EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
2406.07803
0
0

Abstract
Despite rapid advances in the field of emotional text-to-speech (TTS), recent studies primarily focus on mimicking the average style of a particular emotion. As a result, the ability to manipulate speech emotion remains constrained to several predefined labels, compromising the ability to reflect the nuanced variations of emotion. In this paper, we propose EmoSphere-TTS, which synthesizes expressive emotional speech by using a spherical emotion vector to control the emotional style and intensity of the synthetic speech. Without any human annotation, we use the arousal, valence, and dominance pseudo-labels to model the complex nature of emotion via a Cartesian-spherical transformation. Furthermore, we propose a dual conditional adversarial network to improve the quality of generated speech by reflecting the multi-aspect characteristics. The experimental results demonstrate the model ability to control emotional style and intensity with high-quality expressive speech.
Create account to get full access
Overview
- This paper presents a new text-to-speech (TTS) system called EmoSphere-TTS that can generate speech with controlled emotional styles and intensities.
- The system uses a spherical emotion vector representation to model emotional content, allowing for continuous control over the emotional expression of the generated speech.
- EmoSphere-TTS is designed to enable more natural and expressive TTS for applications like virtual assistants, audiobook narration, and video game dialog.
Plain English Explanation
EmoSphere-TTS is a new text-to-speech (TTS) system that can create speech with different emotional styles and levels of intensity. Rather than just producing flat, neutral-sounding speech, this system allows for fine-tuned control over the emotional expression.
The key idea is to represent emotions using a 3D spherical coordinate system. This "emotion sphere" allows the system to smoothly adjust things like mood, tone, and emotional intensity. For example, you could make the speech sound happy and energetic, or sad and somber, or anything in between.
This type of emotional control could be very useful for applications where expressive and natural-sounding speech is important, like virtual assistants, audiobook narration, or video game dialog. Instead of a robotic, one-size-fits-all voice, the system can tailor the emotional delivery to better match the context and desired effect.
The researchers developed various neural network models and training techniques to achieve this emotional TTS capability, drawing inspiration from prior work on hierarchical emotion prediction and control, exploring speech style spaces, and emotion transfer. The goal was to create a system that could control the emotion of text-to-speech in a natural way.
Technical Explanation
EmoSphere-TTS uses a spherical emotion representation to model emotional content and enable continuous control over the emotional expression of generated speech. This is in contrast to prior work that has typically relied on discrete emotion categories or one-dimensional emotion intensity scales.
The system consists of several key components:
- Emotion Encoder: A neural network that takes text as input and outputs a 3D spherical emotion vector, representing the emotional content.
- Acoustic Model: A neural network that generates the acoustic features of the speech (e.g., mel-spectrograms) conditioned on the input text and emotion vector.
- Vocoder: A neural network that converts the acoustic features into the final waveform audio.
The researchers trained these models using VEcL-TTS, a framework for voice identity and emotional style control. They also introduced novel techniques like emotion-aware adversarial training to improve the model's ability to generate speech with the desired emotional characteristics.
Experiments showed that EmoSphere-TTS could generate speech with a wide range of emotional styles and intensities, outperforming prior emotional TTS systems in terms of naturalness and emotional expressiveness.
Critical Analysis
The EmoSphere-TTS system represents a significant advancement in emotional text-to-speech, providing much finer-grained control over the emotional delivery compared to prior approaches. The use of a spherical emotion representation is a clever and effective way to model the continuous, multidimensional nature of emotional expression.
That said, the paper does acknowledge some limitations and areas for future work. For example, the system was trained and evaluated on a limited set of emotional styles, and its performance may not generalize as well to rarer or more complex emotional states. Additionally, the researchers note that further improvements in areas like speech prosody and multimodal emotion modeling could enhance the system's overall realism and expressiveness.
It would also be interesting to see how EmoSphere-TTS performs in real-world applications, where factors like speaker identity, dialog context, and user preferences may introduce additional challenges. Careful user studies and field testing would be valuable to fully assess the system's capabilities and potential impact.
Overall, EmoSphere-TTS represents an important step forward in emotional TTS, with the potential to enable more engaging and natural-sounding voice interactions in a wide range of applications. As the field of text-to-speech continues to evolve, innovations like this will be crucial for creating AI systems that can communicate in a more human-like and empathetic manner.
Conclusion
The EmoSphere-TTS system introduces a novel approach to emotional text-to-speech, using a 3D spherical emotion representation to enable fine-grained control over the emotional style and intensity of generated speech. This represents a significant advance over prior work, which has typically relied on more limited, discrete emotion categories or one-dimensional intensity scales.
By allowing for smooth, continuous adjustment of emotional expression, EmoSphere-TTS has the potential to create more natural and engaging voice interactions in a wide range of applications, from virtual assistants to audiobook narration to video game dialog. As AI-powered speech synthesis continues to mature, innovations like this will be essential for developing systems that can communicate in a more human-like and emotionally intelligent way.
While the paper acknowledges some limitations and areas for future research, the core ideas and techniques presented in EmoSphere-TTS represent an important contribution to the field of emotional text-to-speech. As the technology continues to evolve, it will be exciting to see how researchers build upon these foundations to create even more expressive and versatile voice interfaces.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
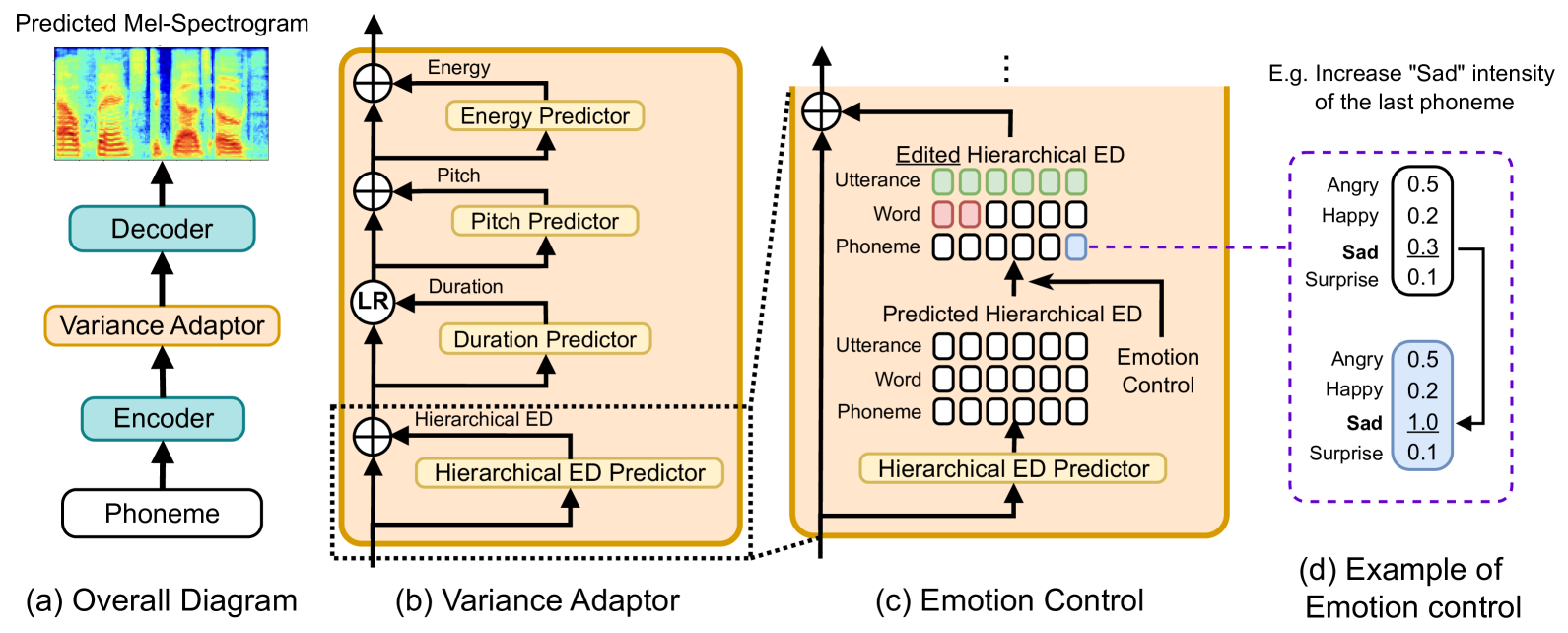
Hierarchical Emotion Prediction and Control in Text-to-Speech Synthesis
Sho Inoue, Kun Zhou, Shuai Wang, Haizhou Li
0
0
It remains a challenge to effectively control the emotion rendering in text-to-speech (TTS) synthesis. Prior studies have primarily focused on learning a global prosodic representation at the utterance level, which strongly correlates with linguistic prosody. Our goal is to construct a hierarchical emotion distribution (ED) that effectively encapsulates intensity variations of emotions at various levels of granularity, encompassing phonemes, words, and utterances. During TTS training, the hierarchical ED is extracted from the ground-truth audio and guides the predictor to establish a connection between emotional and linguistic prosody. At run-time inference, the TTS model generates emotional speech and, at the same time, provides quantitative control of emotion over the speech constituents. Both objective and subjective evaluations validate the effectiveness of the proposed framework in terms of emotion prediction and control.
5/16/2024
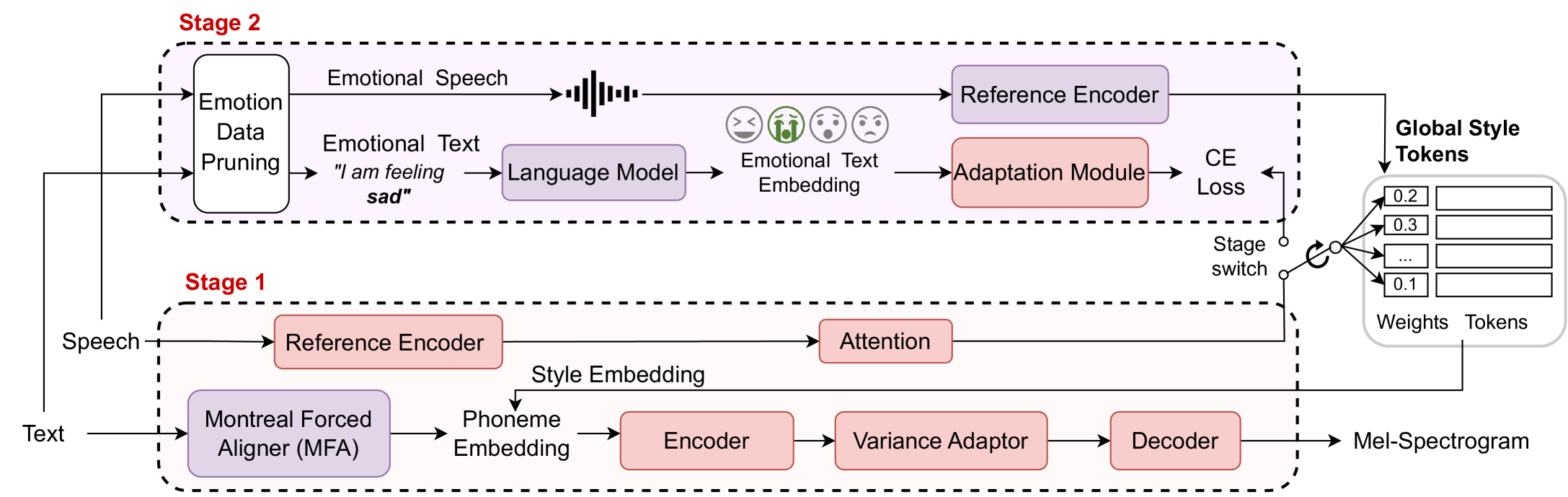
Exploring speech style spaces with language models: Emotional TTS without emotion labels
Shreeram Suresh Chandra, Zongyang Du, Berrak Sisman
0
0
Many frameworks for emotional text-to-speech (E-TTS) rely on human-annotated emotion labels that are often inaccurate and difficult to obtain. Learning emotional prosody implicitly presents a tough challenge due to the subjective nature of emotions. In this study, we propose a novel approach that leverages text awareness to acquire emotional styles without the need for explicit emotion labels or text prompts. We present TEMOTTS, a two-stage framework for E-TTS that is trained without emotion labels and is capable of inference without auxiliary inputs. Our proposed method performs knowledge transfer between the linguistic space learned by BERT and the emotional style space constructed by global style tokens. Our experimental results demonstrate the effectiveness of our proposed framework, showcasing improvements in emotional accuracy and naturalness. This is one of the first studies to leverage the emotional correlation between spoken content and expressive delivery for emotional TTS.
5/21/2024

New!Daisy-TTS: Simulating Wider Spectrum of Emotions via Prosody Embedding Decomposition
Rendi Chevi, Alham Fikri Aji
0
0
We often verbally express emotions in a multifaceted manner, they may vary in their intensities and may be expressed not just as a single but as a mixture of emotions. This wide spectrum of emotions is well-studied in the structural model of emotions, which represents variety of emotions as derivative products of primary emotions with varying degrees of intensity. In this paper, we propose an emotional text-to-speech design to simulate a wider spectrum of emotions grounded on the structural model. Our proposed design, Daisy-TTS, incorporates a prosody encoder to learn emotionally-separable prosody embedding as a proxy for emotion. This emotion representation allows the model to simulate: (1) Primary emotions, as learned from the training samples, (2) Secondary emotions, as a mixture of primary emotions, (3) Intensity-level, by scaling the emotion embedding, and (4) Emotions polarity, by negating the emotion embedding. Through a series of perceptual evaluations, Daisy-TTS demonstrated overall higher emotional speech naturalness and emotion perceiveability compared to the baseline.
6/28/2024

RSET: Remapping-based Sorting Method for Emotion Transfer Speech Synthesis
Haoxiang Shi, Jianzong Wang, Xulong Zhang, Ning Cheng, Jun Yu, Jing Xiao
0
0
Although current Text-To-Speech (TTS) models are able to generate high-quality speech samples, there are still challenges in developing emotion intensity controllable TTS. Most existing TTS models achieve emotion intensity control by extracting intensity information from reference speeches. Unfortunately, limited by the lack of modeling for intra-class emotion intensity and the model's information decoupling capability, the generated speech cannot achieve fine-grained emotion intensity control and suffers from information leakage issues. In this paper, we propose an emotion transfer TTS model, which defines a remapping-based sorting method to model intra-class relative intensity information, combined with Mutual Information (MI) to decouple speaker and emotion information, and synthesizes expressive speeches with perceptible intensity differences. Experiments show that our model achieves fine-grained emotion control while preserving speaker information.
5/28/2024