Performance Modeling and Workload Analysis of Distributed Large Language Model Training and Inference

0

Sign in to get full access
Overview
- Examines the performance and workload of distributed training and inference of large language models (LLMs)
- Explores scaling challenges and efficiency optimization opportunities for LLM deployment
- Provides insights into the resource requirements and performance characteristics of LLM workloads
Plain English Explanation
This research paper investigates the performance and workload characteristics of training and deploying large language models (LLMs) in distributed computing environments. LLMs, such as GPT-3, have become increasingly prominent in natural language processing tasks, but their high computational and memory demands present scalability challenges.
The paper aims to provide a better understanding of the resource requirements and performance dynamics of LLM workloads. By analyzing the performance and efficiency of distributed LLM training and inference, the researchers identify optimization opportunities to improve the deployment of these powerful AI models.
Technical Explanation
The paper presents a comprehensive analysis of LLM performance, including experiments on distributed training and inference using various hardware configurations and workload patterns. The researchers developed a performance modeling framework to capture the complex relationships between LLM characteristics, hardware resources, and workload dynamics.
The experiments explored the scaling behavior of LLM training, evaluating factors such as model size, batch size, and the number of GPUs. The researchers also analyzed LLM inference performance on CPU-based platforms, investigating the impact of factors like batch size, parallelism, and model complexity.
The findings provide insights into the resource requirements and efficiency trade-offs associated with LLM workloads. The paper also discusses strategies for optimizing LLM deployment, such as workload-aware resource allocation and performance modeling techniques.
Critical Analysis
The paper offers a comprehensive and insightful analysis of LLM performance in distributed computing environments. The researchers have demonstrated a robust experimental approach and developed a performance modeling framework that can capture the complexity of LLM workloads.
One potential limitation of the study is the focus on specific hardware configurations and LLM architectures. While the insights provided are valuable, the findings may not be directly applicable to all LLM deployments, as hardware and model characteristics can vary significantly.
Additionally, the paper does not delve deeply into the implications of the optimization strategies it proposes. Further research may be needed to assess the practical implementation challenges and the broader impact of these techniques on LLM deployment and the AI ecosystem as a whole.
Conclusion
This research paper provides valuable insights into the performance and workload characteristics of distributed LLM training and inference. By understanding the resource requirements and efficiency trade-offs associated with LLM workloads, the findings can inform the development of more scalable and optimized LLM deployment strategies.
The insights presented in this paper have the potential to contribute to the ongoing efforts to make LLMs more accessible and practical for a wide range of applications, ultimately advancing the field of natural language processing and AI technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Performance Modeling and Workload Analysis of Distributed Large Language Model Training and Inference
Joyjit Kundu, Wenzhe Guo, Ali BanaGozar, Udari De Alwis, Sourav Sengupta, Puneet Gupta, Arindam Mallik
Aligning future system design with the ever-increasing compute needs of large language models (LLMs) is undoubtedly an important problem in today's world. Here, we propose a general performance modeling methodology and workload analysis of distributed LLM training and inference through an analytical framework that accurately considers compute, memory sub-system, network, and various parallelization strategies (model parallel, data parallel, pipeline parallel, and sequence parallel). We validate our performance predictions with published data from literature and relevant industry vendors (e.g., NVIDIA). For distributed training, we investigate the memory footprint of LLMs for different activation re-computation methods, dissect the key factors behind the massive performance gain from A100 to B200 ($sim$ 35x speed-up closely following NVIDIA's scaling trend), and further run a design space exploration at different technology nodes (12 nm to 1 nm) to study the impact of logic, memory, and network scaling on the performance. For inference, we analyze the compute versus memory boundedness of different operations at a matrix-multiply level for different GPU systems and further explore the impact of DRAM memory technology scaling on inference latency. Utilizing our modeling framework, we reveal the evolution of performance bottlenecks for both LLM training and inference with technology scaling, thus, providing insights to design future systems for LLM training and inference.
Read more7/23/2024

0
Distributed Inference Performance Optimization for LLMs on CPUs
Pujiang He, Shan Zhou, Changqing Li, Wenhuan Huang, Weifei Yu, Duyi Wang, Chen Meng, Sheng Gui
Large language models (LLMs) hold tremendous potential for addressing numerous real-world challenges, yet they typically demand significant computational resources and memory. Deploying LLMs onto a resource-limited hardware device with restricted memory capacity presents considerable challenges. Distributed computing emerges as a prevalent strategy to mitigate single-node memory constraints and expedite LLM inference performance. To reduce the hardware limitation burden, we proposed an efficient distributed inference optimization solution for LLMs on CPUs. We conduct experiments with the proposed solution on 5th Gen Intel Xeon Scalable Processors, and the result shows the time per output token for the LLM with 72B parameter is 140 ms/token, much faster than the average human reading speed about 200ms per token.
Read more7/2/2024

0
Efficient Training of Large Language Models on Distributed Infrastructures: A Survey
Jiangfei Duan, Shuo Zhang, Zerui Wang, Lijuan Jiang, Wenwen Qu, Qinghao Hu, Guoteng Wang, Qizhen Weng, Hang Yan, Xingcheng Zhang, Xipeng Qiu, Dahua Lin, Yonggang Wen, Xin Jin, Tianwei Zhang, Peng Sun
Large Language Models (LLMs) like GPT and LLaMA are revolutionizing the AI industry with their sophisticated capabilities. Training these models requires vast GPU clusters and significant computing time, posing major challenges in terms of scalability, efficiency, and reliability. This survey explores recent advancements in training systems for LLMs, including innovations in training infrastructure with AI accelerators, networking, storage, and scheduling. Additionally, the survey covers parallelism strategies, as well as optimizations for computation, communication, and memory in distributed LLM training. It also includes approaches of maintaining system reliability over extended training periods. By examining current innovations and future directions, this survey aims to provide valuable insights towards improving LLM training systems and tackling ongoing challenges. Furthermore, traditional digital circuit-based computing systems face significant constraints in meeting the computational demands of LLMs, highlighting the need for innovative solutions such as optical computing and optical networks.
Read more7/30/2024
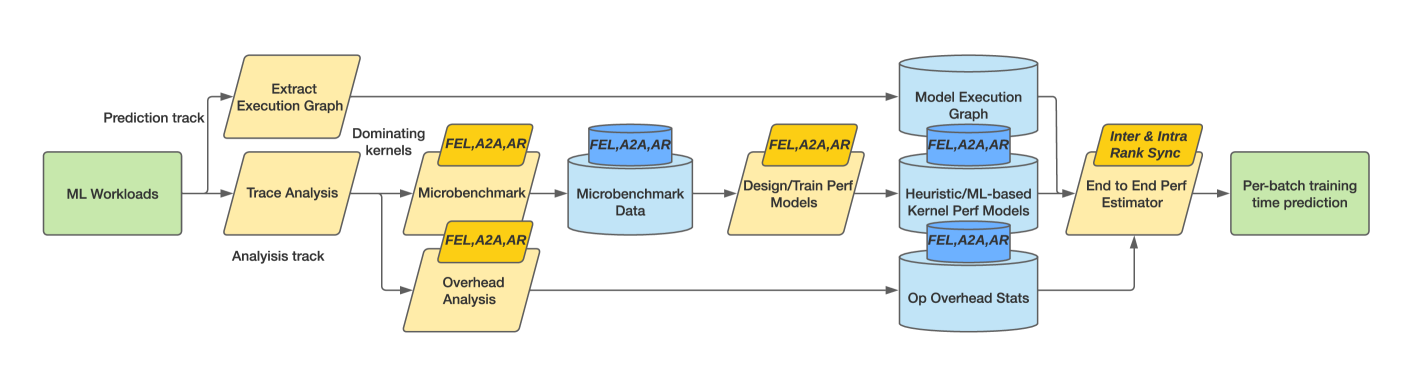
0
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, John D. Owens
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Read more4/30/2024