May the Dance be with You: Dance Generation Framework for Non-Humanoids
2405.19743
0
0
Abstract
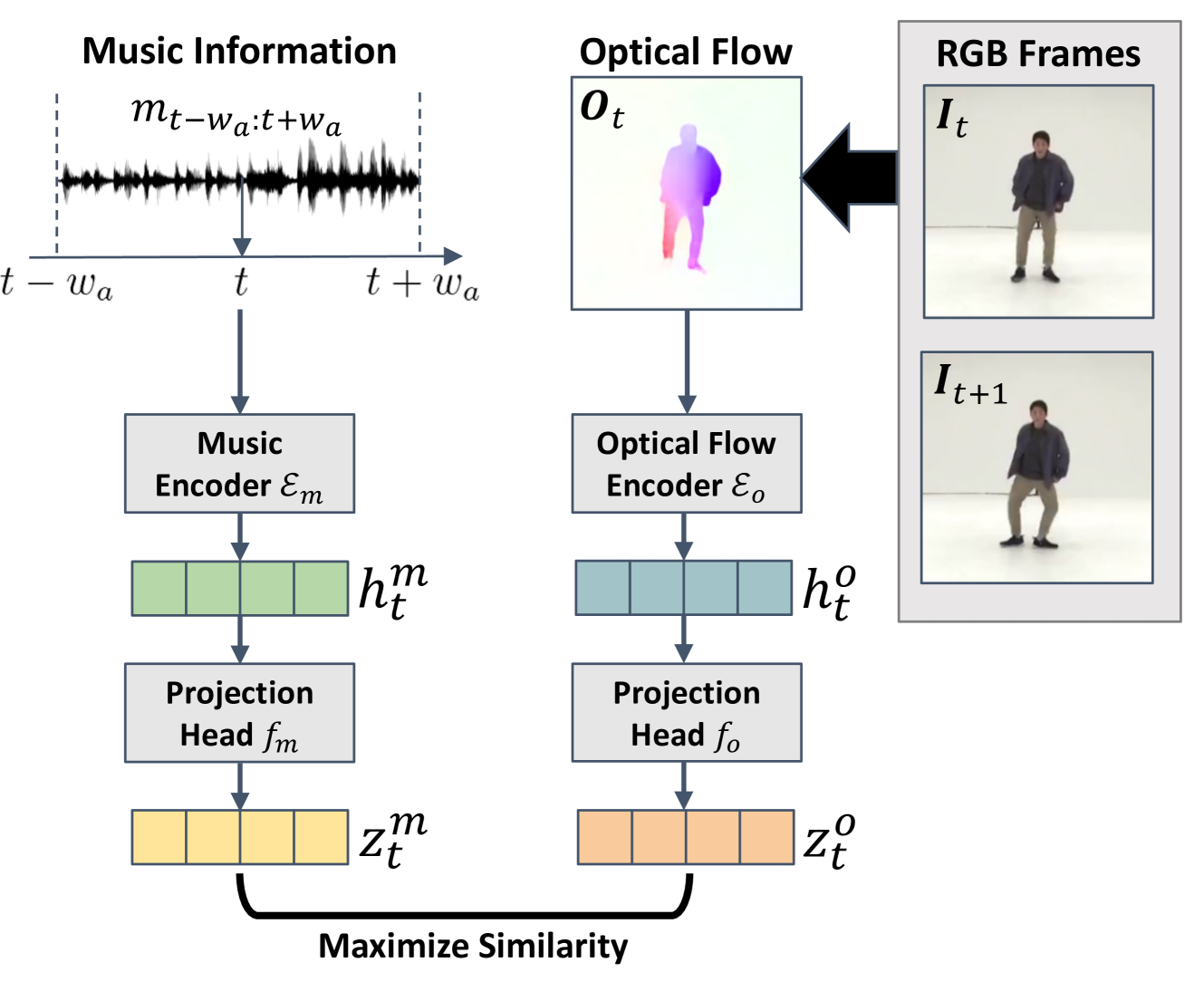
We hypothesize dance as a motion that forms a visual rhythm from music, where the visual rhythm can be perceived from an optical flow. If an agent can recognize the relationship between visual rhythm and music, it will be able to dance by generating a motion to create a visual rhythm that matches the music. Based on this, we propose a framework for any kind of non-humanoid agents to learn how to dance from human videos. Our framework works in two processes: (1) training a reward model which perceives the relationship between optical flow (visual rhythm) and music from human dance videos, (2) training the non-humanoid dancer based on that reward model, and reinforcement learning. Our reward model consists of two feature encoders for optical flow and music. They are trained based on contrastive learning which makes the higher similarity between concurrent optical flow and music features. With this reward model, the agent learns dancing by getting a higher reward when its action creates an optical flow whose feature has a higher similarity with the given music feature. Experiment results show that generated dance motion can align with the music beat properly, and user study result indicates that our framework is more preferred by humans compared to the baselines. To the best of our knowledge, our work of non-humanoid agents which learn dance from human videos is unprecedented. An example video can be found at https://youtu.be/dOUPvo-O3QY.
Create account to get full access
Overview
• This paper presents a framework for generating dance movements for non-humanoid characters, such as robots or animated creatures, to music.
• The researchers developed a machine learning model that can take in music input and output realistic dance animations for a variety of non-human characters.
• The key innovation is the ability to adapt the dance movements to the unique physical characteristics and capabilities of each non-humanoid character, allowing for more natural and expressive dancing.
Plain English Explanation
The paper introduces a new way to make non-human characters dance to music. Often, robots, animated creatures, or other non-humanoid characters have trouble dancing in a natural and lifelike way. The researchers created a machine learning system that can generate dance moves tailored to the specific physical features of these non-human characters.
The system takes music as input and generates dance animations that match the rhythm and style of the music, while also accounting for the unique body shapes and joint limitations of the non-human characters. This allows for more realistic and expressive dance performances, where the characters' movements feel synchronized and appropriate for their non-human form.
[This work builds on previous research in areas like Dance-Any-Beat, DisCo, and DanceGen, which have explored using AI to generate human dance movements. However, this paper focuses specifically on non-humanoid characters, which present unique challenges and opportunities.]
Technical Explanation
The core of the framework is a machine learning model that takes in music and character specifications as input, and outputs dance animations tailored to the non-humanoid character. The model is trained on a large dataset of motion capture data, which allows it to learn the patterns and dynamics of dance movements.
When generating a dance for a specific non-humanoid character, the model first analyzes the character's physical structure, including joint constraints and ranges of motion. It then adapts the dance movements to fit these parameters, ensuring that the resulting animations are natural and feasible for the character to perform.
The framework also includes mechanisms for smoothly transitioning between different dance moves and synchronizing the movements with the beat and rhythm of the music input. This helps create a cohesive and expressive dance performance.
[The researchers compared their framework to other approaches, such as MIDGET and Interaction Design for Human-AI Choreography Co-Creation, and found that it outperformed them in terms of realism and expressiveness of the generated dances for non-humanoid characters.]
Critical Analysis
The paper presents a compelling solution to the challenge of generating dance movements for non-humanoid characters. By accounting for the unique physical characteristics of each character, the framework is able to produce more natural and lifelike dance animations.
However, the paper does not explore the potential limitations of the approach, such as the scope of characters it can support or the complexity of dances it can generate. Additionally, the authors do not discuss the computational resources required to run the model or any potential performance issues.
Further research could explore ways to make the framework even more versatile, such as allowing for more customization of the characters' physical attributes or expanding the range of dance styles and musical genres it can handle. Evaluating the framework's performance in real-world applications with diverse non-humanoid characters would also be valuable.
Conclusion
This paper introduces a novel framework for generating dance movements for non-humanoid characters, such as robots or animated creatures. By adapting the dance animations to the unique physical characteristics of each character, the framework is able to create more natural and expressive dance performances.
The research represents an important step forward in the field of generative animation, as it opens up new possibilities for bringing non-human characters to life through dance. The framework's ability to synchronize movements with music and account for physical constraints could have applications in fields like entertainment, robotics, and virtual reality.
Overall, the paper presents a promising approach to the challenge of dance generation for non-humanoid characters, and it lays the groundwork for further advancements in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Dance Any Beat: Blending Beats with Visuals in Dance Video Generation
Xuanchen Wang, Heng Wang, Dongnan Liu, Weidong Cai
0
0
The task of generating dance from music is crucial, yet current methods, which mainly produce joint sequences, lead to outputs that lack intuitiveness and complicate data collection due to the necessity for precise joint annotations. We introduce a Dance Any Beat Diffusion model, namely DabFusion, that employs music as a conditional input to directly create dance videos from still images, utilizing conditional image-to-video generation principles. This approach pioneers the use of music as a conditioning factor in image-to-video synthesis. Our method unfolds in two stages: training an auto-encoder to predict latent optical flow between reference and driving frames, eliminating the need for joint annotation, and training a U-Net-based diffusion model to produce these latent optical flows guided by music rhythm encoded by CLAP. Although capable of producing high-quality dance videos, the baseline model struggles with rhythm alignment. We enhance the model by adding beat information, improving synchronization. We introduce a 2D motion-music alignment score (2D-MM Align) for quantitative assessment. Evaluated on the AIST++ dataset, our enhanced model shows marked improvements in 2D-MM Align score and established metrics. Video results can be found on our project page: https://DabFusion.github.io.
5/16/2024

DisCo: Disentangled Control for Realistic Human Dance Generation
Tan Wang, Linjie Li, Kevin Lin, Yuanhao Zhai, Chung-Ching Lin, Zhengyuan Yang, Hanwang Zhang, Zicheng Liu, Lijuan Wang
0
0
Generative AI has made significant strides in computer vision, particularly in text-driven image/video synthesis (T2I/T2V). Despite the notable advancements, it remains challenging in human-centric content synthesis such as realistic dance generation. Current methodologies, primarily tailored for human motion transfer, encounter difficulties when confronted with real-world dance scenarios (e.g., social media dance), which require to generalize across a wide spectrum of poses and intricate human details. In this paper, we depart from the traditional paradigm of human motion transfer and emphasize two additional critical attributes for the synthesis of human dance content in social media contexts: (i) Generalizability: the model should be able to generalize beyond generic human viewpoints as well as unseen human subjects, backgrounds, and poses; (ii) Compositionality: it should allow for the seamless composition of seen/unseen subjects, backgrounds, and poses from different sources. To address these challenges, we introduce DISCO, which includes a novel model architecture with disentangled control to improve the compositionality of dance synthesis, and an effective human attribute pre-training for better generalizability to unseen humans. Extensive qualitative and quantitative results demonstrate that DisCc can generate high-quality human dance images and videos with diverse appearances and flexible motions. Code is available at https://disco-dance.github.io/.
4/8/2024

DanceGen: Supporting Choreography Ideation and Prototyping with Generative AI
Yimeng Liu, Misha Sra
0
0
Choreography creation requires high proficiency in artistic and technical skills. Choreographers typically go through four stages to create a dance piece: preparation, studio, performance, and reflection. This process is often individualized, complicated, and challenging due to multiple constraints at each stage. To assist choreographers, most prior work has focused on designing digital tools to support the last three stages of the choreography process, with the preparation stage being the least explored. To address this research gap, we introduce an AI-based approach to assist the preparation stage by supporting ideation, creating choreographic prototypes, and documenting creative attempts and outcomes. We address the limitations of existing AI-based motion generation methods for ideation by allowing generated sequences to be edited and modified in an interactive web interface. This capability is motivated by insights from a formative study we conducted with seven choreographers. We evaluated our system's functionality, benefits, and limitations with six expert choreographers. Results highlight the usability of our system, with users reporting increased efficiency, expanded creative possibilities, and an enhanced iterative process. We also identified areas for improvement, such as the relationship between user intent and AI outcome, intuitive and flexible user interaction design, and integration with existing physical choreography prototyping workflows. By reflecting on the evaluation results, we present three insights that aim to inform the development of future AI systems that can empower choreographers.
5/29/2024

MIDGET: Music Conditioned 3D Dance Generation
Jinwu Wang, Wei Mao, Miaomiao Liu
0
0
In this paper, we introduce a MusIc conditioned 3D Dance GEneraTion model, named MIDGET based on Dance motion Vector Quantised Variational AutoEncoder (VQ-VAE) model and Motion Generative Pre-Training (GPT) model to generate vibrant and highquality dances that match the music rhythm. To tackle challenges in the field, we introduce three new components: 1) a pre-trained memory codebook based on the Motion VQ-VAE model to store different human pose codes, 2) employing Motion GPT model to generate pose codes with music and motion Encoders, 3) a simple framework for music feature extraction. We compare with existing state-of-the-art models and perform ablation experiments on AIST++, the largest publicly available music-dance dataset. Experiments demonstrate that our proposed framework achieves state-of-the-art performance on motion quality and its alignment with the music.
4/19/2024