Deformable-Heatmap-Segmentation for Automobile Visual Perception

0
🏋️
Sign in to get full access
Overview
- The paper proposes a semantic segmentation model called DHSNet for recognizing static road elements like lane lines and free space in 2D images.
- The model uses a U-shaped architecture with deformable convolutions to extract features at different scales and combine low-level and high-level information.
- It also generates a heatmap proposal to help the network focus on relevant areas for more accurate segmentation.
Plain English Explanation
The goal of this research is to improve the ability of computer vision systems to understand the contents of 2D road images. Semantic segmentation is the process of categorizing each pixel in an image into different semantic classes, such as roads, lane markings, and free space. This is a crucial task for applications like self-driving cars that need to perceive the environment around them.
The key innovation in this paper is the DHSNet model, which has a few important characteristics:
-
U-Shaped Architecture: DHSNet uses a U-shaped architecture that combines low-level visual features (like edges and textures) with high-level semantic information. This allows the model to capture details about the shape and appearance of road elements while also understanding their overall context.
-
Deformable Convolutions: The model employs deformable convolutions, which can adapt their shape to better fit the structures in the input image. This helps the network handle the diverse shapes and scales of road objects.
-
Heatmap Proposal: In addition to the segmentation output, DHSNet also produces a heatmap that highlights the most important regions for detecting road elements. This "attention" mechanism allows the network to focus its processing power on the relevant areas, leading to more accurate results.
By combining these innovative techniques, the DHSNet model is able to perform semantic segmentation of road scenes more effectively than previous approaches. This has important applications in autonomous driving and other transportation-related computer vision tasks.
Technical Explanation
The key technical components of the DHSNet model are:
-
U-Shaped Architecture: DHSNet follows a U-Net-like architecture with an encoder-decoder structure. The encoder extracts features at multiple scales using a series of convolution and pooling layers. The decoder then upsamples these features and combines them to produce the final segmentation map.
-
Deformable Convolutions: Instead of using standard convolution layers, DHSNet incorporates deformable convolutions. These can adaptively modify their receptive fields to better fit the geometric structures in the input, improving the model's ability to handle objects of varying shapes and scales.
-
Heatmap Proposal: In addition to the segmentation output, the network also generates a heatmap that highlights the most salient regions for detecting road elements. This "attention" mechanism helps the model focus its processing power on the relevant areas, leading to more accurate segmentation results.
The authors evaluate DHSNet on several road scene segmentation datasets and show that it outperforms previous state-of-the-art methods. The model achieves high accuracy in identifying key road elements like lane markings, curbs, and free space, demonstrating its effectiveness for applications like autonomous driving.
Critical Analysis
The paper provides a comprehensive evaluation of the DHSNet model, exploring its performance on multiple road scene segmentation benchmarks. However, there are a few potential limitations and areas for further research that could be considered:
-
Generalization Ability: While the model performs well on the evaluated datasets, it's unclear how it would generalize to more diverse or unseen road environments. Expanding the evaluation to a wider range of real-world scenarios could help assess the model's robustness.
-
Computational Efficiency: The use of deformable convolutions and the heatmap proposal mechanism may increase the computational complexity of the model. Investigating ways to improve its efficiency, potentially through model pruning or knowledge distillation techniques, could make it more suitable for real-time applications.
-
Interpretability: As with many deep learning models, the internal workings of DHSNet may be difficult to interpret. Exploring methods to better explain the model's decision-making process could increase trust and transparency, particularly in safety-critical applications like autonomous driving.
-
Multimodal Integration: The current model only operates on 2D image data. Integrating information from other sensors, such as LiDAR or radar, could further enhance the model's understanding of the 3D road environment, as explored in Segnet4D.
Overall, the DHSNet model represents a valuable contribution to the field of road scene understanding, with potential applications in autonomous driving and other transportation-related computer vision tasks. Addressing the suggested areas for improvement could further strengthen the model's performance and practical utility.
Conclusion
The paper proposes a semantic segmentation model called DHSNet that is designed to accurately recognize static road elements, such as lane markings and free space, in 2D images. The key innovations of the model include a U-shaped architecture with deformable convolutions to handle diverse object shapes and scales, as well as a heatmap proposal mechanism to guide the network's attention to the most relevant regions.
Experimental results demonstrate that DHSNet outperforms previous state-of-the-art methods in road scene segmentation, indicating its potential for important applications like autonomous driving. While the model shows promising performance, further research could explore its generalization ability, computational efficiency, interpretability, and integration with multimodal sensor data to enhance its real-world deployment and impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Deformable-Heatmap-Segmentation for Automobile Visual Perception
Hongyu Jin
Semantic segmentation of road elements in 2D images is a crucial task in the recognition of some static objects such as lane lines and free space. In this paper, we propose DHSNet,which extracts the objects features with a end-to-end architecture along with a heatmap proposal. Deformable convolutions are also utilized in the proposed network. The DHSNet finely combines low-level feature maps with high-level ones by using upsampling operators as well as downsampling operators in a U-shape manner. Besides, DHSNet also aims to capture static objects of various shapes and scales. We also predict a proposal heatmap to detect the proposal points for more accurate target aiming in the network.
Read more7/11/2024

0
Deformable Convolution Based Road Scene Semantic Segmentation of Fisheye Images in Autonomous Driving
Anam Manzoor, Aryan Singh, Ganesh Sistu, Reenu Mohandas, Eoin Grua, Anthony Scanlan, Ciar'an Eising
This study investigates the effectiveness of modern Deformable Convolutional Neural Networks (DCNNs) for semantic segmentation tasks, particularly in autonomous driving scenarios with fisheye images. These images, providing a wide field of view, pose unique challenges for extracting spatial and geometric information due to dynamic changes in object attributes. Our experiments focus on segmenting the WoodScape fisheye image dataset into ten distinct classes, assessing the Deformable Networks' ability to capture intricate spatial relationships and improve segmentation accuracy. Additionally, we explore different loss functions to address class imbalance issues and compare the performance of conventional CNN architectures with Deformable Convolution-based CNNs, including Vanilla U-Net and Residual U-Net architectures. The significant improvement in mIoU score resulting from integrating Deformable CNNs demonstrates their effectiveness in handling the geometric distortions present in fisheye imagery, exceeding the performance of traditional CNN architectures. This underscores the significant role of Deformable convolution in enhancing semantic segmentation performance for fisheye imagery.
Read more7/24/2024
🧠
0
DAE-Net: Deforming Auto-Encoder for fine-grained shape co-segmentation
Zhiqin Chen, Qimin Chen, Hang Zhou, Hao Zhang
We present an unsupervised 3D shape co-segmentation method which learns a set of deformable part templates from a shape collection. To accommodate structural variations in the collection, our network composes each shape by a selected subset of template parts which are affine-transformed. To maximize the expressive power of the part templates, we introduce a per-part deformation network to enable the modeling of diverse parts with substantial geometry variations, while imposing constraints on the deformation capacity to ensure fidelity to the originally represented parts. We also propose a training scheme to effectively overcome local minima. Architecturally, our network is a branched autoencoder, with a CNN encoder taking a voxel shape as input and producing per-part transformation matrices, latent codes, and part existence scores, and the decoder outputting point occupancies to define the reconstruction loss. Our network, coined DAE-Net for Deforming Auto-Encoder, can achieve unsupervised 3D shape co-segmentation that yields fine-grained, compact, and meaningful parts that are consistent across diverse shapes. We conduct extensive experiments on the ShapeNet Part dataset, DFAUST, and an animal subset of Objaverse to show superior performance over prior methods. Code and data are available at https://github.com/czq142857/DAE-Net.
Read more4/29/2024
0
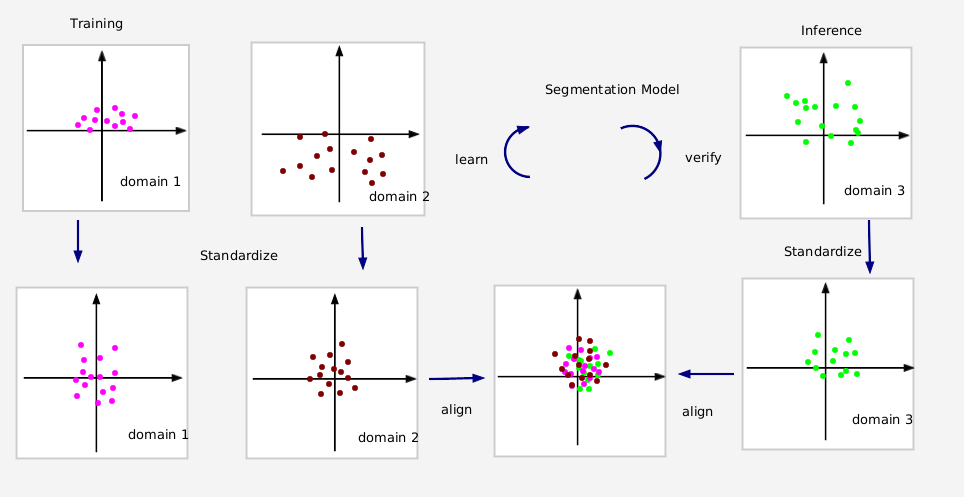
Semantic Segmentation for Real-World and Synthetic Vehicle's Forward-Facing Camera Images
Tuan T. Nguyen, Phan Le, Yasir Hassan, Mina Sartipi
In this paper, we present the submission to the 5th Annual Smoky Mountains Computational Sciences Data Challenge, Challenge 3. This is the solution for semantic segmentation problem in both real-world and synthetic images from a vehicle s forward-facing camera. We concentrate in building a robust model which performs well across various domains of different outdoor situations such as sunny, snowy, rainy, etc. In particular, our method is developed with two main directions: model development and domain adaptation. In model development, we use the High Resolution Network (HRNet) as the baseline. Then, this baseline s result is processed by two coarse-to-fine models: Object-Contextual Representations (OCR) and Hierarchical Multi-scale Attention (HMA) to get the better robust feature. For domain adaption, we implement the Domain-Based Batch Normalization (DNB) to reduce the distribution shift from diverse domains. Our proposed method yield 81.259 mean intersection-over-union (mIoU) in validation set. This paper studies the effectiveness of employing real-world and synthetic data to handle the domain adaptation in semantic segmentation problem.
Read more7/9/2024