DALLMi: Domain Adaption for LLM-based Multi-label Classifier

0
Sign in to get full access
Overview
• This paper presents a domain adaptation method called DALLMi (Domain Adaptation for LLM-based Multi-label Classifier) that aims to improve the performance of large language models (LLMs) on multi-label classification tasks in new domains.
• The key ideas are to leverage the general knowledge learned by pre-trained LLMs and adapt them to specific domains using a semi-supervised approach.
• The approach involves fine-tuning the LLM on a small amount of labeled data from the target domain and using self-supervised techniques to leverage unlabeled data to further adapt the model.
Plain English Explanation
<a href="https://aimodels.fyi/papers/arxiv/large-language-models-expansion-spoken-language-understanding">Large language models</a> like GPT-3 have shown impressive performance on a variety of tasks, but their performance can degrade when applied to new domains that differ from their original training data. DALLMi is a method that aims to address this by adapting the LLM to a new domain in a semi-supervised way.
The key idea is to start with a pre-trained LLM that has learned general knowledge, and then fine-tune it on a small amount of labeled data from the target domain. This helps the model adapt its understanding to the specifics of the new domain. Additionally, the researchers leverage <a href="https://aimodels.fyi/papers/arxiv/two-stage-framework-self-supervised-distillation-cross">self-supervised learning</a> techniques to use unlabeled data from the target domain to further improve the model's performance, without requiring additional labeled data.
By combining these approaches, DALLMi is able to take advantage of the broad knowledge in the pre-trained LLM while also adapting it to the specifics of the new domain, leading to improved performance on multi-label classification tasks.
Technical Explanation
The paper proposes a domain adaptation method called DALLMi (Domain Adaptation for LLM-based Multi-label Classifier) that aims to improve the performance of large language models (LLMs) on multi-label classification tasks in new domains.
The key elements of the approach are:
-
Fine-tuning on labeled target domain data: The researchers start with a pre-trained LLM and fine-tune it on a small amount of labeled data from the target domain. This helps the model adapt its understanding to the specifics of the new domain.
-
Self-supervised learning on unlabeled target domain data: In addition to the labeled data, the researchers leverage <a href="https://aimodels.fyi/papers/arxiv/two-stage-framework-self-supervised-distillation-cross">self-supervised learning</a> techniques to use unlabeled data from the target domain to further improve the model's performance. This allows the model to learn from the unlabeled data without requiring additional labeled data.
-
Multi-label classification: The researchers apply the adapted LLM to a multi-label classification task, where the model needs to predict multiple labels for each input.
The researchers evaluate their approach on several benchmark datasets and show that DALLMi outperforms other domain adaptation methods for multi-label classification tasks.
Critical Analysis
The paper presents a promising approach for adapting large language models to new domains, but there are a few potential limitations and areas for further research:
-
Generalization to other tasks: While the paper focuses on multi-label classification, it would be interesting to see how well the DALLMi approach generalizes to other types of tasks, such as <a href="https://aimodels.fyi/papers/arxiv/simplifying-multimodality-unimodal-approach-to-multimodal-challenges">multimodal tasks</a> or <a href="https://aimodels.fyi/papers/arxiv/chipnemo-domain-adapted-llms-chip-design">domain-specific applications</a> like chip design.
-
Data efficiency: The paper relies on a small amount of labeled data from the target domain, which may not always be available. Exploring ways to further reduce the amount of labeled data required, perhaps through <a href="https://aimodels.fyi/papers/arxiv/data-augmentation-based-dialectal-adaptation-llms">data augmentation techniques</a>, could make the approach more practical in real-world scenarios.
-
Interpretability and explainability: As with many deep learning models, it can be challenging to understand the internal workings of the adapted LLM and the reasons for its performance improvements. Investigating ways to make the model more interpretable and explainable could be a valuable direction for future research.
Conclusion
The DALLMi approach presented in this paper demonstrates a promising way to adapt large language models to new domains for multi-label classification tasks. By leveraging the general knowledge learned by pre-trained LLMs and combining it with semi-supervised adaptation techniques, the method can improve performance in target domains without requiring a large amount of labeled data.
The insights from this research could have important implications for making LLMs more robust and applicable in a wider range of real-world scenarios, ultimately expanding the reach and impact of these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DALLMi: Domain Adaption for LLM-based Multi-label Classifier
Miruna Bec{t}ianu, Abele Mu{a}lan, Marco Aldinucci, Robert Birke, Lydia Chen
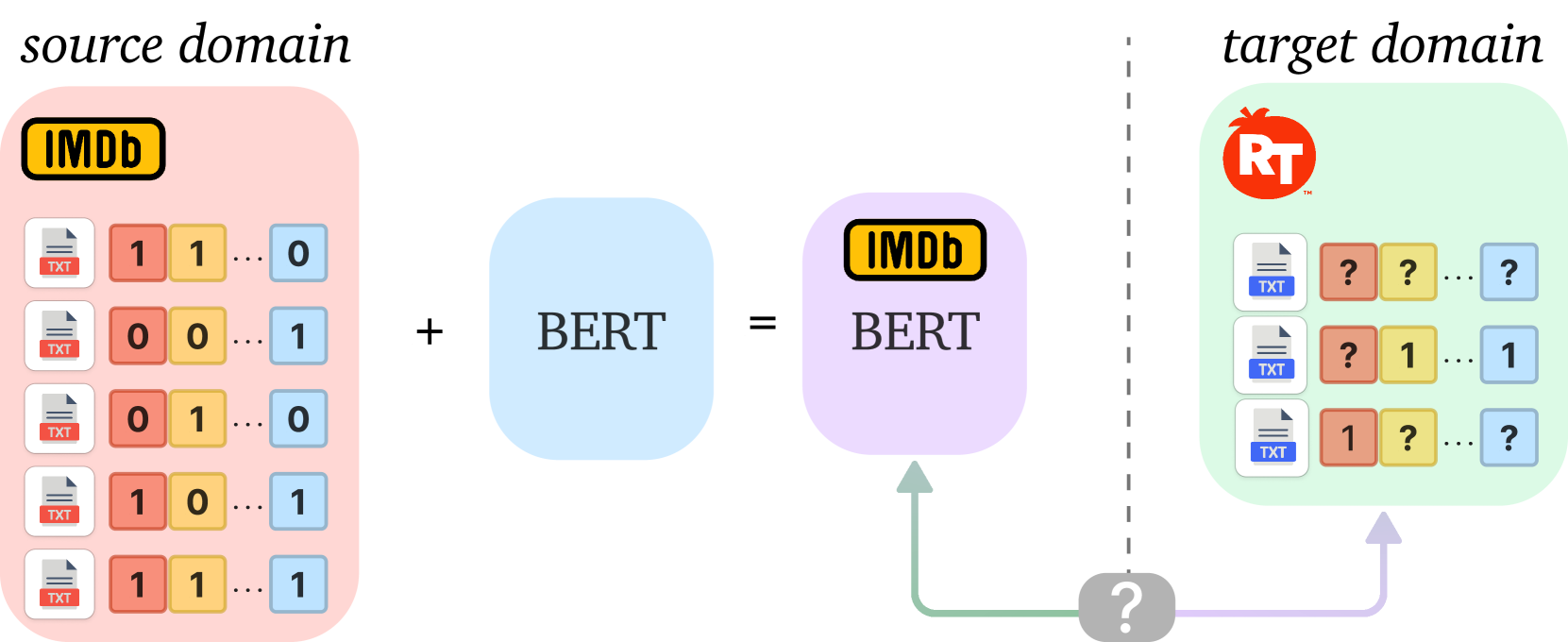
Large language models (LLMs) increasingly serve as the backbone for classifying text associated with distinct domains and simultaneously several labels (classes). When encountering domain shifts, e.g., classifier of movie reviews from IMDb to Rotten Tomatoes, adapting such an LLM-based multi-label classifier is challenging due to incomplete label sets at the target domain and daunting training overhead. The existing domain adaptation methods address either image multi-label classifiers or text binary classifiers. In this paper, we design DALLMi, Domain Adaptation Large Language Model interpolator, a first-of-its-kind semi-supervised domain adaptation method for text data models based on LLMs, specifically BERT. The core of DALLMi is the novel variation loss and MixUp regularization, which jointly leverage the limited positively labeled and large quantity of unlabeled text and, importantly, their interpolation from the BERT word embeddings. DALLMi also introduces a label-balanced sampling strategy to overcome the imbalance between labeled and unlabeled data. We evaluate DALLMi against the partial-supervised and unsupervised approach on three datasets under different scenarios of label availability for the target domain. Our results show that DALLMi achieves higher mAP than unsupervised and partially-supervised approaches by 19.9% and 52.2%, respectively.
Read more5/6/2024
💬
0
AdaptEval: Evaluating Large Language Models on Domain Adaptation for Text Summarization
Anum Afzal, Ribin Chalumattu, Florian Matthes, Laura Mascarell
Despite the advances in the abstractive summarization task using Large Language Models (LLM), there is a lack of research that asses their abilities to easily adapt to different domains. We evaluate the domain adaptation abilities of a wide range of LLMs on the summarization task across various domains in both fine-tuning and in-context learning settings. We also present AdaptEval, the first domain adaptation evaluation suite. AdaptEval includes a domain benchmark and a set of metrics to facilitate the analysis of domain adaptation. Our results demonstrate that LLMs exhibit comparable performance in the in-context learning setting, regardless of their parameter scale.
Read more7/23/2024

0
DALDA: Data Augmentation Leveraging Diffusion Model and LLM with Adaptive Guidance Scaling
Kyuheon Jung, Yongdeuk Seo, Seongwoo Cho, Jaeyoung Kim, Hyun-seok Min, Sungchul Choi
In this paper, we present an effective data augmentation framework leveraging the Large Language Model (LLM) and Diffusion Model (DM) to tackle the challenges inherent in data-scarce scenarios. Recently, DMs have opened up the possibility of generating synthetic images to complement a few training images. However, increasing the diversity of synthetic images also raises the risk of generating samples outside the target distribution. Our approach addresses this issue by embedding novel semantic information into text prompts via LLM and utilizing real images as visual prompts, thus generating semantically rich images. To ensure that the generated images remain within the target distribution, we dynamically adjust the guidance weight based on each image's CLIPScore to control the diversity. Experimental results show that our method produces synthetic images with enhanced diversity while maintaining adherence to the target distribution. Consequently, our approach proves to be more efficient in the few-shot setting on several benchmarks. Our code is available at https://github.com/kkyuhun94/dalda .
Read more9/26/2024
💬
0
New!LML: Language Model Learning a Dataset for Data-Augmented Prediction
Praneeth Vadlapati
This paper introduces a new approach to using Large Language Models (LLMs) for classification tasks, which are typically handled using Machine Learning (ML) models. Unlike ML models that rely heavily on data cleaning and feature engineering, this method streamlines the process using LLMs. This paper proposes a new concept called Language Model Learning (LML) powered by a new method called Data-Augmented Prediction (DAP). The classification is performed by LLMs using a method similar to humans manually exploring and understanding the data and deciding classifications using data as a reference. Training data is summarized and evaluated to determine the features that lead to the classification of each label the most. In the process of DAP, the system uses the data summary to automatically create a query, which is used to retrieve relevant rows from the dataset. A classification is generated by the LLM using data summary and relevant rows, ensuring satisfactory accuracy even with complex data. Usage of data summary and similar data in DAP ensures context-aware decision-making. The proposed method uses the words Act as an Explainable Machine Learning Model in the prompt to enhance the interpretability of the predictions by allowing users to review the logic behind each prediction. In some test cases, the system scored an accuracy above 90%, proving the effectiveness of the system and its potential to outperform conventional ML models in various scenarios. The code is available at https://github.com/Pro-GenAI/LML-DAP
Read more9/30/2024