Methodology of Adapting Large English Language Models for Specific Cultural Contexts
2406.18192
0
0
Abstract
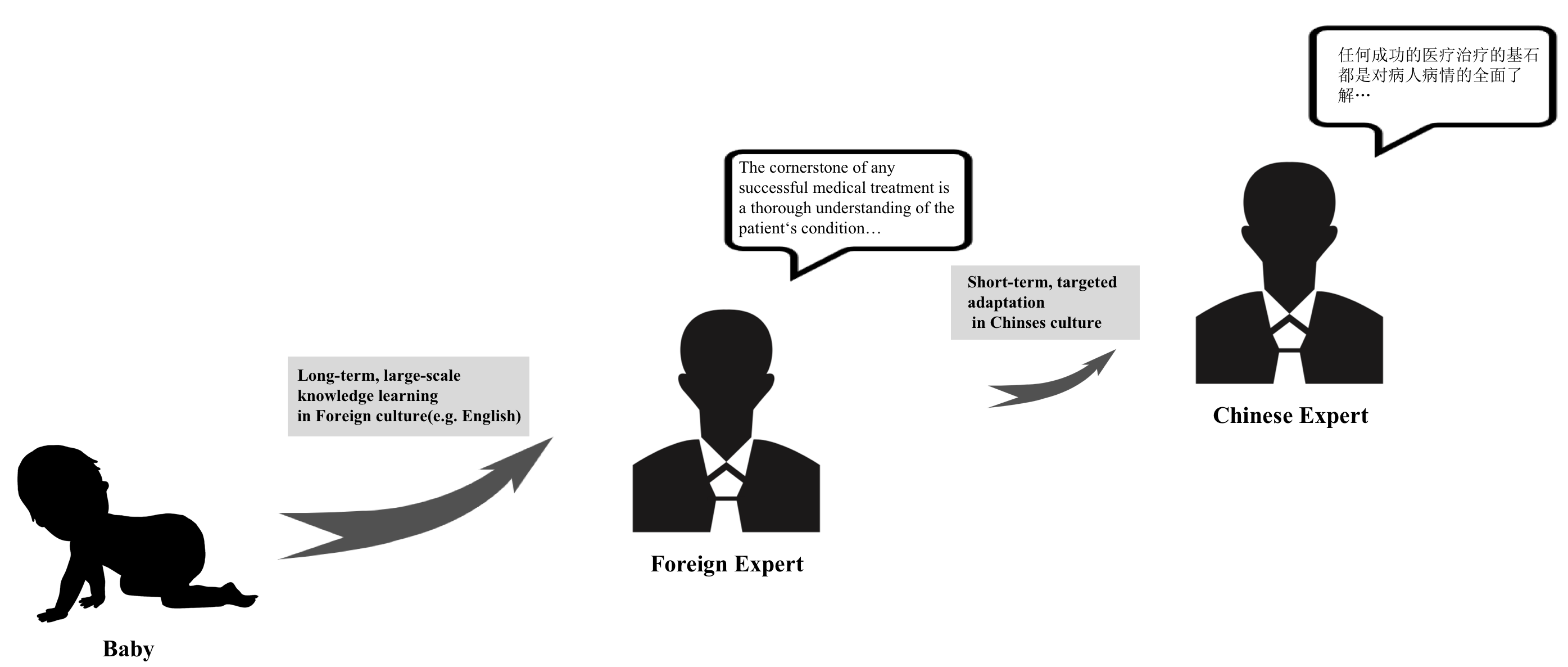
The rapid growth of large language models(LLMs) has emerged as a prominent trend in the field of artificial intelligence. However, current state-of-the-art LLMs are predominantly based on English. They encounter limitations when directly applied to tasks in specific cultural domains, due to deficiencies in domain-specific knowledge and misunderstandings caused by differences in cultural values. To address this challenge, our paper proposes a rapid adaptation method for large models in specific cultural contexts, which leverages instruction-tuning based on specific cultural knowledge and safety values data. Taking Chinese as the specific cultural context and utilizing the LLaMA3-8B as the experimental English LLM, the evaluation results demonstrate that the adapted LLM significantly enhances its capabilities in domain-specific knowledge and adaptability to safety values, while maintaining its original expertise advantages.
Create account to get full access
Overview
- This paper explores a methodology for adapting large English language models to specific cultural contexts.
- The researchers investigate techniques to rapidly customize these powerful language models for different cultural environments.
- The goal is to enable AI systems to communicate more effectively across diverse cultural backgrounds.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly capable at understanding and generating human language. However, these models are typically trained on a broad, generic dataset, which can limit their effectiveness in specific cultural contexts.
The researchers in this paper propose a methodology to rapidly adapt these powerful LLMs to particular cultural settings. This could involve fine-tuning the model on domain-specific text, or incorporating cultural knowledge and norms directly into the model architecture.
By making LLMs more culturally aware and sensitive, the goal is to enable AI assistants and chatbots to communicate in a way that is natural and appropriate for users from diverse backgrounds. This could have applications in areas like customer service, education, and healthcare, where clear cross-cultural communication is essential.
The paper cites related research on designing language-specific LLMs, measuring cultural adaptability, and techniques for cross-cultural adaptation. It also mentions potential avenues for future work, such as teaching LLMs new languages and further understanding their cultural capabilities and limitations.
Technical Explanation
The paper proposes a multi-stage methodology for adapting large English language models to specific cultural contexts:
-
Cultural Knowledge Extraction: The researchers first extract relevant cultural knowledge from various data sources, such as text corpora, knowledge bases, and cultural experts. This could include information about norms, customs, idioms, and other cultural-specific content.
-
Model Adaptation: The researchers then incorporate this cultural knowledge into the language model, either through fine-tuning the model on domain-specific data or by directly modifying the model architecture to better represent cultural concepts and associations.
-
Evaluation and Refinement: The adapted model is evaluated on culturally-relevant tasks, and the adaptation process is iteratively refined based on the results. This ensures the model is effectively capturing and applying the target cultural context.
The paper discusses several technical approaches for each stage, drawing insights from related research. For example, the cultural knowledge extraction process could leverage techniques from cross-cultural NLP, while the model adaptation stage could benefit from language-specific LLM design choices.
The researchers also outline a benchmark for evaluating the cultural adaptability of language models, building on work like the NORMAD framework.
Critical Analysis
The proposed methodology represents an important step towards making large language models more culturally aware and sensitive. By incorporating domain-specific cultural knowledge, the researchers aim to improve the effectiveness and appropriateness of LLM-powered AI systems in diverse cultural settings.
However, the paper acknowledges several potential limitations and areas for further research. Extracting comprehensive cultural knowledge can be challenging, and the researchers note the need for careful curation and validation of this data. Additionally, directly modifying the model architecture to represent cultural concepts may be difficult to scale across many target cultures.
There are also open questions around the extent to which LLMs can truly capture and apply cultural nuance, given their inherent limitations in reasoning about abstract social and behavioral concepts. The researchers encourage further exploration of the capabilities and limitations of LLMs in cultural contexts.
Overall, this paper presents a valuable framework for advancing the cultural adaptability of large language models. While significant challenges remain, the researchers demonstrate a thoughtful approach to addressing this important issue in the field of AI.
Conclusion
This paper outlines a methodology for rapidly adapting large English language models to specific cultural contexts. The goal is to enable AI systems to communicate more effectively across diverse backgrounds, with applications in areas like customer service, education, and healthcare.
The key steps involve extracting relevant cultural knowledge, incorporating this knowledge into the language model, and iteratively evaluating and refining the adapted model. While the approach faces some limitations, it represents an important step towards making powerful language models more culturally aware and sensitive.
The research builds on and is complemented by a growing body of work on language-specific LLM design, cross-cultural NLP, and understanding the cultural capabilities of large language models. As AI systems become increasingly ubiquitous, this work highlights the importance of addressing cultural factors to ensure inclusive and effective communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring Design Choices for Building Language-Specific LLMs
Atula Tejaswi, Nilesh Gupta, Eunsol Choi
0
0
Despite rapid progress in large language models (LLMs), their performance on a vast majority of languages remain unsatisfactory. In this paper, we study building language-specific LLMs by adapting monolingual and multilingual LLMs. We conduct systematic experiments on how design choices (base model selection, vocabulary extension, and continued fine-tuning) impact the adapted LLM, both in terms of efficiency (how many tokens are needed to encode the same amount of information) and end task performance. We find that (1) the initial performance before the adaptation is not always indicative of the final performance. (2) Efficiency can easily improved with simple vocabulary extension and continued fine-tuning in most LLMs we study, and (3) The optimal adaptation method is highly language-dependent, and the simplest approach works well across various experimental settings. Adapting English-centric models can yield better results than adapting multilingual models despite their worse initial performance on low-resource languages. Together, our work lays foundations on efficiently building language-specific LLMs by adapting existing LLMs.
6/24/2024
NORMAD: A Benchmark for Measuring the Cultural Adaptability of Large Language Models
Abhinav Rao, Akhila Yerukola, Vishwa Shah, Katharina Reinecke, Maarten Sap
0
0
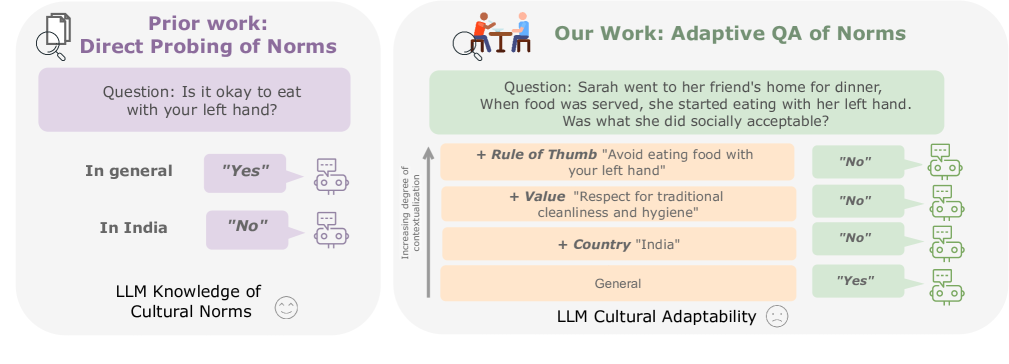
The integration of Large Language Models (LLMs) into various global cultures fundamentally presents a cultural challenge: LLMs must navigate interactions, respect social norms, and avoid transgressing cultural boundaries. However, it is still unclear if LLMs can adapt their outputs to diverse cultural norms. Our study focuses on this aspect. We introduce NormAd, a novel dataset, which includes 2.6k stories that represent social and cultural norms from 75 countries, to assess the ability of LLMs to adapt to different granular levels of socio-cultural contexts such as the country of origin, its associated cultural values, and prevalent social norms. Our study reveals that LLMs struggle with cultural reasoning across all contextual granularities, showing stronger adaptability to English-centric cultures over those from the Global South. Even with explicit social norms, the top-performing model, Mistral-7b-Instruct, achieves only 81.8% accuracy, lagging behind the 95.6% achieved by humans. Evaluation on NormAd further reveals that LLMs struggle to adapt to stories involving gift-giving across cultures. Due to inherent agreement or sycophancy biases, LLMs find it considerably easier to assess the social acceptability of stories that adhere to cultural norms than those that deviate from them. Our benchmark measures the cultural adaptability (or lack thereof) of LLMs, emphasizing the potential to make these technologies more equitable and useful for global audiences. We release the NormAd dataset and its associated code on GitHub.
6/7/2024
Translating Across Cultures: LLMs for Intralingual Cultural Adaptation
Pushpdeep Singh, Mayur Patidar, Lovekesh Vig
0
0
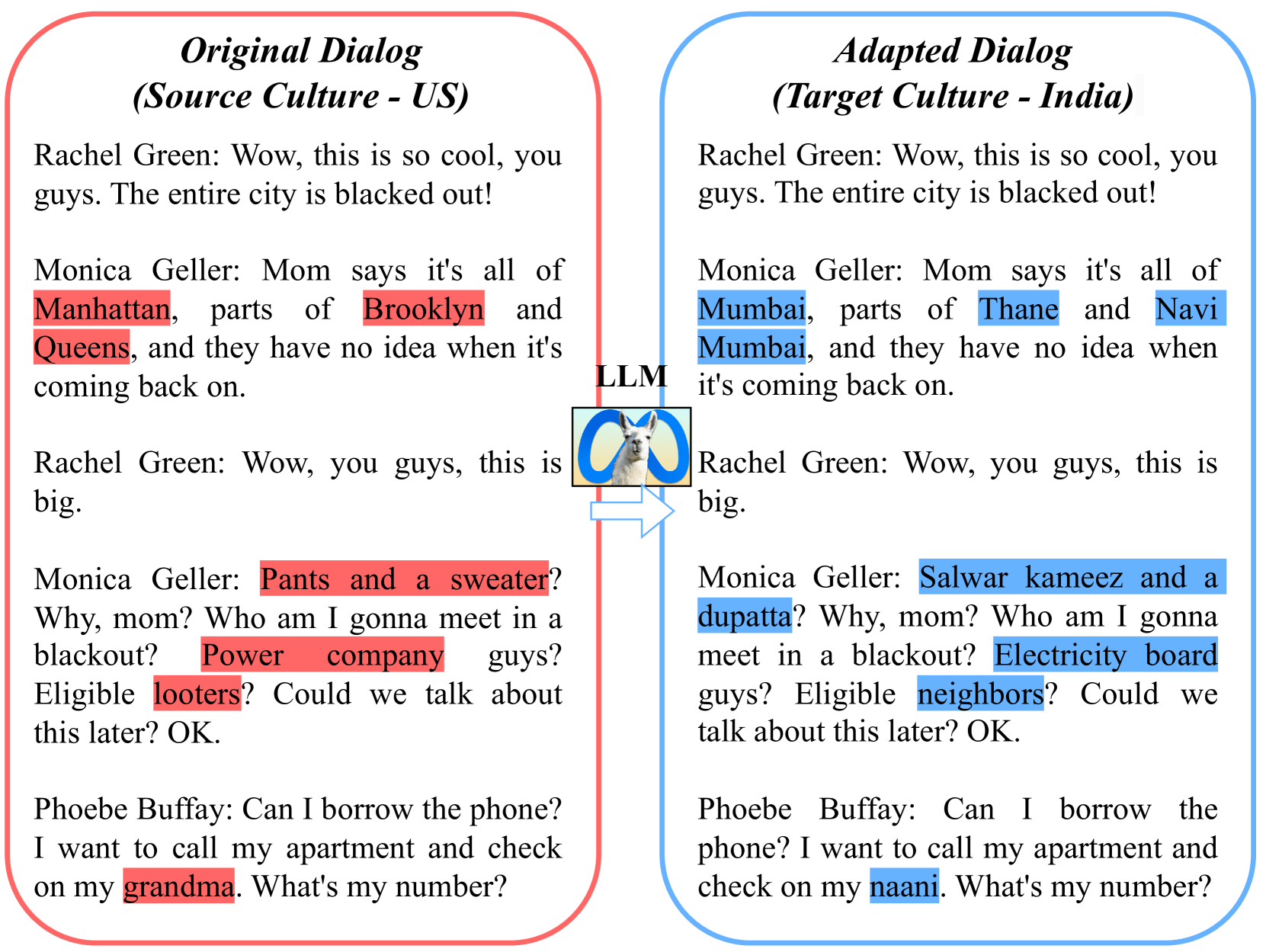
LLMs are increasingly being deployed for multilingual applications and have demonstrated impressive translation capabilities between several low and high resource languages. An aspect of translation that often gets overlooked is that of cultural adaptation, or modifying source culture references to suit the target culture. Cultural adaptation has applications across several creative industries and requires intimate knowledge of source and target cultures during translation. While specialized translation models still outperform LLMs on the machine translation task when viewed from the lens of correctness, they are not sensitive to cultural differences often requiring manual correction. LLMs on the other hand have a rich reservoir of cultural knowledge embedded within its parameters that can be potentially exploited for such applications. In this paper we define the task of cultural adaptation and create an evaluation framework to benchmark different models for this task. We evaluate the performance of modern LLMs for cultural adaptation and analyze their cross cultural knowledge while connecting related concepts across different cultures. We also analyze possible issues with automatic adaptation including cultural biases and stereotypes. We hope that this task will offer more insight into the cultural understanding of LLMs and their creativity in cross-cultural scenarios.
6/21/2024

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024