DA-MoE: Towards Dynamic Expert Allocation for Mixture-of-Experts Models

0

Sign in to get full access
Overview
- The paper introduces a new approach called DA-MoE (Dynamic Expert Allocation for Mixture-of-Experts Models) to improve the performance and efficiency of Mixture-of-Experts (MoE) models.
- MoE models use a set of specialized "expert" subnetworks, each focused on a particular task, along with a "router" that dynamically assigns inputs to the appropriate experts.
- DA-MoE aims to enhance this dynamic routing mechanism to better leverage the experts and improve overall model performance.
Plain English Explanation
The paper introduces a new technique called DA-MoE that aims to make Mixture-of-Experts (MoE) models more effective and efficient. MoE models work by having a set of specialized "expert" subnetworks, each focused on a different task, along with a "router" that dynamically assigns inputs to the appropriate experts.
The key idea behind DA-MoE is to enhance this dynamic routing mechanism to better leverage the expert subnetworks and improve the overall performance of the model. This is done through an attention-based mechanism that analyzes the importance of each input token to determine which experts are most relevant. By dynamically allocating inputs to the most appropriate experts, DA-MoE aims to achieve better results than traditional MoE approaches.
Technical Explanation
The DA-MoE model uses an attention-based mechanism to dynamically route input tokens to the most relevant expert subnetworks. This mechanism analyzes the importance of each input token and uses that information to determine the optimal allocation of tokens to experts.
The authors introduce a token importance module that learns to predict the importance of each token, which is then used by the routing mechanism to guide the dynamic allocation of tokens to experts. This allows the model to focus on the most relevant parts of the input when making decisions, potentially improving overall performance.
The DA-MoE architecture is evaluated on several benchmark tasks, and the results demonstrate improvements in both model performance and efficiency compared to traditional MoE approaches and other state-of-the-art models.
Critical Analysis
The paper presents a novel and promising approach to improving the performance of Mixture-of-Experts (MoE) models. The attention-based mechanism for dynamic token allocation is a key contribution, as it allows the model to focus on the most relevant parts of the input.
However, the paper does not address potential limitations or caveats of the DA-MoE approach. For example, it would be useful to understand how the model performs on more complex or diverse datasets, or how it scales as the number of experts increases. Additionally, the authors could explore the interpretability of the token importance module and how it can provide insights into the model's decision-making process.
Further research could also investigate the generalizability of the DA-MoE approach to other types of neural network architectures, such as Transformers, or explore ways to make the dynamic routing mechanism more efficient or scalable.
Conclusion
The DA-MoE model presents a promising approach to enhancing the performance and efficiency of Mixture-of-Experts (MoE) models. By incorporating an attention-based mechanism for dynamic token allocation, the model is able to better leverage the specialized expert subnetworks and improve overall results.
This research contributes to the ongoing efforts to make large-scale neural networks more efficient and adaptable, which could have significant implications for a wide range of applications in natural language processing, computer vision, and other domains. As the field of machine learning continues to evolve, innovative techniques like DA-MoE will play an important role in pushing the boundaries of what is possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DA-MoE: Towards Dynamic Expert Allocation for Mixture-of-Experts Models
Maryam Akhavan Aghdam, Hongpeng Jin, Yanzhao Wu
Transformer-based Mixture-of-Experts (MoE) models have been driving several recent technological advancements in Natural Language Processing (NLP). These MoE models adopt a router mechanism to determine which experts to activate for routing input tokens. However, existing router mechanisms allocate a fixed number of experts to each token, which neglects the varying importance of different input tokens. In this study, we propose a novel dynamic router mechanism that Dynamically Allocates a variable number of experts for Mixture-of-Experts (DA-MoE) models based on an effective token importance measure. First, we show that the Transformer attention mechanism provides a natural and effective way of calculating token importance. Second, we propose a dynamic router mechanism that effectively decides the optimal number of experts (K) and allocates the top-K experts for each input token. Third, comprehensive experiments on several benchmark datasets demonstrate that our DA-MoE approach consistently outperforms the state-of-the-art Transformer based MoE model on the popular GLUE benchmark.
Read more9/11/2024
🔄
0
Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models
Yongxin Guo, Zhenglin Cheng, Xiaoying Tang, Tao Lin
The Sparse Mixture of Experts (SMoE) has been widely employed to enhance the efficiency of training and inference for Transformer-based foundational models, yielding promising results. However, the performance of SMoE heavily depends on the choice of hyper-parameters, such as the number of experts and the number of experts to be activated (referred to as top-k), resulting in significant computational overhead due to the extensive model training by searching over various hyper-parameter configurations. As a remedy, we introduce the Dynamic Mixture of Experts (DynMoE) technique. DynMoE incorporates (1) a novel gating method that enables each token to automatically determine the number of experts to activate. (2) An adaptive process automatically adjusts the number of experts during training. Extensive numerical results across Vision, Language, and Vision-Language tasks demonstrate the effectiveness of our approach to achieve competitive performance compared to GMoE for vision and language tasks, and MoE-LLaVA for vision-language tasks, while maintaining efficiency by activating fewer parameters. Our code is available at https://github.com/LINs-lab/DynMoE.
Read more5/24/2024
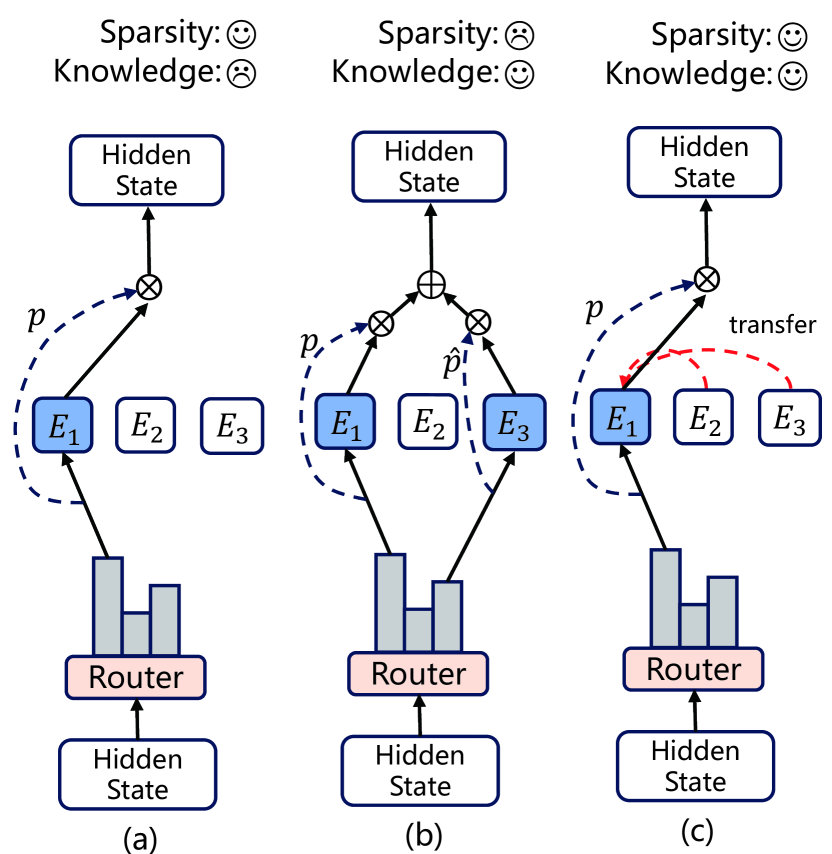
0
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
Read more7/26/2024

0
LocMoE+: Enhanced Router with Token Feature Awareness for Efficient LLM Pre-Training
Jing Li, Zhijie Sun, Dachao Lin, Xuan He, Yi Lin, Binfan Zheng, Li Zeng, Rongqian Zhao, Xin Chen
Mixture-of-Experts (MoE) architectures have emerged as a paradigm-shifting approach for large language models (LLMs), offering unprecedented computational efficiency. However, these architectures grapple with challenges of token distribution imbalance and expert homogenization, impeding optimal semantic generalization. We introduce a novel framework that redefines MoE routing through affinity-driven active selection. The innovations for the framework encompass: (1) A rigorous formulation of expert-token affinity metrics. (2) An adaptive bidirectional selection mechanism leveraging resonance between experts and tokens. (3) Theoretical derivation and experimental evidence of reduced expert capacity bounds under dynamic token distribution evolution. It is also integrated with orthogonal feature extraction module and an optimized loss function for expert localization. Our theoretical analysis demonstrates that this approach mitigates expert homogenization while enabling substantial capacity boundary reduction. Experimental validation corroborates these findings: it achieves a 40% reduction in token processed by each expert without compromising model convergence or efficacy. When coupled with communication optimizations, the training efficiency improvements of 5.4% to 46.6% can be observed. After supervised fine-tuning, it exhibits performance gains of 9.7% to 14.1% across GDAD, C-Eval, and TeleQnA benchmarks.
Read more9/2/2024