Hierarchical Emotion Prediction and Control in Text-to-Speech Synthesis
2405.09171
0
0
Abstract
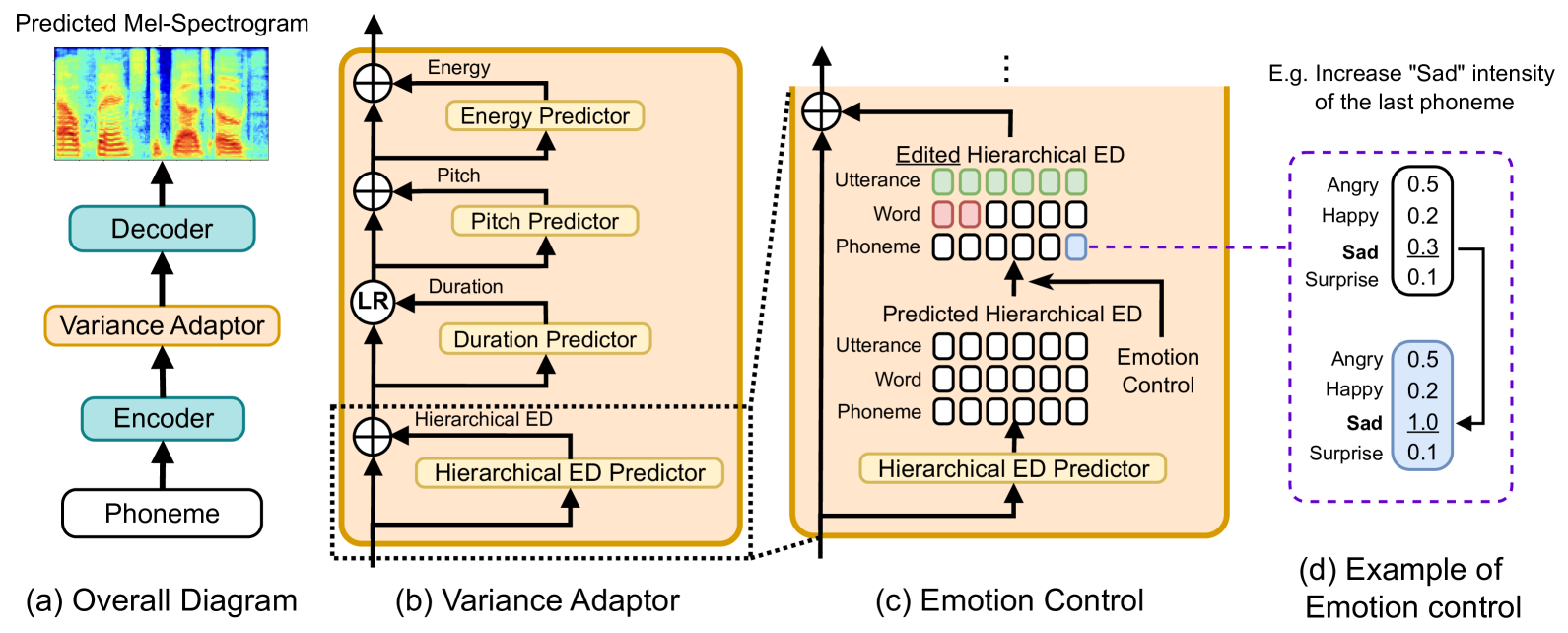
It remains a challenge to effectively control the emotion rendering in text-to-speech (TTS) synthesis. Prior studies have primarily focused on learning a global prosodic representation at the utterance level, which strongly correlates with linguistic prosody. Our goal is to construct a hierarchical emotion distribution (ED) that effectively encapsulates intensity variations of emotions at various levels of granularity, encompassing phonemes, words, and utterances. During TTS training, the hierarchical ED is extracted from the ground-truth audio and guides the predictor to establish a connection between emotional and linguistic prosody. At run-time inference, the TTS model generates emotional speech and, at the same time, provides quantitative control of emotion over the speech constituents. Both objective and subjective evaluations validate the effectiveness of the proposed framework in terms of emotion prediction and control.
Create account to get full access
Overview
- This research paper explores a hierarchical approach to predicting and controlling emotion in text-to-speech (TTS) synthesis.
- The proposed method aims to capture both global and local emotional characteristics in speech, allowing for more expressive and natural-sounding synthetic voices.
- The researchers investigate the use of multiple emotion-related features, including linguistic, acoustic, and visual cues, to enhance the emotional expressiveness of TTS.
Plain English Explanation
The paper focuses on improving the emotional expressiveness of text-to-speech (TTS) systems, which are used to convert written text into spoken speech. Currently, many TTS systems struggle to convey the appropriate emotional tone and nuance, resulting in synthetic voices that can sound flat or unnatural.
To address this, the researchers developed a hierarchical approach that predicts and controls the emotional characteristics of the speech output. The key idea is to capture both the overall emotional sentiment (e.g., happy, sad, angry) as well as the more granular emotional details (e.g., the specific vocal inflections and prosody that convey emotion).
By taking into account a range of emotional cues, including linguistic, acoustic, and visual information, the researchers aim to create TTS systems that can generate more expressive and natural-sounding speech. This could have important applications in areas like voice assistants, audiobook narration, and emotional dialogue systems.
Technical Explanation
The researchers propose a hierarchical model for predicting and controlling emotion in TTS synthesis. The model consists of two main components:
-
Global Emotion Prediction: This component aims to capture the overall emotional sentiment of the input text, classifying it into broad emotion categories (e.g., happy, sad, angry).
-
Local Emotion Control: This component focuses on generating the specific vocal characteristics (e.g., prosody, pitch, timing) that convey the desired emotional nuance, based on the global emotion prediction and other linguistic and acoustic features.
The researchers leverage a range of input features to drive this hierarchical emotion prediction and control, including:
- Linguistic features: Word-level and sentence-level cues, such as sentiment, emotion keywords, and syntax.
- Acoustic features: Acoustic characteristics of the speech, such as pitch, energy, and timing.
- Visual features: Facial expressions and body language, which can provide additional emotional context.
By combining these multimodal cues, the model can more effectively capture the complex interplay between language, acoustics, and emotion that is crucial for generating expressive and natural-sounding TTS.
The researchers evaluate their approach on benchmark datasets for emotional speech synthesis, demonstrating improvements in both objective and subjective measures of emotional expressiveness compared to baseline TTS systems. This suggests that the hierarchical emotion prediction and control framework can be a valuable tool for enhancing the emotional capabilities of TTS technologies.
Critical Analysis
The researchers acknowledge several limitations and areas for future work in their paper. For example, they note that the current model may struggle to capture more nuanced or context-dependent emotional expressions, and that further refinements to the feature extraction and modeling approaches could be beneficial.
Additionally, the researchers highlight the need for larger and more diverse datasets of emotional speech to train and evaluate these types of models. The available datasets can be relatively limited in their coverage of different speakers, emotions, and speaking styles, which may constrain the generalizability of the findings.
Another potential issue is the challenge of maintaining a balance between emotional expressiveness and intelligibility in TTS systems. Overly exaggerated emotional prosody, for instance, could potentially impair the clarity and understandability of the speech output, which is a critical requirement for many TTS applications.
Despite these limitations, the hierarchical emotion prediction and control framework presented in this paper represents an important step forward in enhancing the emotional capabilities of TTS systems. By providing a more granular and nuanced approach to modeling and generating emotional speech, the researchers have laid the groundwork for further advancements in this area.
Conclusion
This research paper introduces a hierarchical approach to predicting and controlling emotion in text-to-speech (TTS) synthesis. By leveraging a range of linguistic, acoustic, and visual features, the proposed model aims to capture both global emotional sentiment and local emotional nuance, resulting in more expressive and natural-sounding synthetic speech.
The findings suggest that this hierarchical framework can lead to significant improvements in the emotional expressiveness of TTS systems, with potential applications in voice assistants, audiobook narration, and emotional dialogue systems. As the field of TTS continues to evolve, this work represents an important contribution to the ongoing efforts to imbue synthetic voices with more human-like emotional intelligence and storytelling capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
Deok-Hyeon Cho, Hyung-Seok Oh, Seung-Bin Kim, Sang-Hoon Lee, Seong-Whan Lee
0
0
Despite rapid advances in the field of emotional text-to-speech (TTS), recent studies primarily focus on mimicking the average style of a particular emotion. As a result, the ability to manipulate speech emotion remains constrained to several predefined labels, compromising the ability to reflect the nuanced variations of emotion. In this paper, we propose EmoSphere-TTS, which synthesizes expressive emotional speech by using a spherical emotion vector to control the emotional style and intensity of the synthetic speech. Without any human annotation, we use the arousal, valence, and dominance pseudo-labels to model the complex nature of emotion via a Cartesian-spherical transformation. Furthermore, we propose a dual conditional adversarial network to improve the quality of generated speech by reflecting the multi-aspect characteristics. The experimental results demonstrate the model ability to control emotional style and intensity with high-quality expressive speech.
6/13/2024
Controlling Emotion in Text-to-Speech with Natural Language Prompts
Thomas Bott, Florian Lux, Ngoc Thang Vu
0
0
In recent years, prompting has quickly become one of the standard ways of steering the outputs of generative machine learning models, due to its intuitive use of natural language. In this work, we propose a system conditioned on embeddings derived from an emotionally rich text that serves as prompt. Thereby, a joint representation of speaker and prompt embeddings is integrated at several points within a transformer-based architecture. Our approach is trained on merged emotional speech and text datasets and varies prompts in each training iteration to increase the generalization capabilities of the model. Objective and subjective evaluation results demonstrate the ability of the conditioned synthesis system to accurately transfer the emotions present in a prompt to speech. At the same time, precise tractability of speaker identities as well as overall high speech quality and intelligibility are maintained.
6/13/2024

Daisy-TTS: Simulating Wider Spectrum of Emotions via Prosody Embedding Decomposition
Rendi Chevi, Alham Fikri Aji
0
0
We often verbally express emotions in a multifaceted manner, they may vary in their intensities and may be expressed not just as a single but as a mixture of emotions. This wide spectrum of emotions is well-studied in the structural model of emotions, which represents variety of emotions as derivative products of primary emotions with varying degrees of intensity. In this paper, we propose an emotional text-to-speech design to simulate a wider spectrum of emotions grounded on the structural model. Our proposed design, Daisy-TTS, incorporates a prosody encoder to learn emotionally-separable prosody embedding as a proxy for emotion. This emotion representation allows the model to simulate: (1) Primary emotions, as learned from the training samples, (2) Secondary emotions, as a mixture of primary emotions, (3) Intensity-level, by scaling the emotion embedding, and (4) Emotions polarity, by negating the emotion embedding. Through a series of perceptual evaluations, Daisy-TTS demonstrated overall higher emotional speech naturalness and emotion perceiveability compared to the baseline.
6/28/2024

RSET: Remapping-based Sorting Method for Emotion Transfer Speech Synthesis
Haoxiang Shi, Jianzong Wang, Xulong Zhang, Ning Cheng, Jun Yu, Jing Xiao
0
0
Although current Text-To-Speech (TTS) models are able to generate high-quality speech samples, there are still challenges in developing emotion intensity controllable TTS. Most existing TTS models achieve emotion intensity control by extracting intensity information from reference speeches. Unfortunately, limited by the lack of modeling for intra-class emotion intensity and the model's information decoupling capability, the generated speech cannot achieve fine-grained emotion intensity control and suffers from information leakage issues. In this paper, we propose an emotion transfer TTS model, which defines a remapping-based sorting method to model intra-class relative intensity information, combined with Mutual Information (MI) to decouple speaker and emotion information, and synthesizes expressive speeches with perceptible intensity differences. Experiments show that our model achieves fine-grained emotion control while preserving speaker information.
5/28/2024