Dance Any Beat: Blending Beats with Visuals in Dance Video Generation
2405.09266
0
0
Abstract
The task of generating dance from music is crucial, yet current methods, which mainly produce joint sequences, lead to outputs that lack intuitiveness and complicate data collection due to the necessity for precise joint annotations. We introduce a Dance Any Beat Diffusion model, namely DabFusion, that employs music as a conditional input to directly create dance videos from still images, utilizing conditional image-to-video generation principles. This approach pioneers the use of music as a conditioning factor in image-to-video synthesis. Our method unfolds in two stages: training an auto-encoder to predict latent optical flow between reference and driving frames, eliminating the need for joint annotation, and training a U-Net-based diffusion model to produce these latent optical flows guided by music rhythm encoded by CLAP. Although capable of producing high-quality dance videos, the baseline model struggles with rhythm alignment. We enhance the model by adding beat information, improving synchronization. We introduce a 2D motion-music alignment score (2D-MM Align) for quantitative assessment. Evaluated on the AIST++ dataset, our enhanced model shows marked improvements in 2D-MM Align score and established metrics. Video results can be found on our project page: https://DabFusion.github.io.
Create account to get full access
Overview
- This paper presents a novel approach to generating dance videos that seamlessly blend the visuals with the beat of the music.
- The system, called "Dance Any Beat," is able to create dance videos that follow the rhythm and tempo of any input audio track, even if it is different from the original dance motion.
- The researchers leverage deep learning models to disentangle the dance motion from the audio, allowing them to recombine the visual elements with a new soundtrack.
Plain English Explanation
The Dance Any Beat system allows you to take a dance video and pair it with any piece of music you want. Even if the new music has a different tempo or rhythm than the original dance, the system can adjust the visuals to match the new beat.
This is accomplished by training deep learning models to separate the dance movements from the original audio track. Once the dance is decoupled from the music, the researchers can then recombine the visual elements with a completely new soundtrack.
The result is a dance video that looks natural and synchronized, even though the music has been changed. This could be useful for things like music videos, dance tutorials, or video game animations, where you want to be able to freely mix and match different dances and songs.
The key insight is that by disentangling the dance from the audio, the system has the flexibility to blend them back together in new ways. This allows for a lot of creative possibilities when generating dance videos.
Technical Explanation
The Dance Any Beat system works by first training a deep learning model to extract the dance motion from a video, represented as a sequence of 3D skeletal poses. Another model is trained to predict the audio features, such as the beat and tempo, from the dance motion.
During inference, the system takes a new audio track as input and uses the pre-trained models to generate a sequence of 3D poses that match the rhythm and tempo of the new audio. These poses are then rendered as a new dance video that is synchronized to the input music.
The researchers experiment with different neural network architectures and training strategies to improve the quality and realism of the generated dance videos. They also explore ways to allow users to have more fine-grained control over the dance style and expressiveness.
Overall, the Dance Any Beat system demonstrates a novel approach to generating dance videos that can adapt to any input music, opening up new creative possibilities in areas like video production and interactive entertainment.
Critical Analysis
The Dance Any Beat paper presents an impressive technical achievement, but there are a few potential limitations and areas for further research:
-
The system is currently limited to generating dance motions based on 3D skeletal poses, which may not capture the full complexity and expressiveness of human dance. Incorporating more detailed body and facial animations could improve the realism of the generated videos.
-
The training process is still quite complex, requiring separate models for extracting dance motions and predicting audio features. Developing a more integrated end-to-end approach could simplify the system and improve its overall performance.
-
The paper does not explore the potential ethical implications of this technology, such as the ability to create "deepfake" dance videos or the risk of perpetuating stereotypes through the generated dance styles. Further research is needed to address these concerns.
Despite these caveats, the Dance Any Beat system represents an important step forward in the field of dance video generation, paving the way for more sophisticated and creative applications in the future.
Conclusion
The Dance Any Beat paper presents a novel approach to generating dance videos that can seamlessly blend the visuals with the beat of any input audio track. By leveraging deep learning models to disentangle the dance motion from the original audio, the system can recombine the visual elements with a new soundtrack, resulting in dance videos that are synchronized to the new music.
This technology could have a wide range of applications, from music videos and dance tutorials to video game animations and interactive entertainment. By providing a flexible and creative tool for blending dance and music, the Dance Any Beat system opens up new possibilities for artistic expression and entertainment.
While the paper highlights some areas for further research and refinement, the core technical achievements and the potential impact of this work make it an exciting development in the field of dance video generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
May the Dance be with You: Dance Generation Framework for Non-Humanoids
Hyemin Ahn
0
0
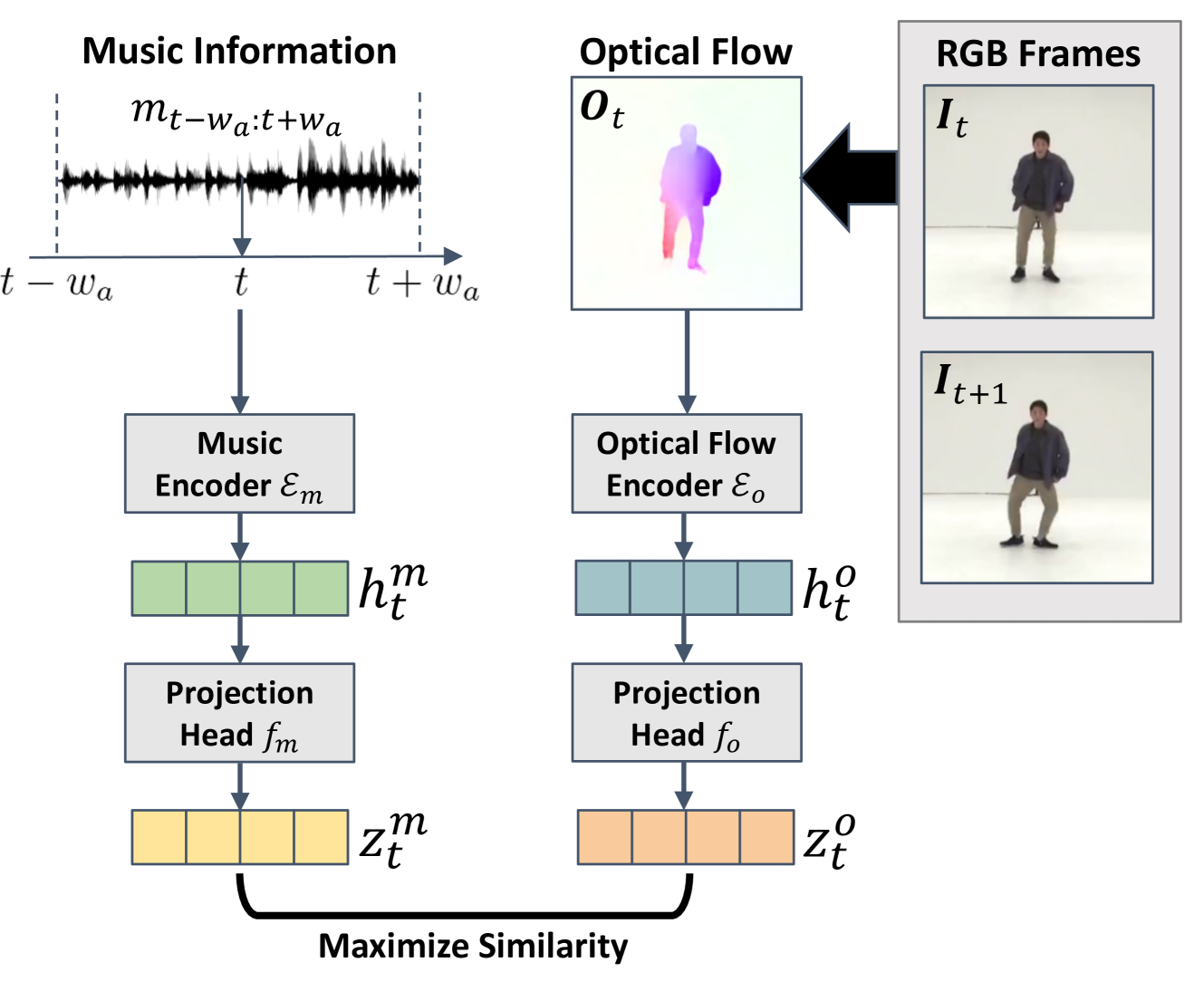
We hypothesize dance as a motion that forms a visual rhythm from music, where the visual rhythm can be perceived from an optical flow. If an agent can recognize the relationship between visual rhythm and music, it will be able to dance by generating a motion to create a visual rhythm that matches the music. Based on this, we propose a framework for any kind of non-humanoid agents to learn how to dance from human videos. Our framework works in two processes: (1) training a reward model which perceives the relationship between optical flow (visual rhythm) and music from human dance videos, (2) training the non-humanoid dancer based on that reward model, and reinforcement learning. Our reward model consists of two feature encoders for optical flow and music. They are trained based on contrastive learning which makes the higher similarity between concurrent optical flow and music features. With this reward model, the agent learns dancing by getting a higher reward when its action creates an optical flow whose feature has a higher similarity with the given music feature. Experiment results show that generated dance motion can align with the music beat properly, and user study result indicates that our framework is more preferred by humans compared to the baselines. To the best of our knowledge, our work of non-humanoid agents which learn dance from human videos is unprecedented. An example video can be found at https://youtu.be/dOUPvo-O3QY.
5/31/2024

Bidirectional Autoregressive Diffusion Model for Dance Generation
Canyu Zhang, Youbao Tang, Ning Zhang, Ruei-Sung Lin, Mei Han, Jing Xiao, Song Wang
0
0
Dance serves as a powerful medium for expressing human emotions, but the lifelike generation of dance is still a considerable challenge. Recently, diffusion models have showcased remarkable generative abilities across various domains. They hold promise for human motion generation due to their adaptable many-to-many nature. Nonetheless, current diffusion-based motion generation models often create entire motion sequences directly and unidirectionally, lacking focus on the motion with local and bidirectional enhancement. When choreographing high-quality dance movements, people need to take into account not only the musical context but also the nearby music-aligned dance motions. To authentically capture human behavior, we propose a Bidirectional Autoregressive Diffusion Model (BADM) for music-to-dance generation, where a bidirectional encoder is built to enforce that the generated dance is harmonious in both the forward and backward directions. To make the generated dance motion smoother, a local information decoder is built for local motion enhancement. The proposed framework is able to generate new motions based on the input conditions and nearby motions, which foresees individual motion slices iteratively and consolidates all predictions. To further refine the synchronicity between the generated dance and the beat, the beat information is incorporated as an input to generate better music-aligned dance movements. Experimental results demonstrate that the proposed model achieves state-of-the-art performance compared to existing unidirectional approaches on the prominent benchmark for music-to-dance generation.
6/26/2024

MIDGET: Music Conditioned 3D Dance Generation
Jinwu Wang, Wei Mao, Miaomiao Liu
0
0
In this paper, we introduce a MusIc conditioned 3D Dance GEneraTion model, named MIDGET based on Dance motion Vector Quantised Variational AutoEncoder (VQ-VAE) model and Motion Generative Pre-Training (GPT) model to generate vibrant and highquality dances that match the music rhythm. To tackle challenges in the field, we introduce three new components: 1) a pre-trained memory codebook based on the Motion VQ-VAE model to store different human pose codes, 2) employing Motion GPT model to generate pose codes with music and motion Encoders, 3) a simple framework for music feature extraction. We compare with existing state-of-the-art models and perform ablation experiments on AIST++, the largest publicly available music-dance dataset. Experiments demonstrate that our proposed framework achieves state-of-the-art performance on motion quality and its alignment with the music.
4/19/2024

MeLFusion: Synthesizing Music from Image and Language Cues using Diffusion Models
Sanjoy Chowdhury, Sayan Nag, K J Joseph, Balaji Vasan Srinivasan, Dinesh Manocha
0
0
Music is a universal language that can communicate emotions and feelings. It forms an essential part of the whole spectrum of creative media, ranging from movies to social media posts. Machine learning models that can synthesize music are predominantly conditioned on textual descriptions of it. Inspired by how musicians compose music not just from a movie script, but also through visualizations, we propose MeLFusion, a model that can effectively use cues from a textual description and the corresponding image to synthesize music. MeLFusion is a text-to-music diffusion model with a novel visual synapse, which effectively infuses the semantics from the visual modality into the generated music. To facilitate research in this area, we introduce a new dataset MeLBench, and propose a new evaluation metric IMSM. Our exhaustive experimental evaluation suggests that adding visual information to the music synthesis pipeline significantly improves the quality of generated music, measured both objectively and subjectively, with a relative gain of up to 67.98% on the FAD score. We hope that our work will gather attention to this pragmatic, yet relatively under-explored research area.
6/10/2024