D2-MLP: Dynamic Decomposed MLP Mixer for Medical Image Segmentation

0

Sign in to get full access
Overview
- The paper presents a novel neural network architecture called D2-MLP for medical image segmentation.
- D2-MLP is a dynamic and decomposed MLP Mixer model that aims to improve upon existing MLP-based methods.
- The key innovations include a dynamic network structure and a decomposed MLP design.
Plain English Explanation
The researchers developed a new type of neural network called D2-MLP for the task of medical image segmentation. Medical image segmentation is the process of dividing an image of the body, like an X-ray or MRI scan, into meaningful regions or structures.
D2-MLP is built on the concept of an MLP Mixer, which is a type of neural network that uses only dense, fully connected layers instead of convolutional layers. This makes MLP Mixers computationally efficient and easy to train. However, existing MLP Mixer models have limitations when it comes to medical image segmentation.
The key innovations in D2-MLP are:
-
Dynamic Network Structure: Instead of using a fixed neural network architecture, D2-MLP dynamically adjusts its structure based on the input image. This allows the model to better adapt to the specific characteristics of each medical image.
-
Decomposed MLP Design: D2-MLP decomposes the standard MLP Mixer layer into several sub-components, each focusing on different aspects of the input data. This decomposition helps the model capture more detailed and nuanced features from the medical images.
By incorporating these dynamic and decomposed elements, the researchers show that D2-MLP can achieve improved performance on medical image segmentation tasks compared to other MLP-based models.
Technical Explanation
The core of the D2-MLP architecture is the Dynamic Decomposed MLP (D2-MLP) Block, which is the building block of the overall model. This block consists of several key components:
-
Dynamic Mixer Layer: This layer dynamically adjusts the number of channels and spatial dimensions of the input based on the characteristics of the input image. This allows the model to adapt its structure to better suit the specific medical image being processed.
-
Decomposed MLP Layers: The standard MLP Mixer layer is decomposed into multiple sub-layers, each focusing on different aspects of the input data. This includes layers for channel mixing, spatial mixing, and a final integration layer.
-
Attention Mechanism: D2-MLP incorporates an attention mechanism to selectively focus on the most relevant features in the input image. This helps the model better capture the important structures and details in medical images.
The overall D2-MLP architecture stacks multiple D2-MLP Blocks to form the complete network. The researchers evaluate D2-MLP on several medical image segmentation benchmarks and demonstrate that it outperforms other MLP-based models as well as traditional convolutional neural networks.
Critical Analysis
The researchers acknowledge that while D2-MLP shows promising results, there are still some limitations and areas for further exploration:
-
Computational Complexity: The dynamic and decomposed nature of D2-MLP adds some computational overhead compared to simpler MLP Mixer models. The researchers discuss the need to further optimize the model's efficiency.
-
Generalization to Other Domains: The paper focuses on medical image segmentation, but it's unclear how well the D2-MLP approach would transfer to other computer vision tasks outside of the medical domain.
-
Interpretability: As with many deep learning models, the internal workings of D2-MLP can be difficult to interpret. Improving the model's interpretability could help researchers better understand its decision-making process.
Overall, the D2-MLP architecture represents an interesting and promising advancement in MLP-based models for medical image analysis. However, further research is needed to address the potential limitations and explore the broader applicability of this approach.
Conclusion
The D2-MLP model proposed in this paper introduces a dynamic and decomposed MLP Mixer architecture for medical image segmentation. By dynamically adjusting its structure and decomposing the standard MLP layers, D2-MLP can better capture the nuanced features of medical images and achieve improved performance compared to other MLP-based models.
While the researchers have demonstrated the effectiveness of D2-MLP on medical image segmentation tasks, there are still opportunities to further optimize the model's efficiency and explore its applicability to a wider range of computer vision problems. Overall, the D2-MLP approach represents an interesting step forward in the development of more adaptable and powerful MLP-based models for medical and other visual AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
D2-MLP: Dynamic Decomposed MLP Mixer for Medical Image Segmentation
Jin Yang, Xiaobing Yu, Peijie Qiu
Convolutional neural networks are widely used in various segmentation tasks in medical images. However, they are challenged to learn global features adaptively due to the inherent locality of convolutional operations. In contrast, MLP Mixers are proposed as a backbone to learn global information across channels with low complexity. However, they cannot capture spatial features efficiently. Additionally, they lack effective mechanisms to fuse and mix features adaptively. To tackle these limitations, we propose a novel Dynamic Decomposed Mixer module. It is designed to employ novel Mixers to extract features and aggregate information across different spatial locations and channels. Additionally, it employs novel dynamic mixing mechanisms to model inter-dependencies between channel and spatial feature representations and to fuse them adaptively. Subsequently, we incorporate it into a U-shaped Transformer-based architecture to generate a novel network, termed the Dynamic Decomposed MLP Mixer. We evaluated it for medical image segmentation on two datasets, and it achieved superior segmentation performance than other state-of-the-art methods.
Read more9/16/2024
🌐
0
DmADs-Net: Dense multiscale attention and depth-supervised network for medical image segmentation
Zhaojin Fu, Zheng Chen, Jinjiang Li, Lu Ren
Deep learning has made important contributions to the development of medical image segmentation. Convolutional neural networks, as a crucial branch, have attracted strong attention from researchers. Through the tireless efforts of numerous researchers, convolutional neural networks have yielded numerous outstanding algorithms for processing medical images. The ideas and architectures of these algorithms have also provided important inspiration for the development of later technologies.Through extensive experimentation, we have found that currently mainstream deep learning algorithms are not always able to achieve ideal results when processing complex datasets and different types of datasets. These networks still have room for improvement in lesion localization and feature extraction. Therefore, we have created the Dense Multiscale Attention and Depth-Supervised Network (DmADs-Net).We use ResNet for feature extraction at different depths and create a Multi-scale Convolutional Feature Attention Block to improve the network's attention to weak feature information. The Local Feature Attention Block is created to enable enhanced local feature attention for high-level semantic information. In addition, in the feature fusion phase, a Feature Refinement and Fusion Block is created to enhance the fusion of different semantic information.We validated the performance of the network using five datasets of varying sizes and types. Results from comparative experiments show that DmADs-Net outperformed mainstream networks. Ablation experiments further demonstrated the effectiveness of the created modules and the rationality of the network architecture.
Read more5/2/2024
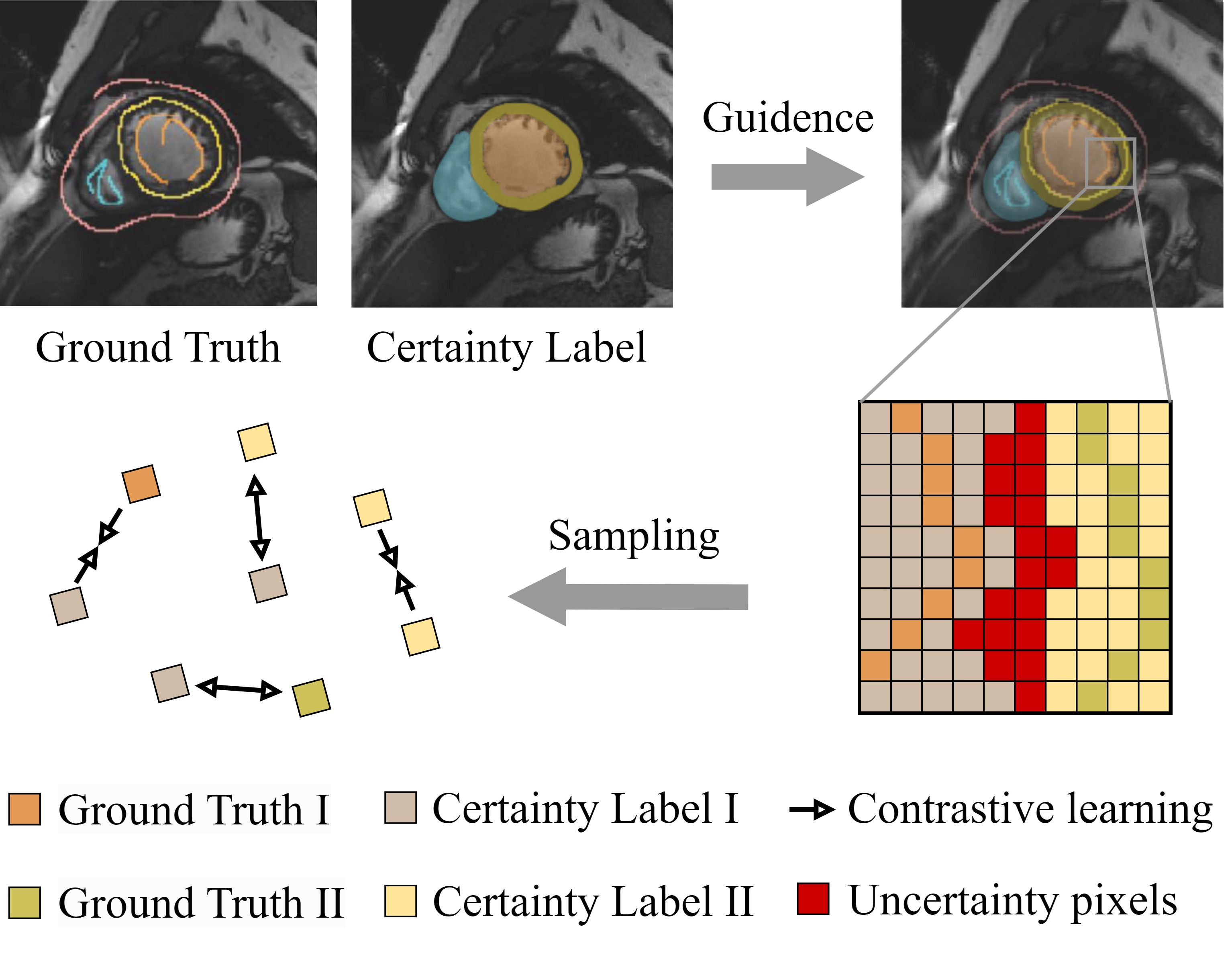
0
PCLMix: Weakly Supervised Medical Image Segmentation via Pixel-Level Contrastive Learning and Dynamic Mix Augmentation
Yu Lei, Haolun Luo, Lituan Wang, Zhenwei Zhang, Lei Zhang
In weakly supervised medical image segmentation, the absence of structural priors and the discreteness of class feature distribution present a challenge, i.e., how to accurately propagate supervision signals from local to global regions without excessively spreading them to other irrelevant regions? To address this, we propose a novel weakly supervised medical image segmentation framework named PCLMix, comprising dynamic mix augmentation, pixel-level contrastive learning, and consistency regularization strategies. Specifically, PCLMix is built upon a heterogeneous dual-decoder backbone, addressing the absence of structural priors through a strategy of dynamic mix augmentation during training. To handle the discrete distribution of class features, PCLMix incorporates pixel-level contrastive learning based on prediction uncertainty, effectively enhancing the model's ability to differentiate inter-class pixel differences and intra-class consistency. Furthermore, to reinforce segmentation consistency and robustness, PCLMix employs an auxiliary decoder for dual consistency regularization. In the inference phase, the auxiliary decoder will be dropped and no computation complexity is increased. Extensive experiments on the ACDC dataset demonstrate that PCLMix appropriately propagates local supervision signals to the global scale, further narrowing the gap between weakly supervised and fully supervised segmentation methods. Our code is available at https://github.com/Torpedo2648/PCLMix.
Read more5/21/2024
📈
0
LiteNeXt: A Novel Lightweight ConvMixer-based Model with Self-embedding Representation Parallel for Medical Image Segmentation
Ngoc-Du Tran, Thi-Thao Tran, Quang-Huy Nguyen, Manh-Hung Vu, Van-Truong Pham
The emergence of deep learning techniques has advanced the image segmentation task, especially for medical images. Many neural network models have been introduced in the last decade bringing the automated segmentation accuracy close to manual segmentation. However, cutting-edge models like Transformer-based architectures rely on large scale annotated training data, and are generally designed with densely consecutive layers in the encoder, decoder, and skip connections resulting in large number of parameters. Additionally, for better performance, they often be pretrained on a larger data, thus requiring large memory size and increasing resource expenses. In this study, we propose a new lightweight but efficient model, namely LiteNeXt, based on convolutions and mixing modules with simplified decoder, for medical image segmentation. The model is trained from scratch with small amount of parameters (0.71M) and Giga Floating Point Operations Per Second (0.42). To handle boundary fuzzy as well as occlusion or clutter in objects especially in medical image regions, we propose the Marginal Weight Loss that can help effectively determine the marginal boundary between object and background. Furthermore, we propose the Self-embedding Representation Parallel technique, that can help augment the data in a self-learning manner. Experiments on public datasets including Data Science Bowls, GlaS, ISIC2018, PH2, and Sunnybrook data show promising results compared to other state-of-the-art CNN-based and Transformer-based architectures. Our code will be published at: https://github.com/tranngocduvnvp/LiteNeXt.
Read more5/28/2024