting advance in the field of automated machine learning.
As AI continues to grow more powerful and prevalent, techniques like CubicML may become increasingly important for developing efficient, scalable machine learning systems that can be widely deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CubicML: Automated ML for Distributed ML Systems Co-design with ML Prediction of Performance
Wei Wen, Quanyu Zhu, Weiwei Chu, Wen-Yen Chen, Jiyan Yang
Scaling up deep learning models has been proven effective to improve intelligence of machine learning (ML) models, especially for industry recommendation models and large language models. The co-design of distributed ML systems and algorithms (to maximize training performance) plays a pivotal role for its success. As it scales, the number of co-design hyper-parameters grows rapidly which brings challenges to feasibly find the optimal setup for system performance maximization. In this paper, we propose CubicML which uses ML to automatically optimize training performance of distributed ML systems. In CubicML, we use a ML model as a proxy to predict the training performance for search efficiency and performance modeling flexibility. We proved that CubicML can effectively optimize training speed of in-house ads recommendation models and large language models at Meta.
Read more9/10/2024

0
Performance Modeling and Workload Analysis of Distributed Large Language Model Training and Inference
Joyjit Kundu, Wenzhe Guo, Ali BanaGozar, Udari De Alwis, Sourav Sengupta, Puneet Gupta, Arindam Mallik
Aligning future system design with the ever-increasing compute needs of large language models (LLMs) is undoubtedly an important problem in today's world. Here, we propose a general performance modeling methodology and workload analysis of distributed LLM training and inference through an analytical framework that accurately considers compute, memory sub-system, network, and various parallelization strategies (model parallel, data parallel, pipeline parallel, and sequence parallel). We validate our performance predictions with published data from literature and relevant industry vendors (e.g., NVIDIA). For distributed training, we investigate the memory footprint of LLMs for different activation re-computation methods, dissect the key factors behind the massive performance gain from A100 to B200 ($sim$ 35x speed-up closely following NVIDIA's scaling trend), and further run a design space exploration at different technology nodes (12 nm to 1 nm) to study the impact of logic, memory, and network scaling on the performance. For inference, we analyze the compute versus memory boundedness of different operations at a matrix-multiply level for different GPU systems and further explore the impact of DRAM memory technology scaling on inference latency. Utilizing our modeling framework, we reveal the evolution of performance bottlenecks for both LLM training and inference with technology scaling, thus, providing insights to design future systems for LLM training and inference.
Read more7/23/2024
0
Fast and Private Inference of Deep Neural Networks by Co-designing Activation Functions
Abdulrahman Diaa, Lucas Fenaux, Thomas Humphries, Marian Dietz, Faezeh Ebrahimianghazani, Bailey Kacsmar, Xinda Li, Nils Lukas, Rasoul Akhavan Mahdavi, Simon Oya, Ehsan Amjadian, Florian Kerschbaum
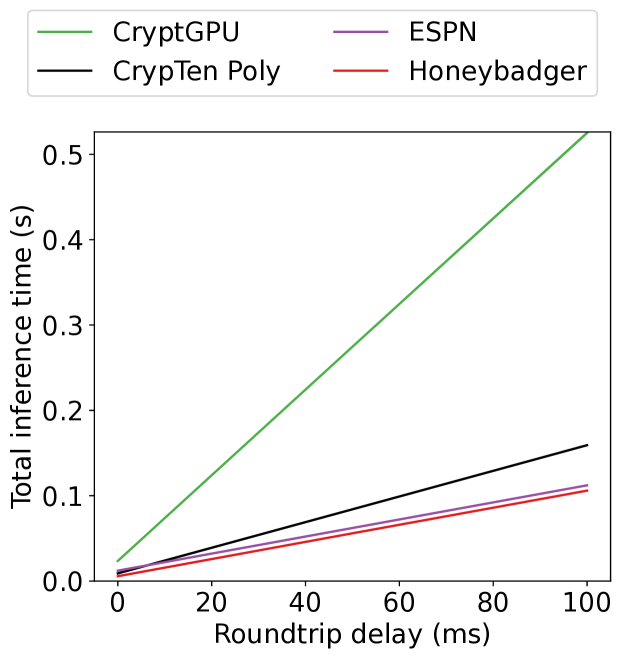
Machine Learning as a Service (MLaaS) is an increasingly popular design where a company with abundant computing resources trains a deep neural network and offers query access for tasks like image classification. The challenge with this design is that MLaaS requires the client to reveal their potentially sensitive queries to the company hosting the model. Multi-party computation (MPC) protects the client's data by allowing encrypted inferences. However, current approaches suffer from prohibitively large inference times. The inference time bottleneck in MPC is the evaluation of non-linear layers such as ReLU activation functions. Motivated by the success of previous work co-designing machine learning and MPC, we develop an activation function co-design. We replace all ReLUs with a polynomial approximation and evaluate them with single-round MPC protocols, which give state-of-the-art inference times in wide-area networks. Furthermore, to address the accuracy issues previously encountered with polynomial activations, we propose a novel training algorithm that gives accuracy competitive with plaintext models. Our evaluation shows between $3$ and $110times$ speedups in inference time on large models with up to $23$ million parameters while maintaining competitive inference accuracy.
Read more4/17/2024
0
A Survey of Distributed Learning in Cloud, Mobile, and Edge Settings
Madison Threadgill, Andreas Gerstlauer
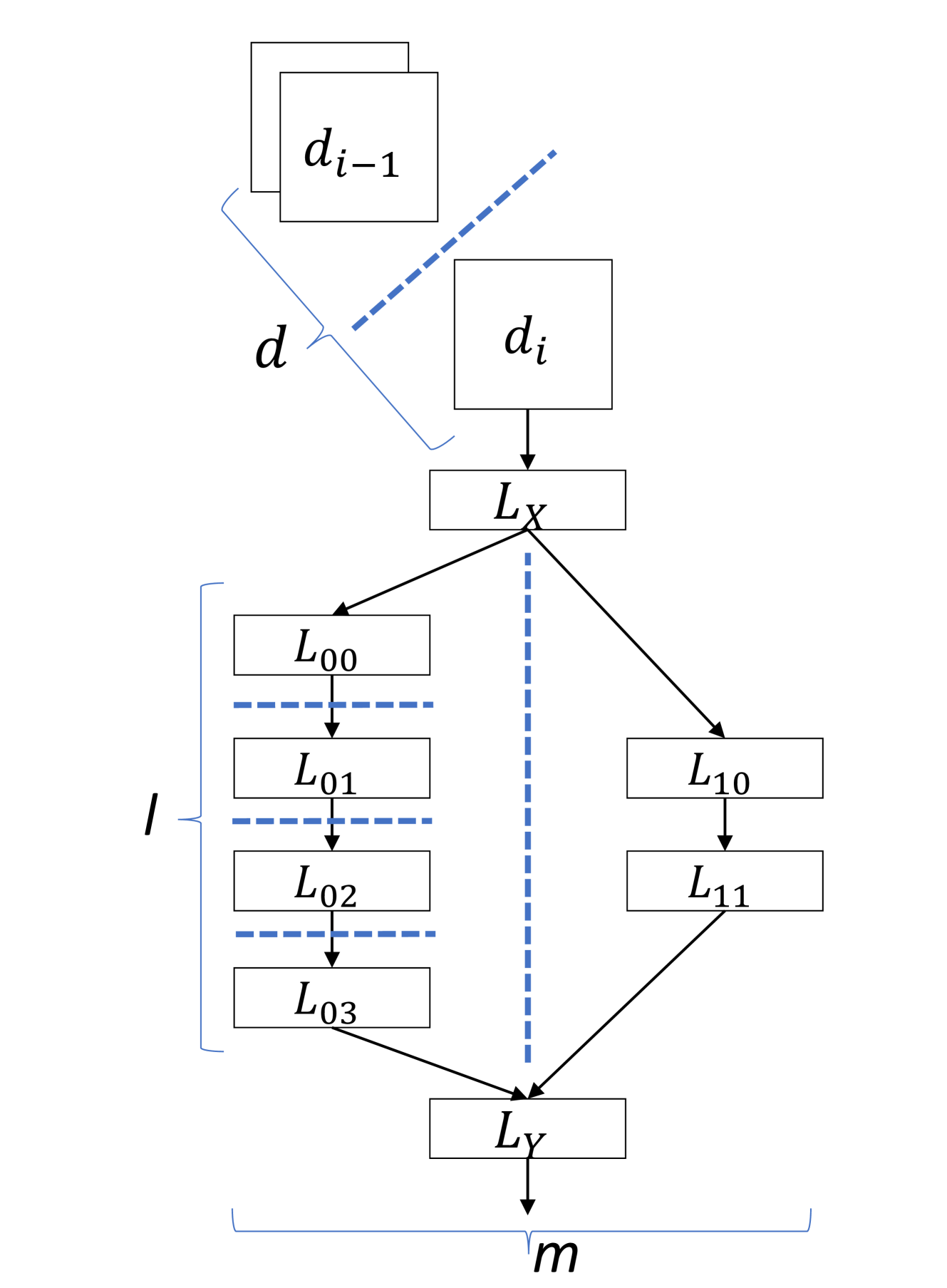
In the era of deep learning (DL), convolutional neural networks (CNNs), and large language models (LLMs), machine learning (ML) models are becoming increasingly complex, demanding significant computational resources for both inference and training stages. To address this challenge, distributed learning has emerged as a crucial approach, employing parallelization across various devices and environments. This survey explores the landscape of distributed learning, encompassing cloud and edge settings. We delve into the core concepts of data and model parallelism, examining how models are partitioned across different dimensions and layers to optimize resource utilization and performance. We analyze various partitioning schemes for different layer types, including fully connected, convolutional, and recurrent layers, highlighting the trade-offs between computational efficiency, communication overhead, and memory constraints. This survey provides valuable insights for future research and development in this rapidly evolving field by comparing and contrasting distributed learning approaches across diverse contexts.
Read more5/27/2024