CULTURE-GEN: Revealing Global Cultural Perception in Language Models through Natural Language Prompting
2404.10199
0
0

Abstract
As the utilization of large language models (LLMs) has proliferated worldwide, it is crucial for them to have adequate knowledge and fair representation for diverse global cultures. In this work, we uncover culture perceptions of three SOTA models on 110 countries and regions on 8 culture-related topics through culture-conditioned generations, and extract symbols from these generations that are associated to each culture by the LLM. We discover that culture-conditioned generation consist of linguistic markers that distinguish marginalized cultures apart from default cultures. We also discover that LLMs have an uneven degree of diversity in the culture symbols, and that cultures from different geographic regions have different presence in LLMs' culture-agnostic generation. Our findings promote further research in studying the knowledge and fairness of global culture perception in LLMs. Code and Data can be found in: https://github.com/huihanlhh/Culture-Gen/
Create account to get full access
Overview
- The research paper "Culture-Gen: Revealing Global Cultural Perception in Language Models through Natural Language Prompting" explores how language models reflect and perpetuate cultural biases.
- The researchers developed a framework called "Culture-Gen" to uncover cultural perceptions encoded in large language models (LLMs) through natural language prompting.
- The paper presents methods to identify biases and stereotypes in LLMs related to different aspects of culture, including gender, race, age, and nationality.
Plain English Explanation
The researchers behind this paper wanted to understand how language models, like those used in chatbots and virtual assistants, reflect and spread cultural biases. They created a framework called "Culture-Gen" to explore this issue.
Language models are trained on vast amounts of online text data, which can contain biases and stereotypes about different cultures, genders, races, ages, and nationalities. The researchers used natural language prompts to uncover how these biases manifest in the outputs of language models.
For example, they might prompt the model to describe a "successful businessperson" and analyze the gender, race, and other cultural attributes of the person the model generates. By doing this systematically across many prompts, the researchers were able to identify patterns in how the language model encodes and perpetuates cultural perceptions.
This research is important because language models are becoming increasingly powerful and ubiquitous, and the biases they contain can be amplified and spread through their widespread use. Understanding these biases is the first step towards mitigating them and ensuring language technology is more equitable and inclusive.
Technical Explanation
The researchers developed the "Culture-Gen" framework to measure cultural biases in large language models (LLMs) through natural language prompting. They designed a set of prompts spanning various aspects of culture, including gender, race, age, and nationality, and used these prompts to elicit responses from multiple LLMs.
By analyzing the model outputs, the researchers were able to uncover patterns in how the LLMs encode and perpetuate cultural stereotypes and biases. For example, they found that language models were more likely to associate certain occupations, personality traits, and physical attributes with specific genders, races, and age groups.
The researchers also explored how the cultural biases in LLMs can be influenced by factors such as the training data, model architecture, and fine-tuning approaches. They compared the performance of different LLMs on the Culture-Gen prompts and examined the relationship between model characteristics and the extent of cultural biases.
Additionally, the researchers developed methods to quantify the cultural biases in LLMs, such as measuring the degree of association between cultural attributes and model outputs. These metrics can be used to track and monitor the evolution of cultural biases in language models over time.
Critical Analysis
The researchers acknowledge several limitations and caveats in their study. For instance, the Culture-Gen prompts may not capture the full breadth of cultural perceptions, and the analysis is limited to the specific LLMs and datasets used in the experiments.
Additionally, the researchers note that the observed biases in LLMs may not necessarily reflect the personal beliefs or intentions of the model developers. Rather, they are a reflection of the cultural biases present in the training data, which can be challenging to fully address.
Further research is needed to explore more nuanced aspects of cultural perception, such as the intersectionality of different cultural attributes and the influence of context on model outputs. There is also a need to develop more robust and comprehensive evaluation frameworks to assess the cultural biases in language models.
Conclusion
The "Culture-Gen" framework presented in this paper offers a novel approach to uncovering and quantifying cultural biases in large language models. By using natural language prompting, the researchers were able to reveal patterns in how LLMs encode and perpetuate stereotypes and biases related to gender, race, age, and nationality.
This research is an important step towards understanding and mitigating the cultural biases in language technology, which can have significant societal implications as these models become more widely adopted. The insights gained from this work can inform the development of more equitable and inclusive language models, as well as the design of responsible AI systems that are mindful of cultural diversity and representation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CulturePark: Boosting Cross-cultural Understanding in Large Language Models
Cheng Li, Damien Teney, Linyi Yang, Qingsong Wen, Xing Xie, Jindong Wang
0
0
Cultural bias is pervasive in many large language models (LLMs), largely due to the deficiency of data representative of different cultures. Typically, cultural datasets and benchmarks are constructed either by extracting subsets of existing datasets or by aggregating from platforms such as Wikipedia and social media. However, these approaches are highly dependent on real-world data and human annotations, making them costly and difficult to scale. Inspired by cognitive theories on social communication, this paper introduces CulturePark, an LLM-powered multi-agent communication framework for cultural data collection. CulturePark simulates cross-cultural human communication with LLM-based agents playing roles in different cultures. It generates high-quality cross-cultural dialogues encapsulating human beliefs, norms, and customs. Using CulturePark, we generated 41,000 cultural samples to fine-tune eight culture-specific LLMs. We evaluated these models across three downstream tasks: content moderation, cultural alignment, and cultural education. Results show that for content moderation, our GPT-3.5-based models either match or outperform GPT-4 on datasets. Regarding cultural alignment, our models surpass GPT-4 on Hofstede's VSM 13 framework. Furthermore, for cultural education of human participants, our models demonstrate superior outcomes in both learning efficacy and user experience compared to GPT-4. CulturePark proves an important step in addressing cultural bias and advancing the democratization of AI, highlighting the critical role of culturally inclusive data in model training.
5/27/2024
💬
Cultural Bias and Cultural Alignment of Large Language Models
Yan Tao, Olga Viberg, Ryan S. Baker, Rene F. Kizilcec
0
0
Culture fundamentally shapes people's reasoning, behavior, and communication. As people increasingly use generative artificial intelligence (AI) to expedite and automate personal and professional tasks, cultural values embedded in AI models may bias people's authentic expression and contribute to the dominance of certain cultures. We conduct a disaggregated evaluation of cultural bias for five widely used large language models (OpenAI's GPT-4o/4-turbo/4/3.5-turbo/3) by comparing the models' responses to nationally representative survey data. All models exhibit cultural values resembling English-speaking and Protestant European countries. We test cultural prompting as a control strategy to increase cultural alignment for each country/territory. For recent models (GPT-4, 4-turbo, 4o), this improves the cultural alignment of the models' output for 71-81% of countries and territories. We suggest using cultural prompting and ongoing evaluation to reduce cultural bias in the output of generative AI.
6/27/2024

Towards Measuring and Modeling Culture in LLMs: A Survey
Muhammad Farid Adilazuarda, Sagnik Mukherjee, Pradhyumna Lavania, Siddhant Singh, Alham Fikri Aji, Jacki O'Neill, Ashutosh Modi, Monojit Choudhury
0
0
We present a survey of more than 90 recent papers that aim to study cultural representation and inclusion in large language models (LLMs). We observe that none of the studies explicitly define culture, which is a complex, multifaceted concept; instead, they probe the models on some specially designed datasets which represent certain aspects of culture. We call these aspects the proxies of culture, and organize them across two dimensions of demographic and semantic proxies. We also categorize the probing methods employed. Our analysis indicates that only certain aspects of ``culture,'' such as values and objectives, have been studied, leaving several other interesting and important facets, especially the multitude of semantic domains (Thompson et al., 2020) and aboutness (Hershcovich et al., 2022), unexplored. Two other crucial gaps are the lack of robustness of probing techniques and situated studies on the impact of cultural mis- and under-representation in LLM-based applications.
6/21/2024
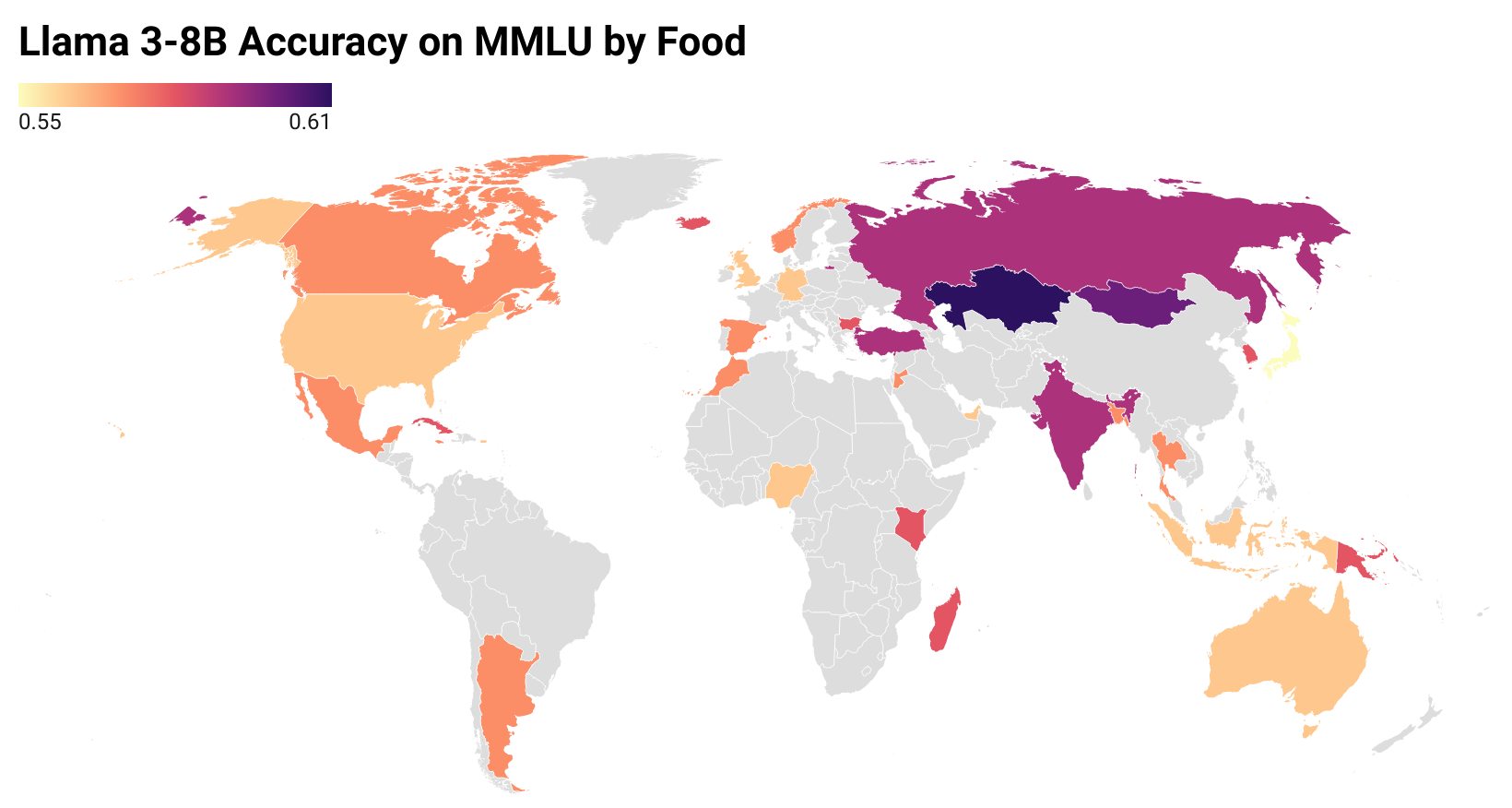
Cultural Conditioning or Placebo? On the Effectiveness of Socio-Demographic Prompting
Sagnik Mukherjee, Muhammad Farid Adilazuarda, Sunayana Sitaram, Kalika Bali, Alham Fikri Aji, Monojit Choudhury
0
0
Socio-demographic prompting is a commonly employed approach to study cultural biases in LLMs as well as for aligning models to certain cultures. In this paper, we systematically probe four LLMs (Llama 3, Mistral v0.2, GPT-3.5 Turbo and GPT-4) with prompts that are conditioned on culturally sensitive and non-sensitive cues, on datasets that are supposed to be culturally sensitive (EtiCor and CALI) or neutral (MMLU and ETHICS). We observe that all models except GPT-4 show significant variations in their responses on both kinds of datasets for both kinds of prompts, casting doubt on the robustness of the culturally-conditioned prompting as a method for eliciting cultural bias in models or as an alignment strategy. The work also calls rethinking the control experiment design to tease apart the cultural conditioning of responses from placebo effect, i.e., random perturbations of model responses due to arbitrary tokens in the prompt.
6/21/2024