DA-Flow: Dual Attention Normalizing Flow for Skeleton-based Video Anomaly Detection

0

Sign in to get full access
Overview
- This paper proposes a new method called DA-Flow (Dual Attention Normalizing Flow) for skeleton-based video anomaly detection.
- DA-Flow uses a dual attention mechanism to capture both spatial and temporal dependencies in the skeleton data, and a normalizing flow model to learn a compact representation of normal behavior.
- The method is designed to be effective for detecting abnormal events in videos, such as unusual human actions or interactions.
Plain English Explanation
The main idea behind this research is to develop a better way to detect unusual or anomalous events in video footage, particularly when the video is based on tracking the movements of people's skeletons.
The researchers recognized that to accurately identify abnormal behavior, you need to understand both the spatial relationships between different body parts as well as how those relationships change over time. So they created a system called DA-Flow that uses "dual attention" - one type of attention to capture the spatial dependencies, and another to capture the temporal dependencies.
Essentially, the system learns what "normal" behavior looks like by studying lots of example videos of everyday actions. It builds a compact, mathematical model of that normal behavior using a technique called "normalizing flow." Then, when you give it a new video, it can compare what it sees to its model of normal, and flag anything that seems out of the ordinary.
The researchers tested this approach on several benchmark video datasets and found that it outperformed other state-of-the-art methods for detecting anomalies. The key advantages seem to be the dual attention mechanism, which allows the system to understand both the spatial and temporal aspects of the movement, as well as the use of the normalizing flow model, which provides an efficient way to represent normal behavior.
Technical Explanation
The core of the DA-Flow method is a dual attention mechanism that captures both spatial and temporal dependencies in the skeleton data. The spatial attention module focuses on modeling the relationships between different joint locations in the skeleton, while the temporal attention module models how those relationships change over time.
These attention mechanisms feed into a normalizing flow model, which learns a compact latent representation of normal behavior. Normalizing flow is a type of generative model that can efficiently learn complex probability distributions. In this case, the model learns to map the skeleton data into a latent space where normal examples cluster together, and anomalous examples stand out.
During inference, the DA-Flow system takes a new video sequence, encodes it using the trained attention and flow modules, and then calculates an anomaly score based on how well the latent representation matches the learned model of normal behavior. Videos with high anomaly scores are flagged as containing abnormal events.
The researchers evaluated DA-Flow on several public video anomaly detection benchmarks, including DTAAD, DualFluidNet, and STP-VAD. They found that DA-Flow outperformed previous state-of-the-art methods, demonstrating the effectiveness of the dual attention and normalizing flow approach for this task.
Critical Analysis
The authors acknowledge several limitations of the proposed DA-Flow method. First, the approach relies on accurate skeleton tracking, which can be challenging in crowded or occluded scenes. Additionally, the method is currently limited to detecting anomalies in individual videos, and does not consider the broader context or relationship between multiple video streams.
Another potential issue is the reliance on pre-defined "normal" behavior, which may not capture the full range of natural variation in human actions and interactions. This could lead to false positives, where unusual but benign behaviors are flagged as anomalous.
Further research could explore ways to make the DA-Flow system more robust to noisy or incomplete skeleton data, as well as investigate techniques for anomaly detection that consider the broader context and learn more flexible models of normal behavior. Incorporating additional modalities, such as RGB video or audio, may also help improve the system's ability to accurately identify and characterize abnormal events.
Conclusion
The DA-Flow method presented in this paper represents an interesting advance in the field of skeleton-based video anomaly detection. By using a dual attention mechanism to capture both spatial and temporal dependencies, and a normalizing flow model to learn a compact representation of normal behavior, the system demonstrates state-of-the-art performance on several benchmark datasets.
While the approach has some limitations, the core ideas behind DA-Flow - the use of attention to model complex spatiotemporal relationships, and the application of normalizing flow for anomaly detection - could have broader implications for video understanding and analysis tasks. As the field continues to evolve, we may see further innovations that build upon these techniques to create even more robust and versatile systems for identifying and understanding anomalous events in video data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DA-Flow: Dual Attention Normalizing Flow for Skeleton-based Video Anomaly Detection
Ruituo Wu, Yang Chen, Jian Xiao, Bing Li, Jicong Fan, Fr'ed'eric Dufaux, Ce Zhu, Yipeng Liu
Cooperation between temporal convolutional networks (TCN) and graph convolutional networks (GCN) as a processing module has shown promising results in skeleton-based video anomaly detection (SVAD). However, to maintain a lightweight model with low computational and storage complexity, shallow GCN and TCN blocks are constrained by small receptive fields and a lack of cross-dimension interaction capture. To tackle this limitation, we propose a lightweight module called the Dual Attention Module (DAM) for capturing cross-dimension interaction relationships in spatio-temporal skeletal data. It employs the frame attention mechanism to identify the most significant frames and the skeleton attention mechanism to capture broader relationships across fixed partitions with minimal parameters and flops. Furthermore, the proposed Dual Attention Normalizing Flow (DA-Flow) integrates the DAM as a post-processing unit after GCN within the normalizing flow framework. Simulations show that the proposed model is robust against noise and negative samples. Experimental results show that DA-Flow reaches competitive or better performance than the existing state-of-the-art (SOTA) methods in terms of the micro AUC metric with the fewest number of parameters. Moreover, we found that even without training, simply using random projection without dimensionality reduction on skeleton data enables substantial anomaly detection capabilities.
Read more6/6/2024
✨
0
New!Multimodal Attention-Enhanced Feature Fusion-based Weekly Supervised Anomaly Violence Detection
Yuta Kaneko, Abu Saleh Musa Miah, Najmul Hassan, Hyoun-Sup Lee, Si-Woong Jang, Jungpil Shin
Weakly supervised video anomaly detection (WS-VAD) is a crucial area in computer vision for developing intelligent surveillance systems. This system uses three feature streams: RGB video, optical flow, and audio signals, where each stream extracts complementary spatial and temporal features using an enhanced attention module to improve detection accuracy and robustness. In the first stream, we employed an attention-based, multi-stage feature enhancement approach to improve spatial and temporal features from the RGB video where the first stage consists of a ViT-based CLIP module, with top-k features concatenated in parallel with I3D and Temporal Contextual Aggregation (TCA) based rich spatiotemporal features. The second stage effectively captures temporal dependencies using the Uncertainty-Regulated Dual Memory Units (UR-DMU) model, which learns representations of normal and abnormal data simultaneously, and the third stage is employed to select the most relevant spatiotemporal features. The second stream extracted enhanced attention-based spatiotemporal features from the flow data modality-based feature by taking advantage of the integration of the deep learning and attention module. The audio stream captures auditory cues using an attention module integrated with the VGGish model, aiming to detect anomalies based on sound patterns. These streams enrich the model by incorporating motion and audio signals often indicative of abnormal events undetectable through visual analysis alone. The concatenation of the multimodal fusion leverages the strengths of each modality, resulting in a comprehensive feature set that significantly improves anomaly detection accuracy and robustness across three datasets. The extensive experiment and high performance with the three benchmark datasets proved the effectiveness of the proposed system over the existing state-of-the-art system.
Read more9/18/2024
❗
0
DTAAD: Dual Tcn-Attention Networks for Anomaly Detection in Multivariate Time Series Data
Lingrui Yu
Anomaly detection techniques enable effective anomaly detection and diagnosis in multi-variate time series data, which are of major significance for today's industrial applications. However, establishing an anomaly detection system that can be rapidly and accurately located is a challenging problem due to the lack of anomaly labels, the high dimensional complexity of the data, memory bottlenecks in actual hardware, and the need for fast reasoning. In this paper, we propose an anomaly detection and diagnosis model, DTAAD, based on Transformer and Dual Temporal Convolutional Network (TCN). Our overall model is an integrated design in which an autoregressive model (AR) combines with an autoencoder (AE) structure. Scaling methods and feedback mechanisms are introduced to improve prediction accuracy and expand correlation differences. Constructed by us, the Dual TCN-Attention Network (DTA) uses only a single layer of Transformer encoder in our baseline experiment, belonging to an ultra-lightweight model. Our extensive experiments on seven public datasets validate that DTAAD exceeds the majority of currently advanced baseline methods in both detection and diagnostic performance. Specifically, DTAAD improved F1 scores by $8.38%$ and reduced training time by $99%$ compared to the baseline. The code and training scripts are publicly available on GitHub at https://github.com/Yu-Lingrui/DTAAD.
Read more4/30/2024
0
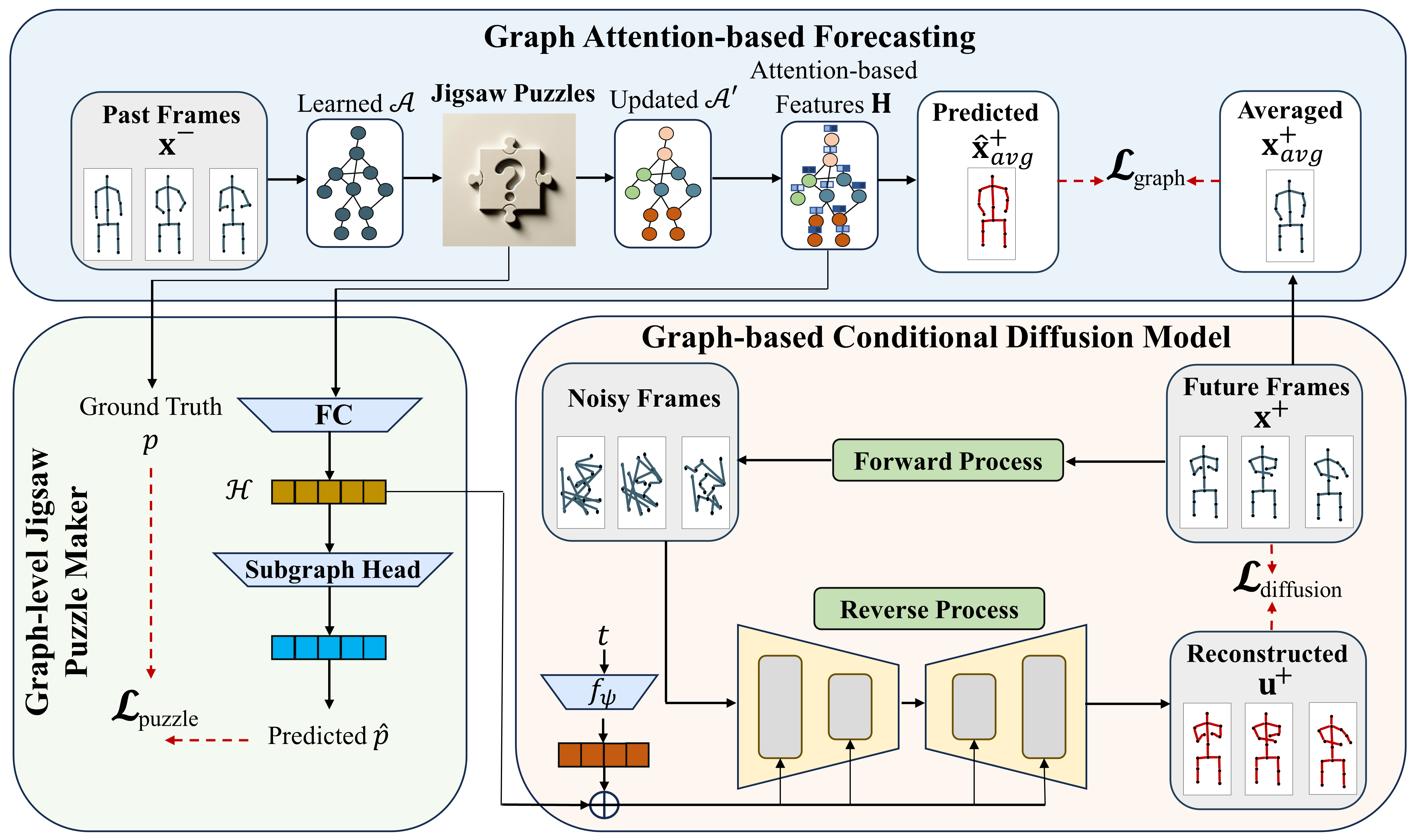
Graph-Jigsaw Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection
Ali Karami, Thi Kieu Khanh Ho, Narges Armanfard
Skeleton-based video anomaly detection (SVAD) is a crucial task in computer vision. Accurately identifying abnormal patterns or events enables operators to promptly detect suspicious activities, thereby enhancing safety. Achieving this demands a comprehensive understanding of human motions, both at body and region levels, while also accounting for the wide variations of performing a single action. However, existing studies fail to simultaneously address these crucial properties. This paper introduces a novel, practical and lightweight framework, namely Graph-Jigsaw Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection (GiCiSAD) to overcome the challenges associated with SVAD. GiCiSAD consists of three novel modules: the Graph Attention-based Forecasting module to capture the spatio-temporal dependencies inherent in the data, the Graph-level Jigsaw Puzzle Maker module to distinguish subtle region-level discrepancies between normal and abnormal motions, and the Graph-based Conditional Diffusion model to generate a wide spectrum of human motions. Extensive experiments on four widely used skeleton-based video datasets show that GiCiSAD outperforms existing methods with significantly fewer training parameters, establishing it as the new state-of-the-art.
Read more9/4/2024