CuNeRF: Cube-Based Neural Radiance Field for Zero-Shot Medical Image Arbitrary-Scale Super Resolution

0
🧠
Sign in to get full access
Overview
- Proposed a new framework called Cube-based Neural Radiance Field (CuNeRF) for medical image super-resolution
- CuNeRF can generate high-quality medical images at arbitrary scales and viewpoints without needing high-resolution reference images
- Outperforms state-of-the-art methods in visual quality and reducing aliasing artifacts
Plain English Explanation
Medical imaging techniques like magnetic resonance imaging (MRI) and computed tomography (CT) scans can produce high-quality images, but the resolution is often limited. Medical image arbitrary-scale super-resolution (MIASSR) aims to increase the resolution of these medical images, but existing methods have two main problems:
- They rely on having access to high-resolution (HR) reference images, which may not always be available.
- They struggle to generalize and apply the super-resolution technique to different medical imaging modalities or scanning conditions.
To overcome these limitations, the researchers developed a new framework called Cube-based Neural Radiance Field (CuNeRF). CuNeRF works by building a continuous, coordinate-intensity representation of the medical image directly from the low-resolution (LR) scan data, without needing any HR reference images.
This is achieved through a set of differentiable modules that sample the image data in a cube-based fashion, render the volume isotropically, and use a hierarchical rendering approach. By doing this, CuNeRF can generate high-quality medical images at any desired scale or viewpoint, without being limited to the resolution of the original scan.
The researchers tested CuNeRF on both MRI and CT scans and found that it outperformed existing MIASSR methods in terms of visual quality and reducing aliasing artifacts, even at high upsampling factors. Importantly, CuNeRF does not require any LR-HR training pairs, making it more flexible and easier to use than other approaches.
Technical Explanation
The core idea behind CuNeRF is to build a continuous, coordinate-intensity representation of the medical image directly from the low-resolution (LR) scan data, without needing any high-resolution (HR) reference images. This is achieved through several key components:
-
Cube-based Sampling: The LR volume is divided into a set of 3D cubes, and a neural network is used to learn a mapping from the cube coordinates to the corresponding intensity values. This allows the model to represent the image in a continuous, coordinate-based manner.
-
Isotropic Volume Rendering: To generate the final high-resolution image, the model uses an isotropic volume rendering technique that can faithfully reproduce the 3D structure of the medical scan, even when viewed from arbitrary angles.
-
Cube-based Hierarchical Rendering: The model employs a hierarchical rendering approach, where it first generates a coarse-resolution image and then progressively refines it by adding details from the cube-based representation. This allows for efficient and high-quality image generation at arbitrary scales.
The researchers extensively evaluated CuNeRF on both MRI and CT scan data, and compared it to state-of-the-art MIASSR methods. They found that CuNeRF consistently outperformed these existing approaches in terms of visual quality and reduction of aliasing artifacts, even at high upsampling factors.
Importantly, CuNeRF does not require any LR-HR training pairs, which is a limitation of many other MIASSR methods. This makes CuNeRF more flexible and easier to use in a wider range of medical imaging scenarios, where HR reference scans may not be available.
Critical Analysis
The CuNeRF framework represents a significant advancement in the field of medical image super-resolution, as it addresses two key limitations of existing approaches: the need for HR reference images and poor generalization across modalities and scanning conditions.
However, the paper does not delve into the potential limitations or caveats of the CuNeRF approach. For example, it would be interesting to understand how CuNeRF performs on medical scans with different levels of noise or artifacts, or how it scales to higher-dimensional imaging modalities like 3D diffusion MRI or segmentation-aware high-quality neural radiance fields.
Additionally, the paper could have explored the potential tradeoffs between the continuous, coordinate-based representation and more traditional voxel-based approaches, such as MonoPatchNeRF or analyzing the internals of neural radiance fields. Understanding the strengths and limitations of each approach could help guide future research in this area.
Overall, the CuNeRF framework represents an exciting development in medical image super-resolution, and the researchers have provided a strong foundation for further exploration and innovation in this field.
Conclusion
The Cube-based Neural Radiance Field (CuNeRF) framework proposed in this paper offers a novel approach to medical image super-resolution that addresses the key limitations of existing methods. By building a continuous, coordinate-intensity representation of the medical image directly from low-resolution scan data, CuNeRF can generate high-quality images at arbitrary scales and viewpoints, without needing any high-resolution reference images.
The researchers have demonstrated the effectiveness of CuNeRF on both MRI and CT scan data, showing that it outperforms state-of-the-art MIASSR methods in terms of visual quality and reducing aliasing artifacts. Importantly, CuNeRF's ability to work without LR-HR training pairs makes it more flexible and easier to deploy in a wider range of medical imaging scenarios.
While the paper does not explore the potential limitations and tradeoffs of the CuNeRF approach, the framework represents a significant step forward in the field of medical image super-resolution. As researchers continue to build upon and refine these techniques, we can expect to see even more powerful and versatile tools for enhancing the quality and utility of medical imaging data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
CuNeRF: Cube-Based Neural Radiance Field for Zero-Shot Medical Image Arbitrary-Scale Super Resolution
Zixuan Chen, Jian-Huang Lai, Lingxiao Yang, Xiaohua Xie
Medical image arbitrary-scale super-resolution (MIASSR) has recently gained widespread attention, aiming to super sample medical volumes at arbitrary scales via a single model. However, existing MIASSR methods face two major limitations: (i) reliance on high-resolution (HR) volumes and (ii) limited generalization ability, which restricts their application in various scenarios. To overcome these limitations, we propose Cube-based Neural Radiance Field (CuNeRF), a zero-shot MIASSR framework that can yield medical images at arbitrary scales and viewpoints in a continuous domain. Unlike existing MIASSR methods that fit the mapping between low-resolution (LR) and HR volumes, CuNeRF focuses on building a coordinate-intensity continuous representation from LR volumes without the need for HR references. This is achieved by the proposed differentiable modules: including cube-based sampling, isotropic volume rendering, and cube-based hierarchical rendering. Through extensive experiments on magnetic resource imaging (MRI) and computed tomography (CT) modalities, we demonstrate that CuNeRF outperforms state-of-the-art MIASSR methods. CuNeRF yields better visual verisimilitude and reduces aliasing artifacts at various upsampling factors. Moreover, our CuNeRF does not need any LR-HR training pairs, which is more flexible and easier to be used than others. Our code is released at https://github.com/NarcissusEx/CuNeRF.
Read more4/17/2024

0
ASSR-NeRF: Arbitrary-Scale Super-Resolution on Voxel Grid for High-Quality Radiance Fields Reconstruction
Ding-Jiun Huang, Zi-Ting Chou, Yu-Chiang Frank Wang, Cheng Sun
NeRF-based methods reconstruct 3D scenes by building a radiance field with implicit or explicit representations. While NeRF-based methods can perform novel view synthesis (NVS) at arbitrary scale, the performance in high-resolution novel view synthesis (HRNVS) with low-resolution (LR) optimization often results in oversmoothing. On the other hand, single-image super-resolution (SR) aims to enhance LR images to HR counterparts but lacks multi-view consistency. To address these challenges, we propose Arbitrary-Scale Super-Resolution NeRF (ASSR-NeRF), a novel framework for super-resolution novel view synthesis (SRNVS). We propose an attention-based VoxelGridSR model to directly perform 3D super-resolution (SR) on the optimized volume. Our model is trained on diverse scenes to ensure generalizability. For unseen scenes trained with LR views, we then can directly apply our VoxelGridSR to further refine the volume and achieve multi-view consistent SR. We demonstrate quantitative and qualitatively that the proposed method achieves significant performance in SRNVS.
Read more7/1/2024
0
CSR-dMRI: Continuous Super-Resolution of Diffusion MRI with Anatomical Structure-assisted Implicit Neural Representation Learning
Ruoyou Wu, Jian Cheng, Cheng Li, Juan Zou, Jing Yang, Wenxin Fan, Yong Liang, Shanshan Wang
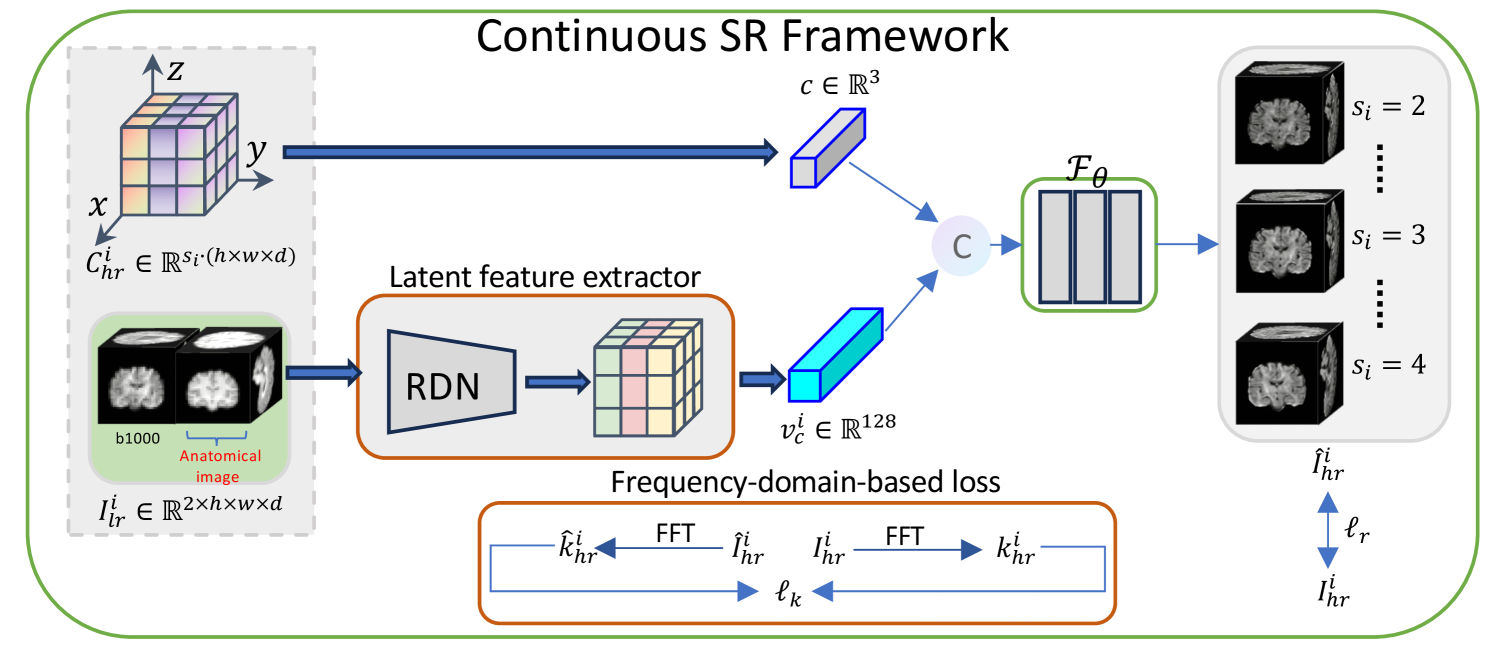
Deep learning-based dMRI super-resolution methods can effectively enhance image resolution by leveraging the learning capabilities of neural networks on large datasets. However, these methods tend to learn a fixed scale mapping between low-resolution (LR) and high-resolution (HR) images, overlooking the need for radiologists to scale the images at arbitrary resolutions. Moreover, the pixel-wise loss in the image domain tends to generate over-smoothed results, losing fine textures and edge information. To address these issues, we propose a novel continuous super-resolution method for dMRI, called CSR-dMRI, which utilizes an anatomical structure-assisted implicit neural representation learning approach. Specifically, the CSR-dMRI model consists of two components. The first is the latent feature extractor, which primarily extracts latent space feature maps from LR dMRI and anatomical images while learning structural prior information from the anatomical images. The second is the implicit function network, which utilizes voxel coordinates and latent feature vectors to generate voxel intensities at corresponding positions. Additionally, a frequency-domain-based loss is introduced to preserve the structural and texture information, further enhancing the image quality. Extensive experiments on the publicly available HCP dataset validate the effectiveness of our approach. Furthermore, our method demonstrates superior generalization capability and can be applied to arbitrary-scale super-resolution, including non-integer scale factors, expanding its applicability beyond conventional approaches.
Read more8/15/2024
🛠️
0
MuRF: Multi-Baseline Radiance Fields
Haofei Xu, Anpei Chen, Yuedong Chen, Christos Sakaridis, Yulun Zhang, Marc Pollefeys, Andreas Geiger, Fisher Yu
We present Multi-Baseline Radiance Fields (MuRF), a general feed-forward approach to solving sparse view synthesis under multiple different baseline settings (small and large baselines, and different number of input views). To render a target novel view, we discretize the 3D space into planes parallel to the target image plane, and accordingly construct a target view frustum volume. Such a target volume representation is spatially aligned with the target view, which effectively aggregates relevant information from the input views for high-quality rendering. It also facilitates subsequent radiance field regression with a convolutional network thanks to its axis-aligned nature. The 3D context modeled by the convolutional network enables our method to synthesis sharper scene structures than prior works. Our MuRF achieves state-of-the-art performance across multiple different baseline settings and diverse scenarios ranging from simple objects (DTU) to complex indoor and outdoor scenes (RealEstate10K and LLFF). We also show promising zero-shot generalization abilities on the Mip-NeRF 360 dataset, demonstrating the general applicability of MuRF.
Read more6/11/2024