Cultural Value Differences of LLMs: Prompt, Language, and Model Size

0

Sign in to get full access
Overview
- This paper examines how cultural values are reflected in large language models (LLMs) based on factors like prompts, language, and model size.
- The researchers conducted experiments to understand how LLMs trained on different datasets and languages capture diverse cultural values.
- Their findings provide insights into the cultural biases and limitations of current LLM systems.
Plain English Explanation
The paper investigates how the cultural values and perspectives embedded in large language models (LLMs) can vary based on factors like the prompts used, the language the model was trained on, and the overall size of the model.
LLMs are advanced AI systems that can generate human-like text on a wide range of topics. However, the data these models are trained on can reflect certain cultural biases and norms. The researchers wanted to explore how these cultural differences manifest in the outputs of LLMs.
For example, an LLM trained on English-language data from Western countries may have different perspectives on topics like individualism, gender roles, or moral values compared to an LLM trained on data from non-Western cultures. The prompts used to interact with the model can also shape the cultural framing of the responses.
By conducting a series of experiments, the researchers found that the cultural values expressed by LLMs can indeed vary significantly based on these factors. This suggests that the developers of LLM systems need to be mindful of the cultural biases embedded in the training data and model architecture, and take steps to improve cultural inclusivity and representation.
Technical Explanation
The paper explores how cultural values are reflected in the outputs of large language models (LLMs), with a focus on the impact of prompts, language, and model size.
The researchers conducted a series of experiments to examine cultural value differences in LLM responses. They used prompts related to moral dilemmas, social norms, and personal values, and compared the outputs of LLMs trained on datasets from different cultures and languages, as well as LLMs of varying sizes.
The findings indicate that the cultural values expressed by LLMs can vary significantly based on the training data and model architecture. LLMs trained on English-language data from Western countries tended to demonstrate individualistic and egalitarian values, while those trained on non-Western languages often exhibited more collectivist and hierarchical cultural norms.
Additionally, the researchers found that larger LLM models were not necessarily more culturally inclusive, and could in some cases amplify the dominant cultural biases present in the training data. The choice of prompts also played a crucial role in shaping the cultural framing of the LLM responses.
Critical Analysis
The paper provides valuable insights into the cultural biases and limitations of current LLM systems. The findings highlight the need for AI developers to carefully consider the cultural diversity and representation within their training data and model architectures.
One potential limitation of the study is the relatively narrow set of prompts used to assess cultural values. There may be additional dimensions of cultural difference that were not captured by the specific prompts employed. Further research using a more comprehensive set of prompts could provide a more nuanced understanding of cultural value differences in LLMs.
Additionally, the paper does not delve deeply into the potential societal implications of culturally biased LLM outputs, such as the perpetuation of stereotypes or the exclusion of marginalized perspectives. Exploring these wider implications would be an important area for future research.
Overall, this paper makes a valuable contribution to the growing body of work on the cultural and social impacts of large language models. It underscores the importance of developing more culturally inclusive and representative AI systems that can engage with diverse perspectives and values.
Conclusion
This research paper sheds light on how the cultural values reflected in large language models (LLMs) can be influenced by factors such as the prompts used, the language the model was trained on, and the overall size of the model.
The findings suggest that current LLM systems may not accurately capture the full range of cultural diversity and perspectives, and that developers need to be more mindful of these cultural biases. By addressing these issues, the research has implications for improving the cultural inclusivity and representational accuracy of LLMs, which could in turn lead to more equitable and socially responsible AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cultural Value Differences of LLMs: Prompt, Language, and Model Size
Qishuai Zhong, Yike Yun, Aixin Sun
Our study aims to identify behavior patterns in cultural values exhibited by large language models (LLMs). The studied variants include question ordering, prompting language, and model size. Our experiments reveal that each tested LLM can efficiently behave with different cultural values. More interestingly: (i) LLMs exhibit relatively consistent cultural values when presented with prompts in a single language. (ii) The prompting language e.g., Chinese or English, can influence the expression of cultural values. The same question can elicit divergent cultural values when the same LLM is queried in a different language. (iii) Differences in sizes of the same model (e.g., Llama2-7B vs 13B vs 70B) have a more significant impact on their demonstrated cultural values than model differences (e.g., Llama2 vs Mixtral). Our experiments reveal that query language and model size of LLM are the main factors resulting in cultural value differences.
Read more7/25/2024

0
How Well Do LLMs Represent Values Across Cultures? Empirical Analysis of LLM Responses Based on Hofstede Cultural Dimensions
Julia Kharchenko, Tanya Roosta, Aman Chadha, Chirag Shah
Large Language Models (LLMs) attempt to imitate human behavior by responding to humans in a way that pleases them, including by adhering to their values. However, humans come from diverse cultures with different values. It is critical to understand whether LLMs showcase different values to the user based on the stereotypical values of a user's known country. We prompt different LLMs with a series of advice requests based on 5 Hofstede Cultural Dimensions -- a quantifiable way of representing the values of a country. Throughout each prompt, we incorporate personas representing 36 different countries and, separately, languages predominantly tied to each country to analyze the consistency in the LLMs' cultural understanding. Through our analysis of the responses, we found that LLMs can differentiate between one side of a value and another, as well as understand that countries have differing values, but will not always uphold the values when giving advice, and fail to understand the need to answer differently based on different cultural values. Rooted in these findings, we present recommendations for training value-aligned and culturally sensitive LLMs. More importantly, the methodology and the framework developed here can help further understand and mitigate culture and language alignment issues with LLMs.
Read more6/24/2024
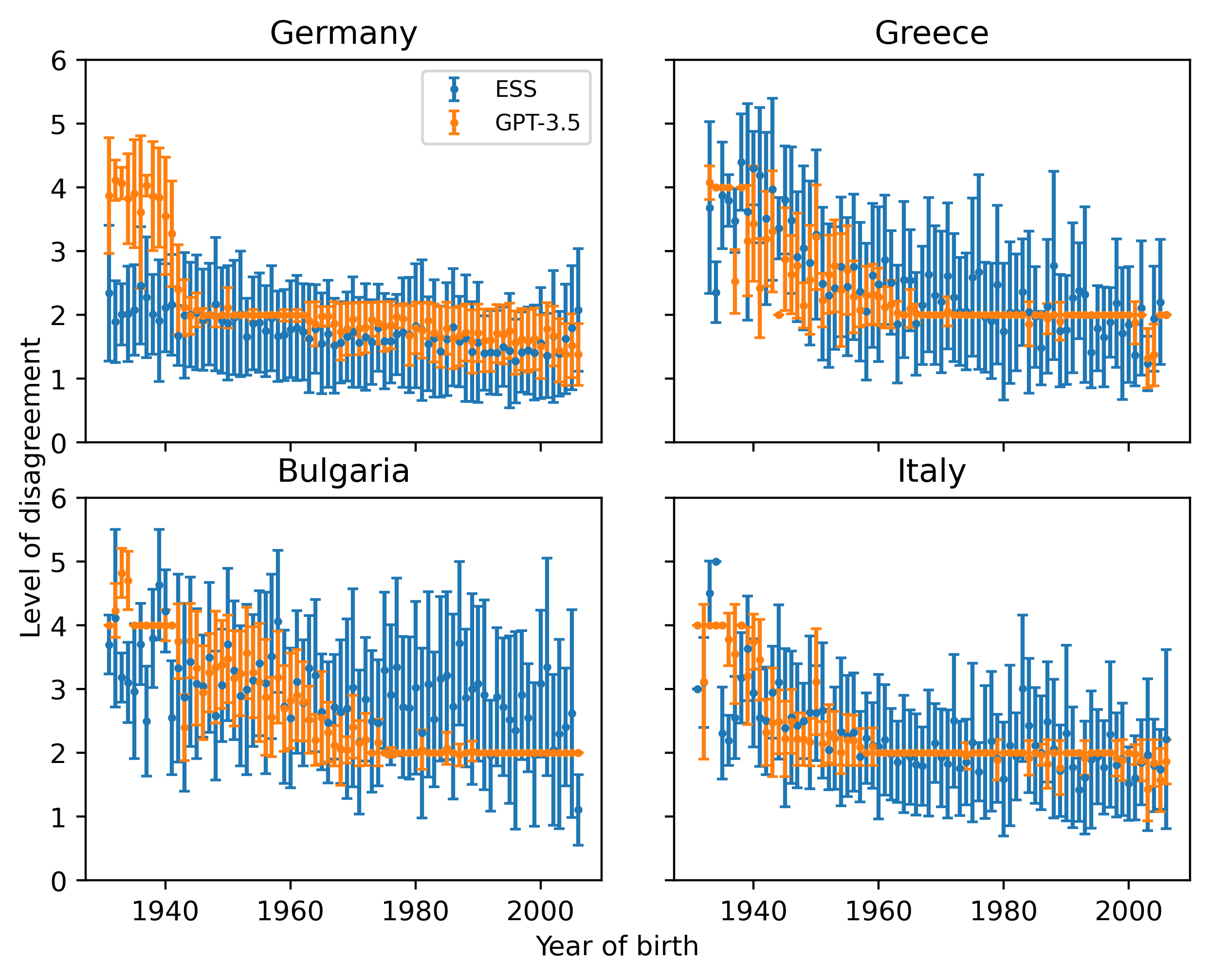
0
Are Large Language Models Chameleons?
Mingmeng Geng, Sihong He, Roberto Trotta
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
Read more5/30/2024

0
Investigating Cultural Alignment of Large Language Models
Badr AlKhamissi, Muhammad ElNokrashy, Mai AlKhamissi, Mona Diab
The intricate relationship between language and culture has long been a subject of exploration within the realm of linguistic anthropology. Large Language Models (LLMs), promoted as repositories of collective human knowledge, raise a pivotal question: do these models genuinely encapsulate the diverse knowledge adopted by different cultures? Our study reveals that these models demonstrate greater cultural alignment along two dimensions -- firstly, when prompted with the dominant language of a specific culture, and secondly, when pretrained with a refined mixture of languages employed by that culture. We quantify cultural alignment by simulating sociological surveys, comparing model responses to those of actual survey participants as references. Specifically, we replicate a survey conducted in various regions of Egypt and the United States through prompting LLMs with different pretraining data mixtures in both Arabic and English with the personas of the real respondents and the survey questions. Further analysis reveals that misalignment becomes more pronounced for underrepresented personas and for culturally sensitive topics, such as those probing social values. Finally, we introduce Anthropological Prompting, a novel method leveraging anthropological reasoning to enhance cultural alignment. Our study emphasizes the necessity for a more balanced multilingual pretraining dataset to better represent the diversity of human experience and the plurality of different cultures with many implications on the topic of cross-lingual transfer.
Read more7/9/2024