Daisy-TTS: Simulating Wider Spectrum of Emotions via Prosody Embedding Decomposition
2402.14523
0
0

Abstract
We often verbally express emotions in a multifaceted manner, they may vary in their intensities and may be expressed not just as a single but as a mixture of emotions. This wide spectrum of emotions is well-studied in the structural model of emotions, which represents variety of emotions as derivative products of primary emotions with varying degrees of intensity. In this paper, we propose an emotional text-to-speech design to simulate a wider spectrum of emotions grounded on the structural model. Our proposed design, Daisy-TTS, incorporates a prosody encoder to learn emotionally-separable prosody embedding as a proxy for emotion. This emotion representation allows the model to simulate: (1) Primary emotions, as learned from the training samples, (2) Secondary emotions, as a mixture of primary emotions, (3) Intensity-level, by scaling the emotion embedding, and (4) Emotions polarity, by negating the emotion embedding. Through a series of perceptual evaluations, Daisy-TTS demonstrated overall higher emotional speech naturalness and emotion perceiveability compared to the baseline.
Create account to get full access
Overview
- The paper presents a text-to-speech (TTS) system called Daisy-TTS that aims to simulate a wider spectrum of emotions through prosody embedding decomposition.
- Prosody refers to the rhythm, stress, and intonation of speech, which can convey emotional information.
- Daisy-TTS decomposes the prosody embedding into separate components for pitch, energy, and duration, allowing for more fine-grained control and expression of emotions.
- The system is trained on a large dataset of emotional speech and demonstrates its ability to generate speech with a broader range of emotional styles compared to previous TTS models.
Plain English Explanation
The research paper describes a new text-to-speech (TTS) system called Daisy-TTS that can produce speech with a wider range of emotional tones. TTS systems are used to convert written text into spoken language, but they often struggle to capture the nuances of human emotion in the way we speak.
Daisy-TTS addresses this by breaking down the different aspects of speech, known as prosody, into separate components. Prosody refers to the rhythm, emphasis, and pitch of speech, which can convey emotional meaning. By separating the prosody into distinct parts for pitch, energy (volume), and duration, the researchers were able to give the TTS system more fine-grained control over how it expresses different emotions.
For example, if the system wants to generate an angry-sounding voice, it can adjust the pitch to be higher, the energy to be louder, and the duration of words to be shorter. Similarly, a sad voice might have a lower pitch, softer energy, and longer pauses between words.
The researchers trained Daisy-TTS on a large dataset of emotional speech samples, allowing the system to learn how to realistically simulate a wide range of emotional tones. This represents an improvement over previous TTS models, which were more limited in the emotional expressiveness they could achieve.
By being able to generate speech with a broader emotional spectrum, Daisy-TTS could have applications in areas like virtual assistants, audiobook narration, and language translation, where conveying the appropriate emotion is important for creating a natural and engaging user experience.
Technical Explanation
The key innovation of the Daisy-TTS system is its prosody embedding decomposition approach. Prosody refers to the rhythm, stress, and intonation of speech, which can convey emotional information. Previous TTS models have typically represented prosody as a single, combined embedding, limiting their ability to independently control and express different emotional dimensions.
Daisy-TTS decomposes the prosody embedding into separate components for pitch, energy, and duration. This allows the system to more precisely manipulate these prosodic features to simulate a wider range of emotional styles. The model is trained on a large dataset of emotional speech, learning to associate specific pitch, energy, and duration patterns with different emotional expressions.
During inference, Daisy-TTS takes in text input and generates the corresponding speech waveform. The system's prosody generator module decomposes the target prosody embedding into the separate pitch, energy, and duration components. These are then used to condition the acoustic generator module, which produces the final speech output with the desired emotional characteristics.
The researchers evaluate Daisy-TTS on several benchmarks, including emotional speech synthesis and prosody transfer tasks. The results demonstrate that Daisy-TTS can generate speech with a broader emotional spectrum compared to previous state-of-the-art TTS models. Qualitative assessments by human listeners also confirm the system's ability to convey a wider range of emotional styles.
Critical Analysis
The Daisy-TTS system represents an important step forward in emotional speech synthesis, but there are some potential limitations and areas for further exploration:
-
Generalization to Novel Emotions: While Daisy-TTS shows impressive results on the emotional styles present in its training data, it's unclear how well the system would generalize to completely novel emotional expressions. Additional research may be needed to assess its ability to adapt to less common or more nuanced emotional states.
-
Interactions Between Prosodic Components: The paper assumes that the pitch, energy, and duration components of prosody can be manipulated independently. However, in natural speech, these prosodic features often interact in complex ways to convey emotion. Investigating these interdependencies could lead to even more realistic emotional speech synthesis.
-
Multimodal Emotion Expression: Emotions are not only expressed through speech prosody but also through facial expressions, body language, and other modalities. Future work could explore incorporating these additional channels of emotional information to create even more convincing and immersive TTS experiences.
-
Exploring Speech Style Spaces with Language Models: The paper's approach to decomposing prosody could potentially be combined with language model-based techniques for generating emotional speech styles, leading to even more expressive and versatile TTS capabilities.
Overall, the Daisy-TTS system represents an important advancement in the field of emotional speech synthesis, and the researchers' prosody embedding decomposition approach is a valuable contribution. Continued research in this area could lead to TTS systems that can more accurately and meaningfully convey the rich emotional nuances of human communication.
Conclusion
The Daisy-TTS system presented in this paper is a significant step forward in the field of text-to-speech (TTS) technology. By decomposing the prosody embedding into separate components for pitch, energy, and duration, the system is able to simulate a wider spectrum of emotional expressions in the generated speech.
This advance could have important implications for a variety of applications, such as virtual assistants, audiobook narration, and language translation, where conveying the appropriate emotional tone is crucial for creating a natural and engaging user experience.
While the Daisy-TTS system demonstrates impressive results, there are still opportunities for further research to address limitations, such as generalizing to novel emotional states and exploring the interplay between different prosodic components. Incorporating additional modalities of emotional expression could also lead to even more realistic and immersive TTS experiences.
Overall, the Daisy-TTS paper represents an important contribution to the field of emotional speech synthesis, and the researchers' prosody embedding decomposition approach could serve as a foundation for future advancements in this rapidly evolving area of AI and natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
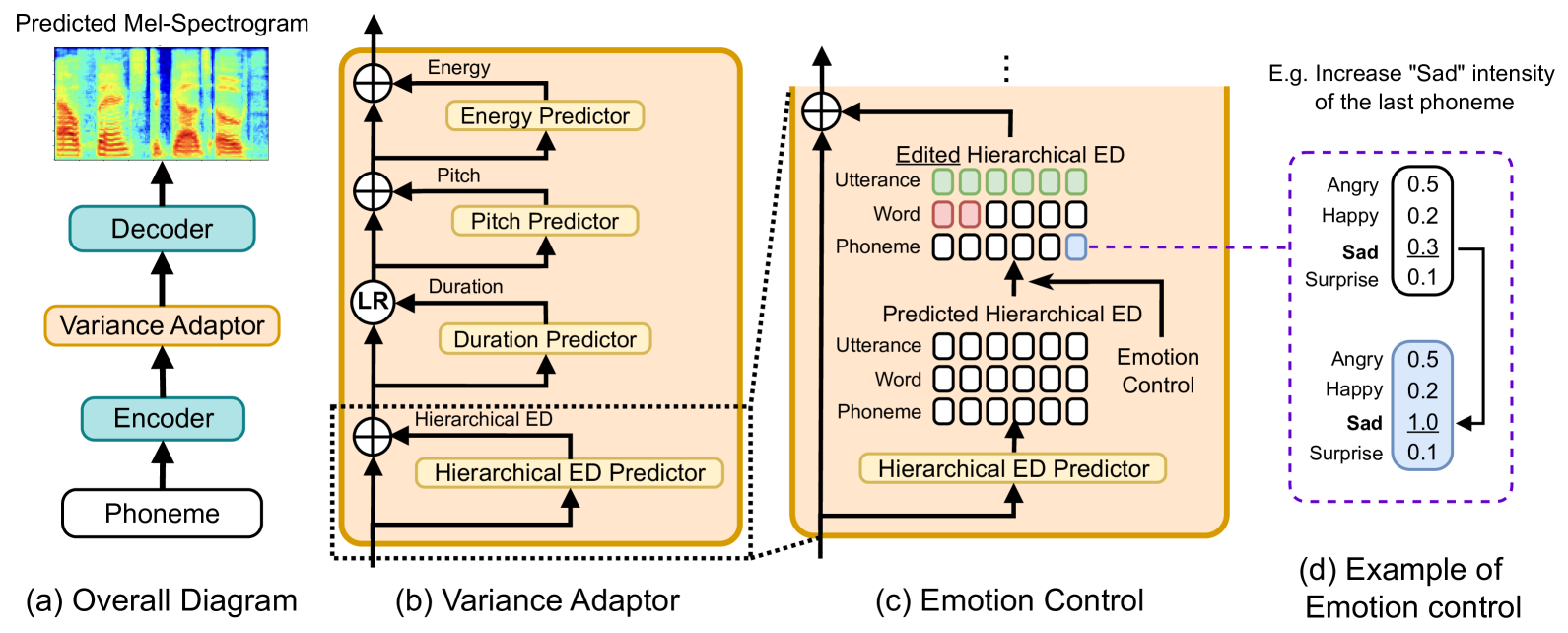
Hierarchical Emotion Prediction and Control in Text-to-Speech Synthesis
Sho Inoue, Kun Zhou, Shuai Wang, Haizhou Li
0
0
It remains a challenge to effectively control the emotion rendering in text-to-speech (TTS) synthesis. Prior studies have primarily focused on learning a global prosodic representation at the utterance level, which strongly correlates with linguistic prosody. Our goal is to construct a hierarchical emotion distribution (ED) that effectively encapsulates intensity variations of emotions at various levels of granularity, encompassing phonemes, words, and utterances. During TTS training, the hierarchical ED is extracted from the ground-truth audio and guides the predictor to establish a connection between emotional and linguistic prosody. At run-time inference, the TTS model generates emotional speech and, at the same time, provides quantitative control of emotion over the speech constituents. Both objective and subjective evaluations validate the effectiveness of the proposed framework in terms of emotion prediction and control.
5/16/2024

EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
Deok-Hyeon Cho, Hyung-Seok Oh, Seung-Bin Kim, Sang-Hoon Lee, Seong-Whan Lee
0
0
Despite rapid advances in the field of emotional text-to-speech (TTS), recent studies primarily focus on mimicking the average style of a particular emotion. As a result, the ability to manipulate speech emotion remains constrained to several predefined labels, compromising the ability to reflect the nuanced variations of emotion. In this paper, we propose EmoSphere-TTS, which synthesizes expressive emotional speech by using a spherical emotion vector to control the emotional style and intensity of the synthetic speech. Without any human annotation, we use the arousal, valence, and dominance pseudo-labels to model the complex nature of emotion via a Cartesian-spherical transformation. Furthermore, we propose a dual conditional adversarial network to improve the quality of generated speech by reflecting the multi-aspect characteristics. The experimental results demonstrate the model ability to control emotional style and intensity with high-quality expressive speech.
6/13/2024
❗
MM-TTS: A Unified Framework for Multimodal, Prompt-Induced Emotional Text-to-Speech Synthesis
Xiang Li, Zhi-Qi Cheng, Jun-Yan He, Xiaojiang Peng, Alexander G. Hauptmann
0
0
Emotional Text-to-Speech (E-TTS) synthesis has gained significant attention in recent years due to its potential to enhance human-computer interaction. However, current E-TTS approaches often struggle to capture the complexity of human emotions, primarily relying on oversimplified emotional labels or single-modality inputs. To address these limitations, we propose the Multimodal Emotional Text-to-Speech System (MM-TTS), a unified framework that leverages emotional cues from multiple modalities to generate highly expressive and emotionally resonant speech. MM-TTS consists of two key components: (1) the Emotion Prompt Alignment Module (EP-Align), which employs contrastive learning to align emotional features across text, audio, and visual modalities, ensuring a coherent fusion of multimodal information; and (2) the Emotion Embedding-Induced TTS (EMI-TTS), which integrates the aligned emotional embeddings with state-of-the-art TTS models to synthesize speech that accurately reflects the intended emotions. Extensive evaluations across diverse datasets demonstrate the superior performance of MM-TTS compared to traditional E-TTS models. Objective metrics, including Word Error Rate (WER) and Character Error Rate (CER), show significant improvements on ESD dataset, with MM-TTS achieving scores of 7.35% and 3.07%, respectively. Subjective assessments further validate that MM-TTS generates speech with emotional fidelity and naturalness comparable to human speech. Our code and pre-trained models are publicly available at https://anonymous.4open.science/r/MMTTS-D214
4/30/2024
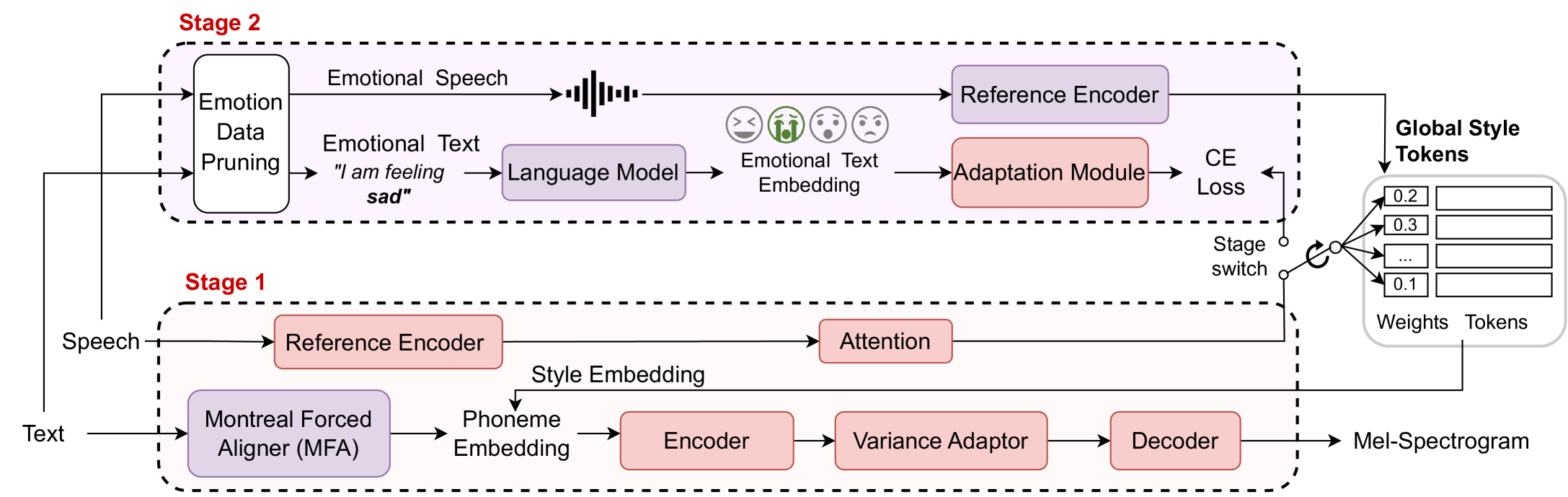
Exploring speech style spaces with language models: Emotional TTS without emotion labels
Shreeram Suresh Chandra, Zongyang Du, Berrak Sisman
0
0
Many frameworks for emotional text-to-speech (E-TTS) rely on human-annotated emotion labels that are often inaccurate and difficult to obtain. Learning emotional prosody implicitly presents a tough challenge due to the subjective nature of emotions. In this study, we propose a novel approach that leverages text awareness to acquire emotional styles without the need for explicit emotion labels or text prompts. We present TEMOTTS, a two-stage framework for E-TTS that is trained without emotion labels and is capable of inference without auxiliary inputs. Our proposed method performs knowledge transfer between the linguistic space learned by BERT and the emotional style space constructed by global style tokens. Our experimental results demonstrate the effectiveness of our proposed framework, showcasing improvements in emotional accuracy and naturalness. This is one of the first studies to leverage the emotional correlation between spoken content and expressive delivery for emotional TTS.
5/21/2024