Graph-Jigsaw Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection

0
Sign in to get full access
Overview
- This paper proposes a Graph-Jigsaw Conditioned Diffusion Model for skeleton-based video anomaly detection.
- The model leverages self-supervised learning on graph-structured skeleton data to learn robust representations for detecting anomalies in videos.
- Experiments on public datasets demonstrate the model's effectiveness compared to state-of-the-art methods.
Plain English Explanation
The researchers have developed a new approach for detecting unusual or abnormal activities in videos using a machine learning model. Their key idea is to [object Object] to learn powerful representations that can identify anomalies.
The model works by [object Object] and then using a diffusion process to reconstruct the original graph. This self-supervised training helps the model understand the normal patterns in human movements, so it can more easily spot deviations that might indicate an anomaly.
By focusing on the skeleton data rather than just the raw video frames, the model can capture the underlying kinematics and dynamics of human actions, which are critical for identifying unusual behaviors. This is an important advance over methods that only look at the visual appearance of the video.
The researchers evaluated their approach on public datasets of abnormal activities, and found that it outperformed other state-of-the-art anomaly detection techniques. This suggests the Graph-Jigsaw Conditioned Diffusion Model is a promising tool for real-world applications like video surveillance and healthcare monitoring.
Technical Explanation
The core of the proposed method is a [object Object] that leverages self-supervised learning on skeleton graph data to learn robust representations for anomaly detection.
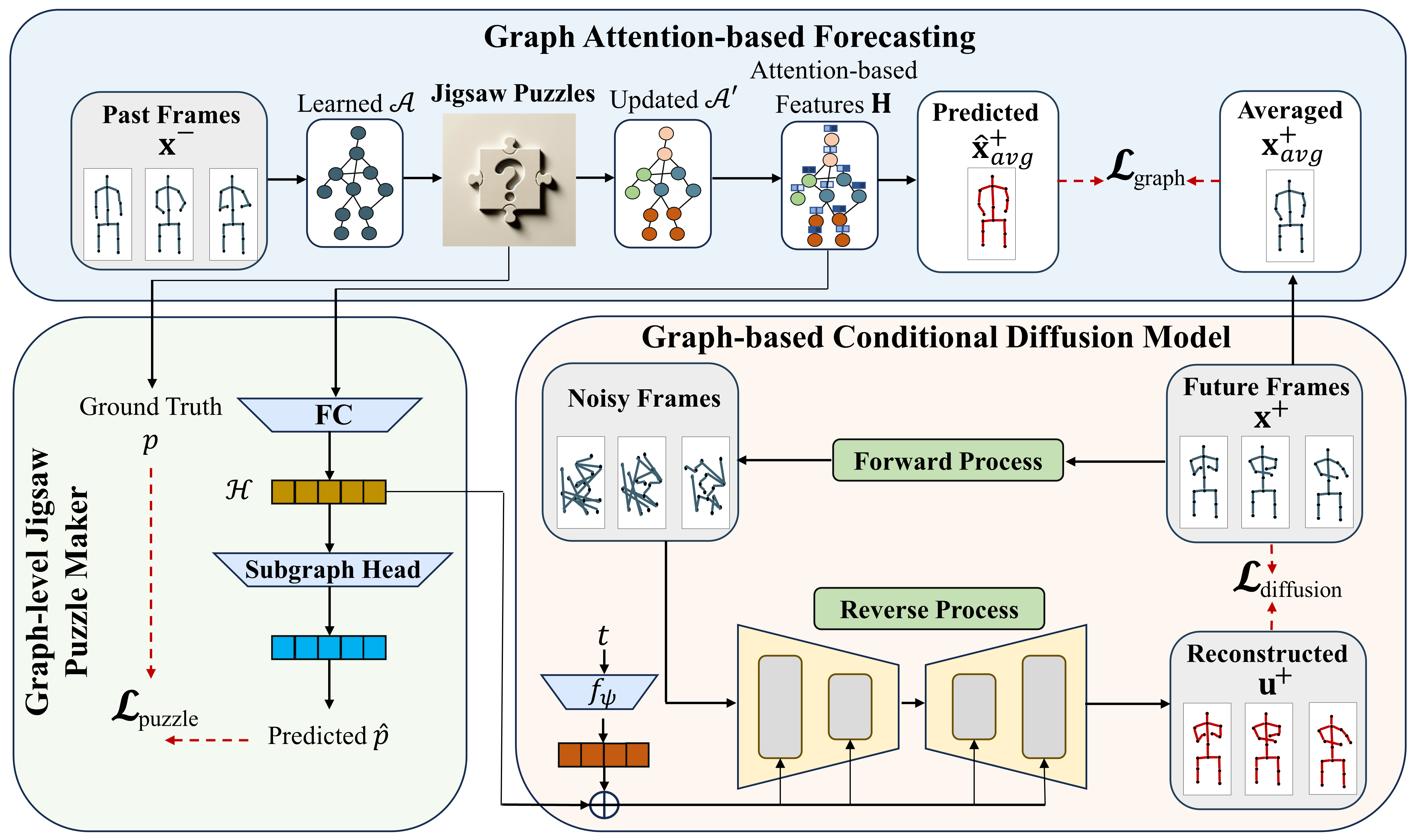
The model first extracts 3D human skeleton joints from the input video frames. It then constructs a graph structure by connecting the joints, where each node represents a joint and the edges capture the spatial relationships.
Next, the model randomly shuffles or 'jigsaw-s' the graph nodes to create a corrupted version of the original skeleton graph. A diffusion process is used to gradually reconstruct the original graph from this corrupted input. This self-supervised jigsaw puzzle task forces the model to learn the underlying structure and dynamics of human movements.
The trained model can then be used for anomaly detection by identifying video frames where the extracted skeleton graph deviates significantly from the learned 'normal' patterns. This approach outperforms methods that only consider the visual appearance of the video, as the skeleton-based representations are more directly tied to the kinematics of human actions.
Critical Analysis
The paper presents a novel and promising approach for skeleton-based video anomaly detection. The use of self-supervised learning on graph-structured skeleton data is a key strength, as it allows the model to learn robust representations without the need for costly labeled anomaly data.
However, the paper does not extensively discuss potential limitations or challenges of the proposed method. For example, the model's performance may be sensitive to the quality and completeness of the extracted skeleton data, which can be noisy or inaccurate in real-world scenarios.
Additionally, the paper does not explore the model's interpretability or provide insights into the specific types of anomalies it is able to detect. Further research is needed to understand the model's failure modes and how it can be adapted for different anomaly detection scenarios.
Conclusion
This paper introduces a Graph-Jigsaw Conditioned Diffusion Model for skeleton-based video anomaly detection. By leveraging self-supervised learning on graph-structured skeleton data, the model can learn powerful representations that effectively identify unusual activities in videos.
The promising results on public datasets suggest this approach could have valuable applications in areas like video surveillance, healthcare monitoring, and human-robot interaction. However, further research is needed to fully understand the method's limitations and how it can be refined for real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Graph-Jigsaw Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection
Ali Karami, Thi Kieu Khanh Ho, Narges Armanfard
Skeleton-based video anomaly detection (SVAD) is a crucial task in computer vision. Accurately identifying abnormal patterns or events enables operators to promptly detect suspicious activities, thereby enhancing safety. Achieving this demands a comprehensive understanding of human motions, both at body and region levels, while also accounting for the wide variations of performing a single action. However, existing studies fail to simultaneously address these crucial properties. This paper introduces a novel, practical and lightweight framework, namely Graph-Jigsaw Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection (GiCiSAD) to overcome the challenges associated with SVAD. GiCiSAD consists of three novel modules: the Graph Attention-based Forecasting module to capture the spatio-temporal dependencies inherent in the data, the Graph-level Jigsaw Puzzle Maker module to distinguish subtle region-level discrepancies between normal and abnormal motions, and the Graph-based Conditional Diffusion model to generate a wide spectrum of human motions. Extensive experiments on four widely used skeleton-based video datasets show that GiCiSAD outperforms existing methods with significantly fewer training parameters, establishing it as the new state-of-the-art.
Read more9/4/2024

0
MissionGNN: Hierarchical Multimodal GNN-based Weakly Supervised Video Anomaly Recognition with Mission-Specific Knowledge Graph Generation
Sanggeon Yun, Ryozo Masukawa, Minhyoung Na, Mohsen Imani
In the context of escalating safety concerns across various domains, the tasks of Video Anomaly Detection (VAD) and Video Anomaly Recognition (VAR) have emerged as critically important for applications in intelligent surveillance, evidence investigation, violence alerting, etc. These tasks, aimed at identifying and classifying deviations from normal behavior in video data, face significant challenges due to the rarity of anomalies which leads to extremely imbalanced data and the impracticality of extensive frame-level data annotation for supervised learning. This paper introduces a novel hierarchical graph neural network (GNN) based model MissionGNN that addresses these challenges by leveraging a state-of-the-art large language model and a comprehensive knowledge graph for efficient weakly supervised learning in VAR. Our approach circumvents the limitations of previous methods by avoiding heavy gradient computations on large multimodal models and enabling fully frame-level training without fixed video segmentation. Utilizing automated, mission-specific knowledge graph generation, our model provides a practical and efficient solution for real-time video analysis without the constraints of previous segmentation-based or multimodal approaches. Experimental validation on benchmark datasets demonstrates our model's performance in VAD and VAR, highlighting its potential to redefine the landscape of anomaly detection and recognition in video surveillance systems.
Read more6/28/2024
❗
0
Contracting Skeletal Kinematics for Human-Related Video Anomaly Detection
Alessandro Flaborea, Guido D'Amely, Stefano D'Arrigo, Marco Aurelio Sterpa, Alessio Sampieri, Fabio Galasso
Detecting the anomaly of human behavior is paramount to timely recognizing endangering situations, such as street fights or elderly falls. However, anomaly detection is complex since anomalous events are rare and because it is an open set recognition task, i.e., what is anomalous at inference has not been observed at training. We propose COSKAD, a novel model that encodes skeletal human motion by a graph convolutional network and learns to COntract SKeletal kinematic embeddings onto a latent hypersphere of minimum volume for Video Anomaly Detection. We propose three latent spaces: the commonly-adopted Euclidean and the novel spherical and hyperbolic. All variants outperform the state-of-the-art on the most recent UBnormal dataset, for which we contribute a human-related version with annotated skeletons. COSKAD sets a new state-of-the-art on the human-related versions of ShanghaiTech Campus and CUHK Avenue, with performance comparable to video-based methods. Source code and dataset will be released upon acceptance.
Read more7/24/2024
0
Video Anomaly Detection via Spatio-Temporal Pseudo-Anomaly Generation : A Unified Approach
Ayush K. Rai, Tarun Krishna, Feiyan Hu, Alexandru Drimbarean, Kevin McGuinness, Alan F. Smeaton, Noel E. O'Connor
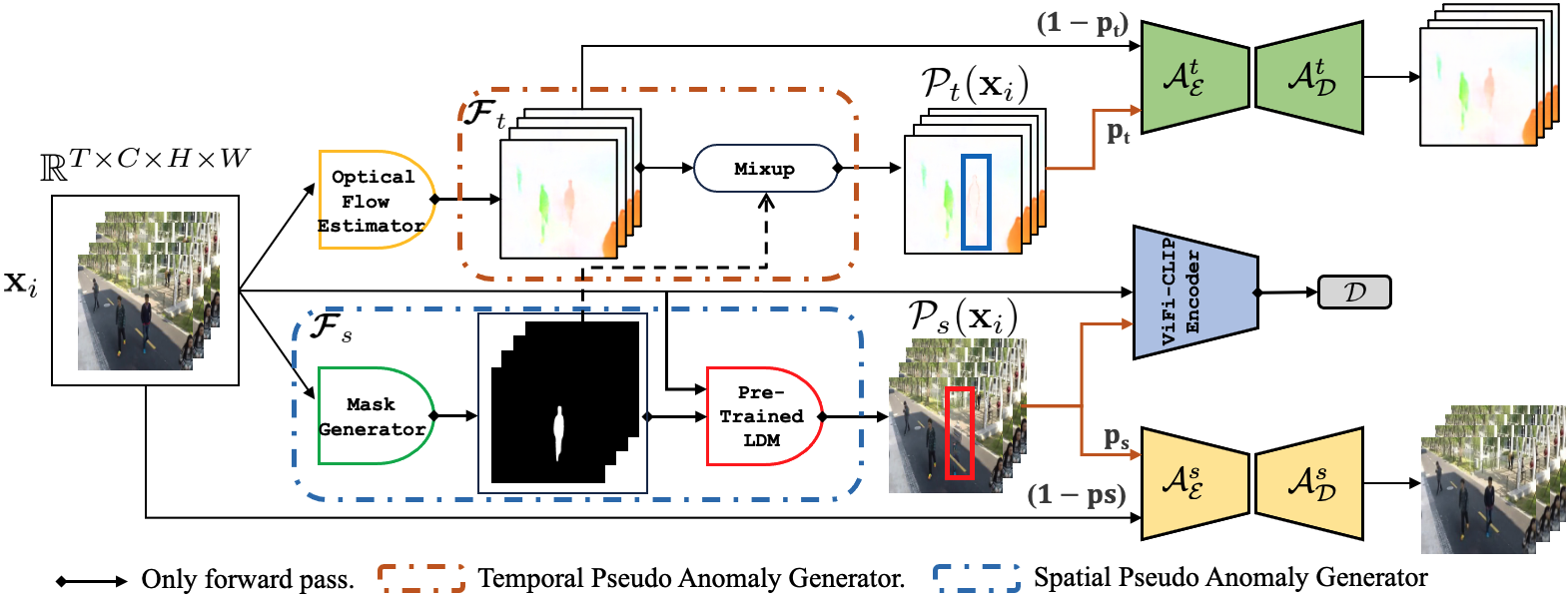
Video Anomaly Detection (VAD) is an open-set recognition task, which is usually formulated as a one-class classification (OCC) problem, where training data is comprised of videos with normal instances while test data contains both normal and anomalous instances. Recent works have investigated the creation of pseudo-anomalies (PAs) using only the normal data and making strong assumptions about real-world anomalies with regards to abnormality of objects and speed of motion to inject prior information about anomalies in an autoencoder (AE) based reconstruction model during training. This work proposes a novel method for generating generic spatio-temporal PAs by inpainting a masked out region of an image using a pre-trained Latent Diffusion Model and further perturbing the optical flow using mixup to emulate spatio-temporal distortions in the data. In addition, we present a simple unified framework to detect real-world anomalies under the OCC setting by learning three types of anomaly indicators, namely reconstruction quality, temporal irregularity and semantic inconsistency. Extensive experiments on four VAD benchmark datasets namely Ped2, Avenue, ShanghaiTech and UBnormal demonstrate that our method performs on par with other existing state-of-the-art PAs generation and reconstruction based methods under the OCC setting. Our analysis also examines the transferability and generalisation of PAs across these datasets, offering valuable insights by identifying real-world anomalies through PAs.
Read more4/9/2024