CulturePark: Boosting Cross-cultural Understanding in Large Language Models
2405.15145
0
0

Abstract
Cultural bias is pervasive in many large language models (LLMs), largely due to the deficiency of data representative of different cultures. Typically, cultural datasets and benchmarks are constructed either by extracting subsets of existing datasets or by aggregating from platforms such as Wikipedia and social media. However, these approaches are highly dependent on real-world data and human annotations, making them costly and difficult to scale. Inspired by cognitive theories on social communication, this paper introduces CulturePark, an LLM-powered multi-agent communication framework for cultural data collection. CulturePark simulates cross-cultural human communication with LLM-based agents playing roles in different cultures. It generates high-quality cross-cultural dialogues encapsulating human beliefs, norms, and customs. Using CulturePark, we generated 41,000 cultural samples to fine-tune eight culture-specific LLMs. We evaluated these models across three downstream tasks: content moderation, cultural alignment, and cultural education. Results show that for content moderation, our GPT-3.5-based models either match or outperform GPT-4 on datasets. Regarding cultural alignment, our models surpass GPT-4 on Hofstede's VSM 13 framework. Furthermore, for cultural education of human participants, our models demonstrate superior outcomes in both learning efficacy and user experience compared to GPT-4. CulturePark proves an important step in addressing cultural bias and advancing the democratization of AI, highlighting the critical role of culturally inclusive data in model training.
Create account to get full access
Overview
• This paper introduces CulturePark, a novel approach to boosting cross-cultural understanding in large language models (LLMs).
• The key ideas are to incorporate cultural knowledge into LLM training, and to develop techniques for probing and visualizing cultural biases and perceptions in these models.
Plain English Explanation
The researchers behind this paper wanted to improve the cultural awareness and understanding of large AI language models. These models, which are trained on huge amounts of online text data, can sometimes reflect or amplify cultural biases and misunderstandings.
The researchers developed a new system called CulturePark that aims to address this issue. CulturePark works by explicitly incorporating cultural knowledge and perspectives into the training of language models. This helps the models develop a more nuanced, balanced understanding of different cultures and worldviews.
The paper also describes new techniques for analyzing and visualizing the cultural perceptions and biases present in language models. This allows researchers and developers to better understand the cultural dynamics captured by these models, and to identify and mitigate any problematic biases.
Overall, the goal of this work is to create language AI that can engage in cross-cultural communication and collaboration more effectively, without being limited by narrow or skewed cultural lenses. This is an important step toward making AI systems that are more inclusive, fair and beneficial across diverse global contexts.
Technical Explanation
The CulturePark approach has three key components:
-
Cultural Knowledge Injection: The researchers augment the training data for language models with curated cultural knowledge, such as information about cultural norms, practices, and perspectives from different regions and communities. This helps the models learn a more comprehensive and balanced understanding of cultural diversity.
-
Culture-Aware Pre-training: The language models are pre-trained on this culturally-enriched dataset, which helps them develop cultural awareness and sensitivity as part of their core language understanding capabilities.
-
Culture-Probing Techniques: The paper introduces novel methods for probing the cultural biases and perceptions reflected in language models. This includes techniques for visualizing the cultural associations and stereotypes encoded in the model's internal representations.
The researchers evaluate CulturePark on a range of benchmark tasks that require cross-cultural reasoning and understanding. They demonstrate that CulturePark-based models outperform standard LLMs on these tasks, showing improved ability to navigate cultural nuances and avoid biased outputs.
Critical Analysis
The CulturePark approach represents an important advance in efforts to make large language models more culturally aware and inclusive. By explicitly incorporating cultural knowledge and perspectives into the model training process, the researchers have found an effective way to broaden the cultural horizons of these powerful AI systems.
However, the paper acknowledges that CulturePark is an initial step, and that more work is needed to fully address the complex challenges of cultural alignment in language AI. The proposed techniques for probing cultural biases are a helpful diagnostic tool, but do not in themselves solve the underlying issues.
Additionally, the paper does not explore the limitations or potential downsides of the CulturePark approach. For example, there may be challenges in scaling the cultural knowledge curation process, or in ensuring that the incorporated perspectives are truly representative of global diversity.
Further research is also needed to understand how CulturePark-based models perform in real-world, multi-stakeholder applications where cultural differences and power dynamics can play a crucial role. Careful consideration of ethical implications will be essential as this technology is developed and deployed.
Conclusion
Overall, the CulturePark paper represents an important contribution to the field of culturally-aware language AI. By developing techniques to infuse cultural knowledge into language model training, and to analyze the cultural biases present in these models, the researchers have taken significant steps toward creating more inclusive and globally-aware AI systems.
As language AI continues to play an increasingly central role in our lives, ensuring cross-cultural understanding and sensitivity will be critical. The CulturePark approach offers a promising direction for further research and development in this vital area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Cultural Bias and Cultural Alignment of Large Language Models
Yan Tao, Olga Viberg, Ryan S. Baker, Rene F. Kizilcec
0
0
Culture fundamentally shapes people's reasoning, behavior, and communication. As people increasingly use generative artificial intelligence (AI) to expedite and automate personal and professional tasks, cultural values embedded in AI models may bias people's authentic expression and contribute to the dominance of certain cultures. We conduct a disaggregated evaluation of cultural bias for five widely used large language models (OpenAI's GPT-4o/4-turbo/4/3.5-turbo/3) by comparing the models' responses to nationally representative survey data. All models exhibit cultural values resembling English-speaking and Protestant European countries. We test cultural prompting as a control strategy to increase cultural alignment for each country/territory. For recent models (GPT-4, 4-turbo, 4o), this improves the cultural alignment of the models' output for 71-81% of countries and territories. We suggest using cultural prompting and ongoing evaluation to reduce cultural bias in the output of generative AI.
6/27/2024

CULTURE-GEN: Revealing Global Cultural Perception in Language Models through Natural Language Prompting
Huihan Li, Liwei Jiang, Jena D. Huang, Hyunwoo Kim, Sebastin Santy, Taylor Sorensen, Bill Yuchen Lin, Nouha Dziri, Xiang Ren, Yejin Choi
0
0
As the utilization of large language models (LLMs) has proliferated worldwide, it is crucial for them to have adequate knowledge and fair representation for diverse global cultures. In this work, we uncover culture perceptions of three SOTA models on 110 countries and regions on 8 culture-related topics through culture-conditioned generations, and extract symbols from these generations that are associated to each culture by the LLM. We discover that culture-conditioned generation consist of linguistic markers that distinguish marginalized cultures apart from default cultures. We also discover that LLMs have an uneven degree of diversity in the culture symbols, and that cultures from different geographic regions have different presence in LLMs' culture-agnostic generation. Our findings promote further research in studying the knowledge and fairness of global culture perception in LLMs. Code and Data can be found in: https://github.com/huihanlhh/Culture-Gen/
4/30/2024
💬
CultureBank: An Online Community-Driven Knowledge Base Towards Culturally Aware Language Technologies
Weiyan Shi, Ryan Li, Yutong Zhang, Caleb Ziems, Chunhua yu, Raya Horesh, Rog'erio Abreu de Paula, Diyi Yang
0
0
To enhance language models' cultural awareness, we design a generalizable pipeline to construct cultural knowledge bases from different online communities on a massive scale. With the pipeline, we construct CultureBank, a knowledge base built upon users' self-narratives with 12K cultural descriptors sourced from TikTok and 11K from Reddit. Unlike previous cultural knowledge resources, CultureBank contains diverse views on cultural descriptors to allow flexible interpretation of cultural knowledge, and contextualized cultural scenarios to help grounded evaluation. With CultureBank, we evaluate different LLMs' cultural awareness, and identify areas for improvement. We also fine-tune a language model on CultureBank: experiments show that it achieves better performances on two downstream cultural tasks in a zero-shot setting. Finally, we offer recommendations based on our findings for future culturally aware language technologies. The project page is https://culturebank.github.io . The code and model is at https://github.com/SALT-NLP/CultureBank . The released CultureBank dataset is at https://huggingface.co/datasets/SALT-NLP/CultureBank .
4/24/2024
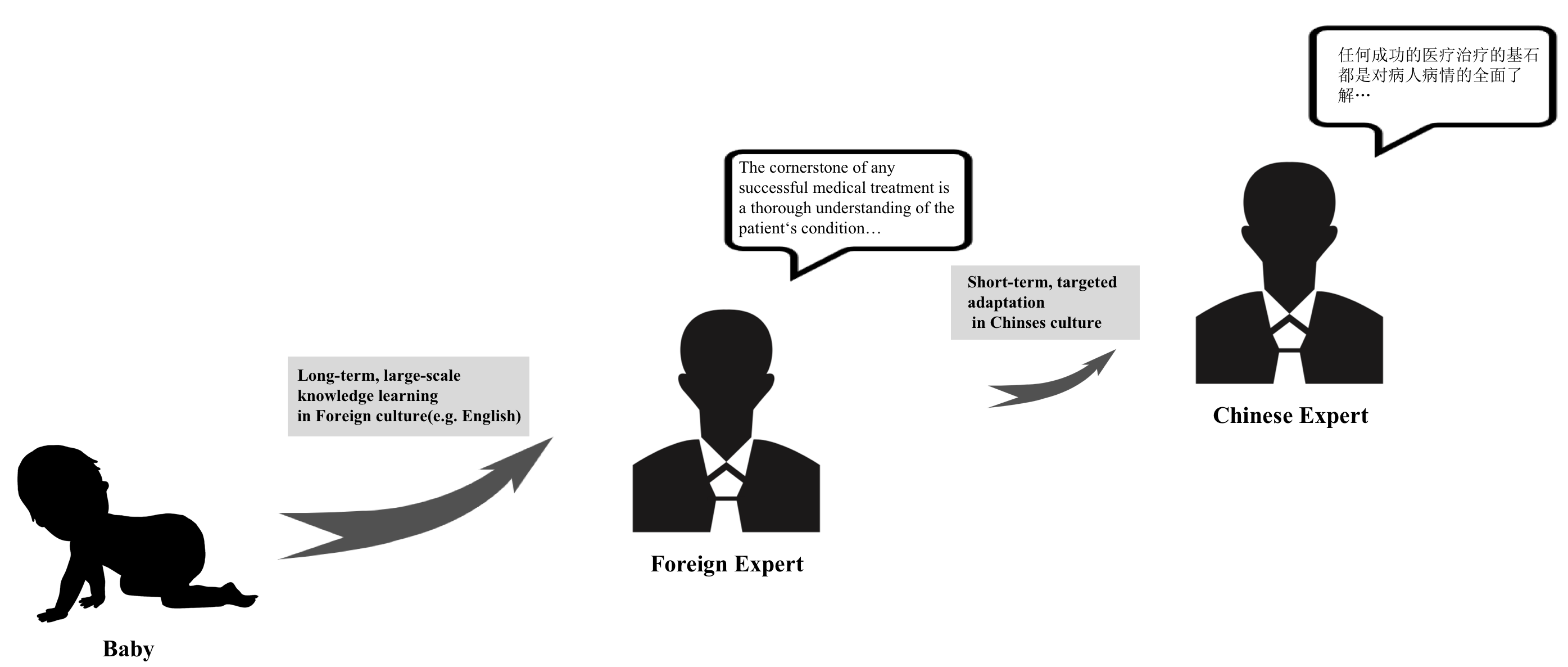
Methodology of Adapting Large English Language Models for Specific Cultural Contexts
Wenjing Zhang, Siqi Xiao, Xuejiao Lei, Ning Wang, Huazheng Zhang, Meijuan An, Bikun Yang, Zhaoxiang Liu, Kai Wang, Shiguo Lian
0
0
The rapid growth of large language models(LLMs) has emerged as a prominent trend in the field of artificial intelligence. However, current state-of-the-art LLMs are predominantly based on English. They encounter limitations when directly applied to tasks in specific cultural domains, due to deficiencies in domain-specific knowledge and misunderstandings caused by differences in cultural values. To address this challenge, our paper proposes a rapid adaptation method for large models in specific cultural contexts, which leverages instruction-tuning based on specific cultural knowledge and safety values data. Taking Chinese as the specific cultural context and utilizing the LLaMA3-8B as the experimental English LLM, the evaluation results demonstrate that the adapted LLM significantly enhances its capabilities in domain-specific knowledge and adaptability to safety values, while maintaining its original expertise advantages.
6/28/2024