DAE-Net: Deforming Auto-Encoder for fine-grained shape co-segmentation

0
🧠
Sign in to get full access
Overview
- The paper presents an unsupervised method for 3D shape co-segmentation, where a set of deformable part templates are learned from a collection of 3D shapes.
- The method allows for structural variations in the shape collection by composing each shape from a selected subset of transformed template parts.
- A per-part deformation network is introduced to model diverse parts with substantial geometry variations, while constraining the deformation to maintain fidelity to the original part representations.
- A training scheme is proposed to effectively overcome local minima during the unsupervised learning process.
- The network, called DAE-Net (Deforming Auto-Encoder Network), demonstrates superior performance in unsupervised 3D shape co-segmentation compared to prior methods.
Plain English Explanation
The paper describes a new way to automatically break down 3D shapes, like those of objects or characters, into meaningful parts. This is useful for tasks like 3D shape retrieval or shape editing.
The key idea is to learn a set of template parts that can be used to compose the shapes in the collection. However, the shapes may vary in their structure, so the templates need to be able to deform and transform to fit each shape. The network learns how to select the right subset of templates and how to deform them to accurately reconstruct each shape.
This is done in an unsupervised way, without any manual labeling of the parts. The network learns the part templates and the deformation rules solely by looking at the 3D shapes themselves. This allows the method to work on diverse shape collections and discover meaningful part segmentations automatically.
Technical Explanation
The paper presents the "Deforming Auto-Encoder Network" (DAE-Net), an unsupervised 3D shape co-segmentation method. The network takes a 3D shape, represented as a voxel grid, as input and produces a reconstruction of the shape by composing a selected subset of deformable part templates.
The key components of the network are:
-
Part Template Encoder: A convolutional neural network (CNN) that encodes the input shape into a set of part transformation matrices, latent codes, and part existence scores. This allows the network to select which template parts to use and how to transform them.
-
Part Deformation Network: For each template part, a separate sub-network models the diverse geometry variations by predicting deformations from the latent codes. This allows the templates to accurately fit the input shape while maintaining the fidelity of the original part representations.
-
Part-based Decoder: The decoder takes the transformed and deformed part templates and combines them to reconstruct the output shape as a set of point occupancies.
The network is trained in an unsupervised manner, without any ground truth part segmentations. To address the challenge of local minima, the authors propose a training scheme that gradually increases the part complexity and deformation capacity during the optimization process.
The DAE-Net is evaluated on several 3D shape datasets, including ShapeNet Parts, DFAUST, and an animal subset of Objaverse. The results demonstrate that the method can discover fine-grained, compact, and semantically meaningful part segmentations that are consistent across diverse shapes, outperforming previous unsupervised 3D shape co-segmentation approaches.
Critical Analysis
The paper presents a well-designed and principled approach to the challenging problem of unsupervised 3D shape co-segmentation. The key innovations, such as the deformable part templates and the gradual training scheme, seem well-justified and effective based on the reported results.
One potential limitation is the reliance on voxel grid representations of the 3D shapes, which can be memory-intensive and may not capture fine details as effectively as point cloud or mesh-based representations. It would be interesting to see how the method could be adapted to work with these alternative shape representations.
Additionally, the paper does not provide much discussion on the computational complexity or runtime performance of the proposed method. As 3D shape processing can be computationally demanding, the scalability and practical applicability of the approach could be an important consideration for real-world applications.
While the experiments demonstrate the method's effectiveness on several benchmark datasets, it would be valuable to see further evaluation on a broader range of 3D shapes, including more complex and diverse object categories. This could help validate the generalizability of the approach and identify any potential limitations or failure cases.
Overall, the paper presents a compelling and technically sound solution to the 3D shape co-segmentation problem, with promising directions for future research and development. Readers are encouraged to think critically about the method's strengths, limitations, and potential impact on the field of 3D shape analysis and processing.
Conclusion
The presented DAE-Net method offers a novel approach to unsupervised 3D shape co-segmentation, addressing the challenge of modeling structural variations in shape collections. By learning deformable part templates and a part deformation network, the method can discover fine-grained, semantically meaningful part decompositions that are consistent across diverse 3D shapes.
The technical innovations, such as the branched autoencoder architecture and the gradual training scheme, demonstrate the authors' thoughtful approach to overcoming the difficulties of unsupervised part-based shape modeling. The promising results on various 3D shape datasets suggest that this work could have significant implications for applications in areas like 3D shape retrieval, shape editing, and part-based 3D shape analysis.
As the field of 3D shape processing continues to evolve, methods like DAE-Net that can automatically discover the underlying part structure of 3D shapes in an unsupervised manner will become increasingly valuable. The authors' work represents an important step forward in this direction, paving the way for further advancements in 3D shape segmentation and shape understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
DAE-Net: Deforming Auto-Encoder for fine-grained shape co-segmentation
Zhiqin Chen, Qimin Chen, Hang Zhou, Hao Zhang
We present an unsupervised 3D shape co-segmentation method which learns a set of deformable part templates from a shape collection. To accommodate structural variations in the collection, our network composes each shape by a selected subset of template parts which are affine-transformed. To maximize the expressive power of the part templates, we introduce a per-part deformation network to enable the modeling of diverse parts with substantial geometry variations, while imposing constraints on the deformation capacity to ensure fidelity to the originally represented parts. We also propose a training scheme to effectively overcome local minima. Architecturally, our network is a branched autoencoder, with a CNN encoder taking a voxel shape as input and producing per-part transformation matrices, latent codes, and part existence scores, and the decoder outputting point occupancies to define the reconstruction loss. Our network, coined DAE-Net for Deforming Auto-Encoder, can achieve unsupervised 3D shape co-segmentation that yields fine-grained, compact, and meaningful parts that are consistent across diverse shapes. We conduct extensive experiments on the ShapeNet Part dataset, DFAUST, and an animal subset of Objaverse to show superior performance over prior methods. Code and data are available at https://github.com/czq142857/DAE-Net.
Read more4/29/2024
🖼️
0
New!DAE-Fuse: An Adaptive Discriminative Autoencoder for Multi-Modality Image Fusion
Yuchen Guo, Ruoxiang Xu, Rongcheng Li, Zhenghao Wu, Weifeng Su
Multi-modality image fusion aims to integrate complementary data information from different imaging modalities into a single image. Existing methods often generate either blurry fused images that lose fine-grained semantic information or unnatural fused images that appear perceptually cropped from the inputs. In this work, we propose a novel two-phase discriminative autoencoder framework, termed DAE-Fuse, that generates sharp and natural fused images. In the adversarial feature extraction phase, we introduce two discriminative blocks into the encoder-decoder architecture, providing an additional adversarial loss to better guide feature extraction by reconstructing the source images. While the two discriminative blocks are adapted in the attention-guided cross-modality fusion phase to distinguish the structural differences between the fused output and the source inputs, injecting more naturalness into the results. Extensive experiments on public infrared-visible, medical image fusion, and downstream object detection datasets demonstrate our method's superiority and generalizability in both quantitative and qualitative evaluations.
Read more9/17/2024
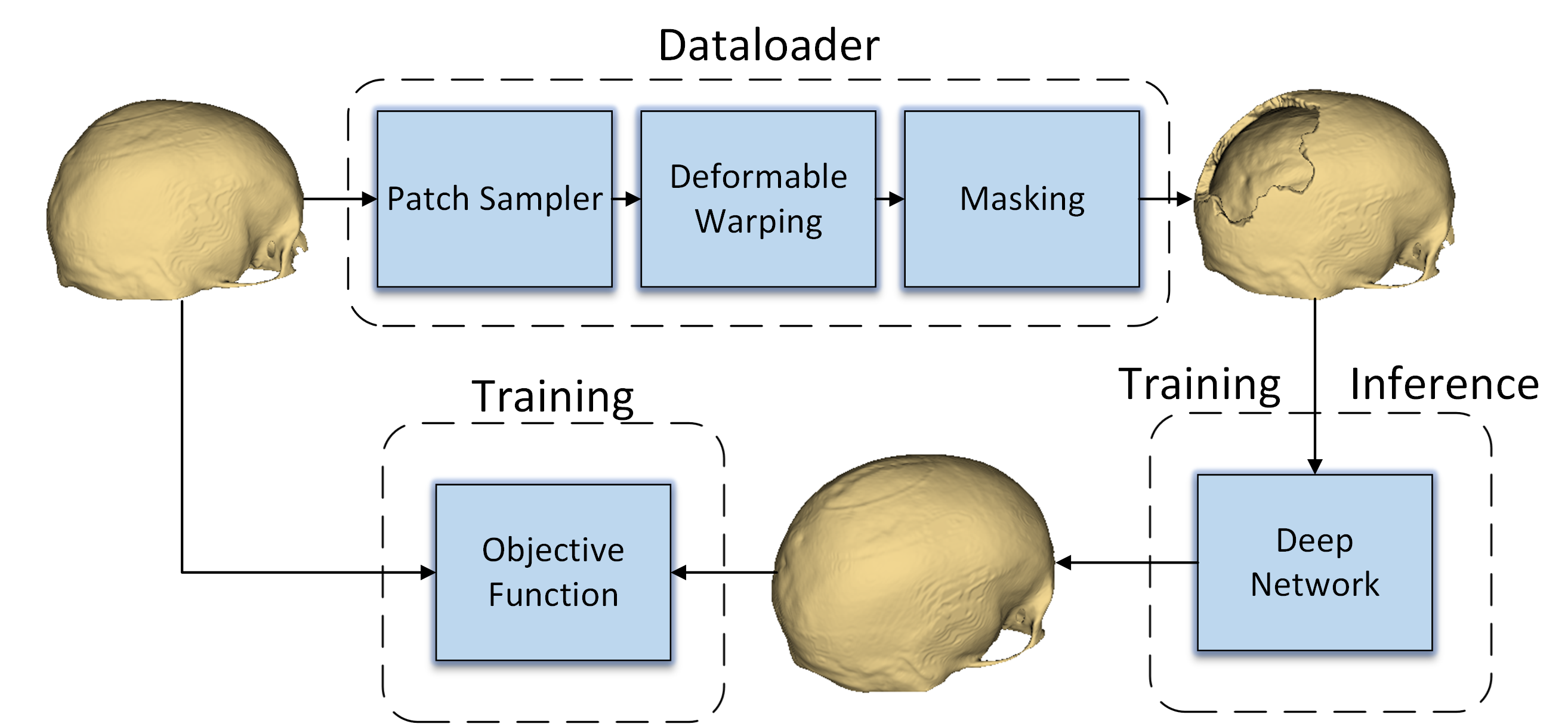
0
Automatic Cranial Defect Reconstruction with Self-Supervised Deep Deformable Masked Autoencoders
Marek Wodzinski, Daria Hemmerling, Mateusz Daniol
Thousands of people suffer from cranial injuries every year. They require personalized implants that need to be designed and manufactured before the reconstruction surgery. The manual design is expensive and time-consuming leading to searching for algorithms whose goal is to automatize the process. The problem can be formulated as volumetric shape completion and solved by deep neural networks dedicated to supervised image segmentation. However, such an approach requires annotating the ground-truth defects which is costly and time-consuming. Usually, the process is replaced with synthetic defect generation. However, even the synthetic ground-truth generation is time-consuming and limits the data heterogeneity, thus the deep models' generalizability. In our work, we propose an alternative and simple approach to use a self-supervised masked autoencoder to solve the problem. This approach by design increases the heterogeneity of the training set and can be seen as a form of data augmentation. We compare the proposed method with several state-of-the-art deep neural networks and show both the quantitative and qualitative improvement on the SkullBreak and SkullFix datasets. The proposed method can be used to efficiently reconstruct the cranial defects in real time.
Read more6/4/2024
🏋️
0
Deformable-Heatmap-Segmentation for Automobile Visual Perception
Hongyu Jin
Semantic segmentation of road elements in 2D images is a crucial task in the recognition of some static objects such as lane lines and free space. In this paper, we propose DHSNet,which extracts the objects features with a end-to-end architecture along with a heatmap proposal. Deformable convolutions are also utilized in the proposed network. The DHSNet finely combines low-level feature maps with high-level ones by using upsampling operators as well as downsampling operators in a U-shape manner. Besides, DHSNet also aims to capture static objects of various shapes and scales. We also predict a proposal heatmap to detect the proposal points for more accurate target aiming in the network.
Read more7/11/2024