Are Large Language Models Chameleons?
2405.19323
0
0
Abstract
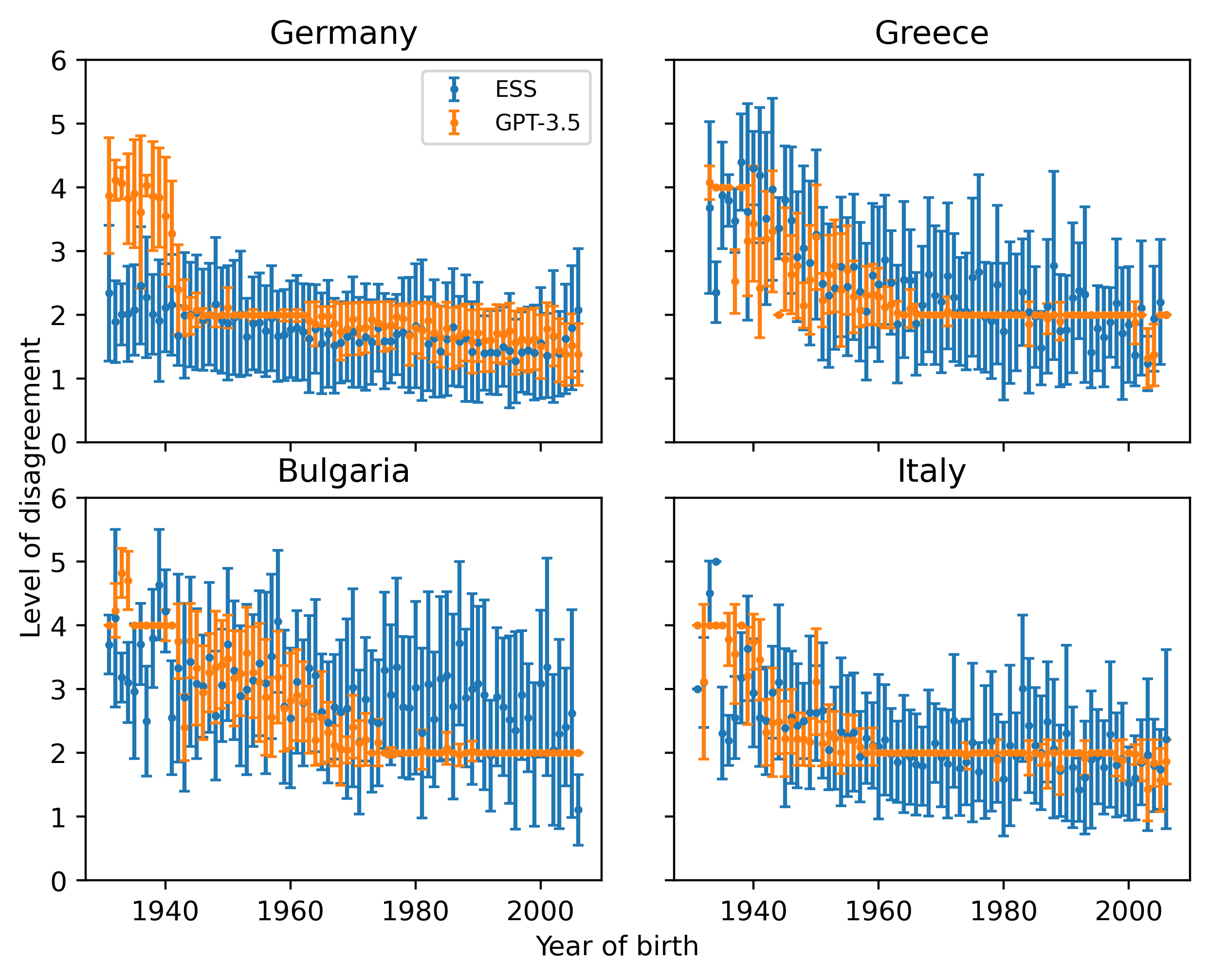
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
Create account to get full access
Overview
- This paper investigates whether large language models (LLMs) exhibit "chameleon-like" behavior, meaning they can adapt their language and behavior to match their conversational partners.
- The researchers conducted a series of experiments to explore how LLMs respond to different types of conversational prompts and partners.
- The findings suggest that LLMs can indeed modify their language and persona to some degree, but their ability to truly simulate human-like social interactions is limited.
Plain English Explanation
The paper examines whether large language models (LLMs) - powerful AI systems trained on vast amounts of text data - can adapt their language and behavior to match the people they're talking to, much like a chameleon changes its color to blend into its surroundings.
The researchers ran experiments where they gave LLMs different types of prompts and interaction partners to see how the models would respond. They found that the LLMs could modify their language to some extent, using more formal or informal styles, for example. However, the models struggled to fully simulate authentic human-like social interactions, revealing limitations in their ability to truly "become" the person they're talking to.
This research provides insights into the current capabilities and limitations of LLMs when it comes to social and interpersonal behaviors. While these models can demonstrate some chameleon-like adaptability, they still have a ways to go before they can convincingly mimic the nuanced social skills of humans.
Technical Explanation
The paper investigates the "chameleon-like" behavior of large language models (LLMs), examining their ability to adapt their language and persona to match different conversational contexts and partners.
The researchers conducted a series of experiments to test LLM responses to various prompts and interaction scenarios. This included exposing the models to different types of conversational partners (e.g., formal vs. casual), as well as prompts that encouraged the models to take on different personas or express contradictory views.
The findings suggest that LLMs can indeed modify their language to some degree, exhibiting shifts in formality, politeness, and other stylistic features. However, the models struggled to fully simulate authentic human-like social interactions, revealing limitations in their ability to model complex human psychology and interpersonal dynamics.
Critical Analysis
The paper provides valuable insights into the current capabilities and limitations of LLMs when it comes to social and interpersonal behaviors. While the models demonstrate some chameleon-like adaptability, the researchers acknowledge that their ability to truly simulate human-like social interactions is still quite limited.
One potential concern raised is the models' tendency to produce contradictory or inconsistent responses when prompted to take on different personas or viewpoints. This suggests that LLMs may struggle to maintain a coherent sense of self or identity, which could undermine their ability to engage in authentic social exchanges.
Additionally, the paper highlights the models' limited capacity to understand and respond to complex human psychological factors, such as emotions, social cues, and interpersonal dynamics. This raises questions about the suitability of LLMs for applications that require nuanced social intelligence, such as counseling or customer service.
Further research is needed to explore the underlying mechanisms driving the chameleon-like behavior of LLMs, as well as to develop more robust and socially-aware language models that can engage in truly meaningful and contextually-appropriate interactions.
Conclusion
This paper provides a thought-provoking exploration of the "chameleon-like" behavior of large language models (LLMs), investigating their ability to adapt their language and persona to different conversational contexts and partners.
The findings suggest that while LLMs can exhibit some level of linguistic and behavioral adaptability, their capacity to simulate authentic human-like social interactions is still limited. This highlights the need for continued advancements in language model development, particularly in the areas of social intelligence, coherence, and contextual awareness.
As LLMs become increasingly prevalent in various applications, understanding their strengths and limitations when it comes to social and interpersonal behaviors will be crucial for ensuring their responsible and effective deployment. This paper contributes valuable insights to this ongoing discussion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
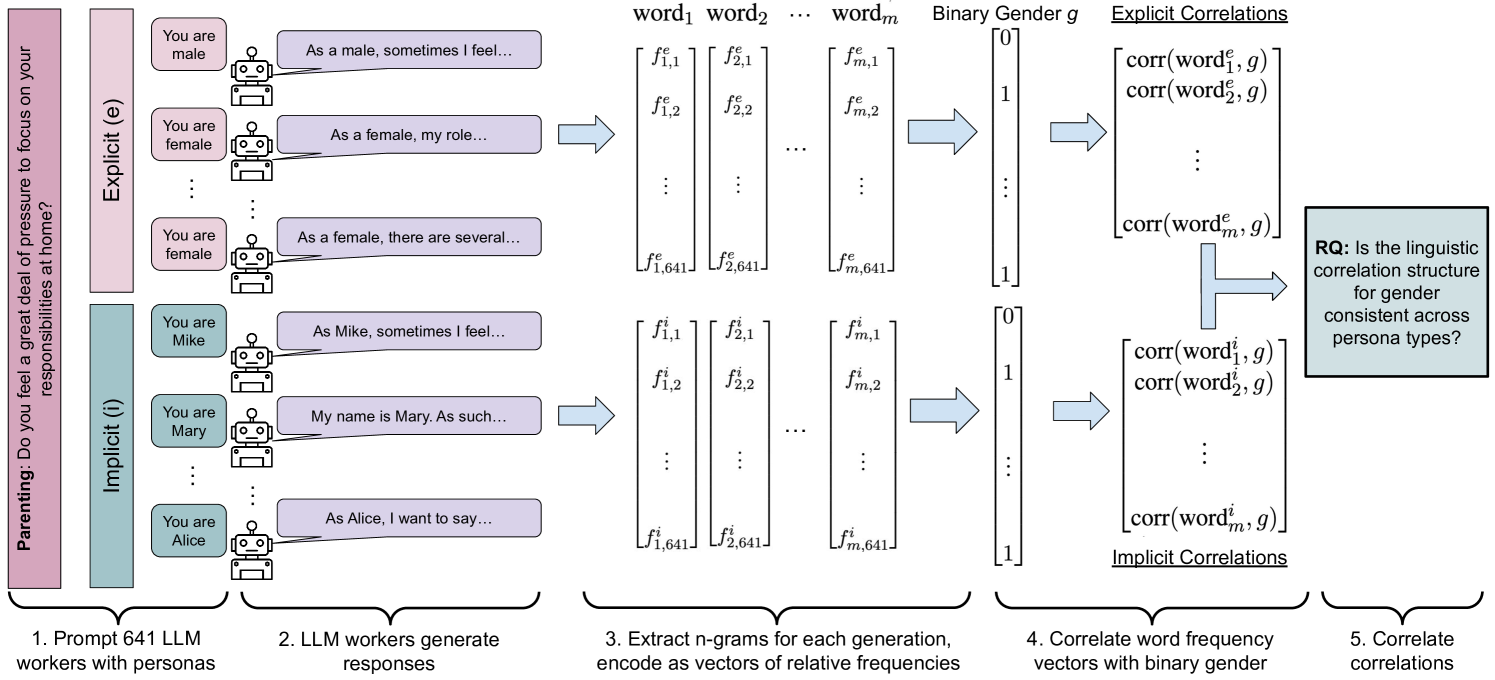
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Salvatore Giorgi, Tingting Liu, Ankit Aich, Kelsey Isman, Garrick Sherman, Zachary Fried, Jo~ao Sedoc, Lyle H. Ungar, Brenda Curtis
0
0
Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
6/21/2024
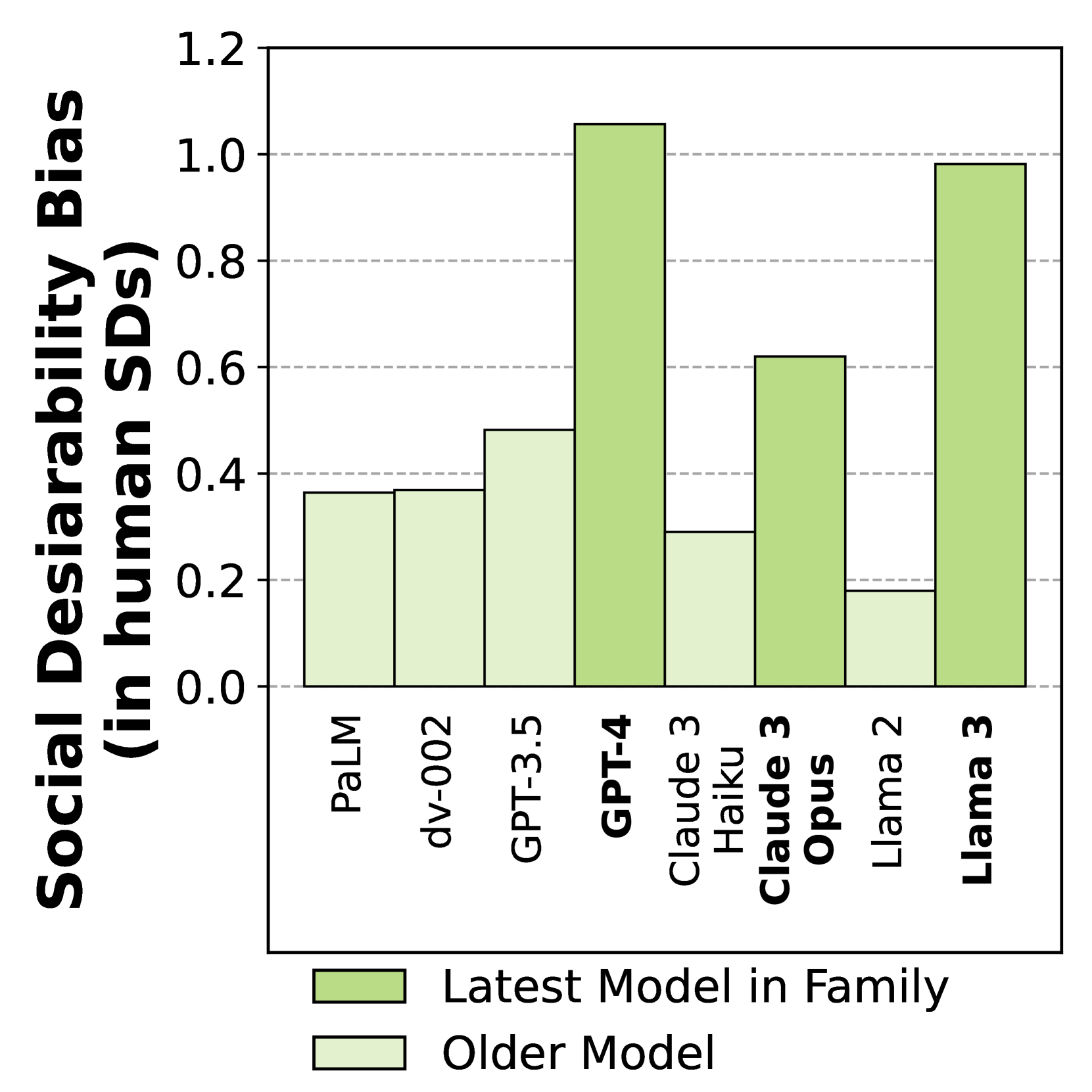
Large Language Models Show Human-like Social Desirability Biases in Survey Responses
Aadesh Salecha, Molly E. Ireland, Shashanka Subrahmanya, Jo~ao Sedoc, Lyle H. Ungar, Johannes C. Eichstaedt
0
0
As Large Language Models (LLMs) become widely used to model and simulate human behavior, understanding their biases becomes critical. We developed an experimental framework using Big Five personality surveys and uncovered a previously undetected social desirability bias in a wide range of LLMs. By systematically varying the number of questions LLMs were exposed to, we demonstrate their ability to infer when they are being evaluated. When personality evaluation is inferred, LLMs skew their scores towards the desirable ends of trait dimensions (i.e., increased extraversion, decreased neuroticism, etc). This bias exists in all tested models, including GPT-4/3.5, Claude 3, Llama 3, and PaLM-2. Bias levels appear to increase in more recent models, with GPT-4's survey responses changing by 1.20 (human) standard deviations and Llama 3's by 0.98 standard deviations-very large effects. This bias is robust to randomization of question order and paraphrasing. Reverse-coding all the questions decreases bias levels but does not eliminate them, suggesting that this effect cannot be attributed to acquiescence bias. Our findings reveal an emergent social desirability bias and suggest constraints on profiling LLMs with psychometric tests and on using LLMs as proxies for human participants.
5/13/2024
💬
You don't need a personality test to know these models are unreliable: Assessing the Reliability of Large Language Models on Psychometric Instruments
Bangzhao Shu, Lechen Zhang, Minje Choi, Lavinia Dunagan, Lajanugen Logeswaran, Moontae Lee, Dallas Card, David Jurgens
0
0
The versatility of Large Language Models (LLMs) on natural language understanding tasks has made them popular for research in social sciences. To properly understand the properties and innate personas of LLMs, researchers have performed studies that involve using prompts in the form of questions that ask LLMs about particular opinions. In this study, we take a cautionary step back and examine whether the current format of prompting LLMs elicits responses in a consistent and robust manner. We first construct a dataset that contains 693 questions encompassing 39 different instruments of persona measurement on 115 persona axes. Additionally, we design a set of prompts containing minor variations and examine LLMs' capabilities to generate answers, as well as prompt variations to examine their consistency with respect to content-level variations such as switching the order of response options or negating the statement. Our experiments on 17 different LLMs reveal that even simple perturbations significantly downgrade a model's question-answering ability, and that most LLMs have low negation consistency. Our results suggest that the currently widespread practice of prompting is insufficient to accurately and reliably capture model perceptions, and we therefore discuss potential alternatives to improve these issues.
4/3/2024
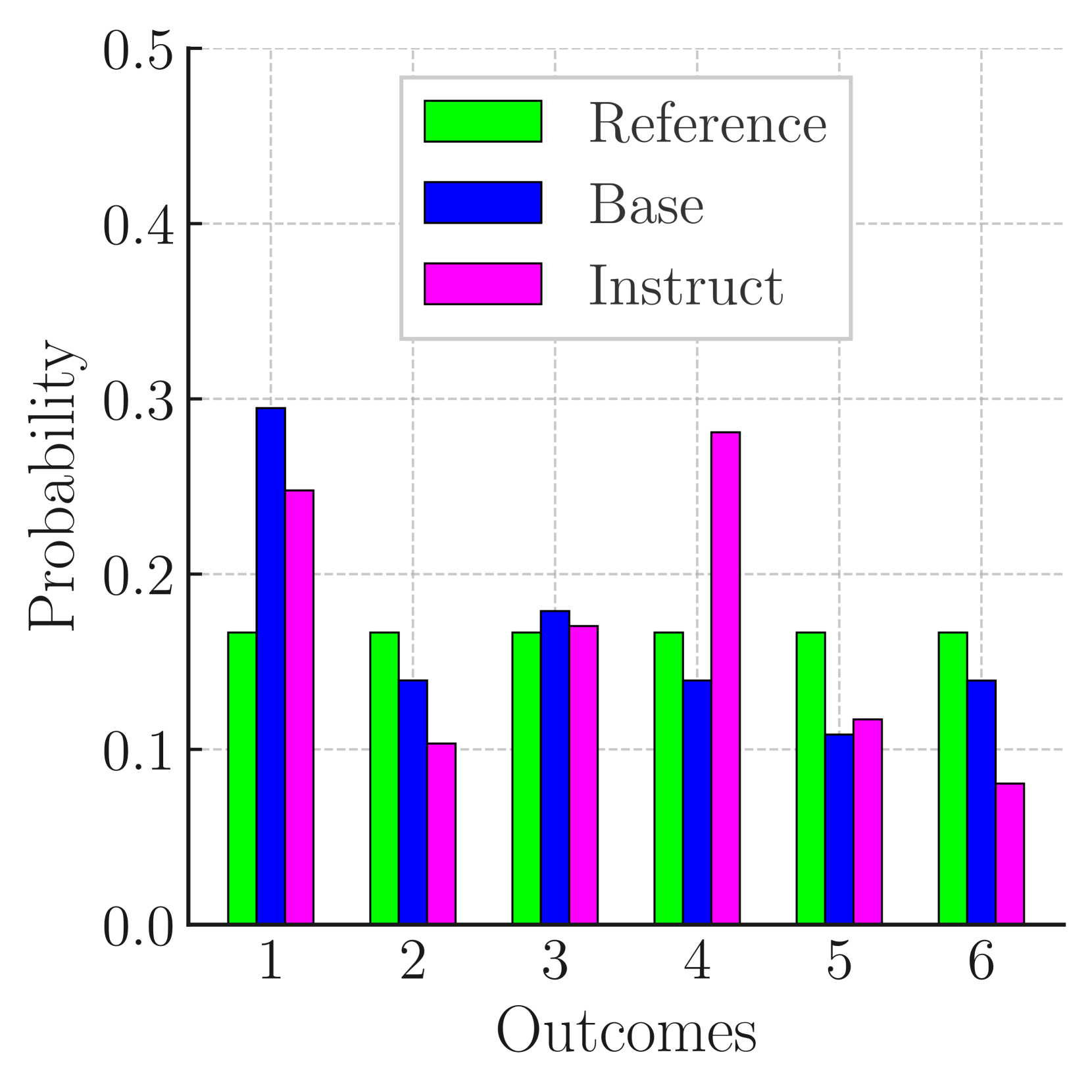
Do Large Language Models Exhibit Cognitive Dissonance? Studying the Difference Between Revealed Beliefs and Stated Answers
Manuel Mondal, Ljiljana Dolamic, G'er^ome Bovet, Philippe Cudr'e-Mauroux
0
0
Prompting and Multiple Choices Questions (MCQ) have become the preferred approach to assess the capabilities of Large Language Models (LLMs), due to their ease of manipulation and evaluation. Such experimental appraisals have pointed toward the LLMs' apparent ability to perform causal reasoning or to grasp uncertainty. In this paper, we investigate whether these abilities are measurable outside of tailored prompting and MCQ by reformulating these issues as direct text completion - the foundation of LLMs. To achieve this goal, we define scenarios with multiple possible outcomes and we compare the prediction made by the LLM through prompting (their Stated Answer) to the probability distributions they compute over these outcomes during next token prediction (their Revealed Belief). Our findings suggest that the Revealed Belief of LLMs significantly differs from their Stated Answer and hint at multiple biases and misrepresentations that their beliefs may yield in many scenarios and outcomes. As text completion is at the core of LLMs, these results suggest that common evaluation methods may only provide a partial picture and that more research is needed to assess the extent and nature of their capabilities.
6/24/2024