MeLFusion: Synthesizing Music from Image and Language Cues using Diffusion Models
2406.04673
0
0

Abstract
Music is a universal language that can communicate emotions and feelings. It forms an essential part of the whole spectrum of creative media, ranging from movies to social media posts. Machine learning models that can synthesize music are predominantly conditioned on textual descriptions of it. Inspired by how musicians compose music not just from a movie script, but also through visualizations, we propose MeLFusion, a model that can effectively use cues from a textual description and the corresponding image to synthesize music. MeLFusion is a text-to-music diffusion model with a novel visual synapse, which effectively infuses the semantics from the visual modality into the generated music. To facilitate research in this area, we introduce a new dataset MeLBench, and propose a new evaluation metric IMSM. Our exhaustive experimental evaluation suggests that adding visual information to the music synthesis pipeline significantly improves the quality of generated music, measured both objectively and subjectively, with a relative gain of up to 67.98% on the FAD score. We hope that our work will gather attention to this pragmatic, yet relatively under-explored research area.
Create account to get full access
Overview
- This paper presents a novel approach called MeLFusion for synthesizing music from image and language cues using diffusion models.
- The method combines visual and textual information to generate realistic and expressive musical compositions.
- The researchers explore different architectural designs and training techniques to enable this cross-modal music generation.
Plain English Explanation
The researchers have developed a new way to create music by using both images and text as input. Their system, called MeLFusion, takes visual and language cues and uses a special kind of machine learning model called a diffusion model to generate original musical compositions.
Diffusion models work by gradually adding "noise" to an image or other data, then learning how to reverse that process to create new, realistic-looking content. The researchers have adapted this technique to the domain of music, allowing their system to generate songs based on the information provided through images and text.
This approach is exciting because it opens up new possibilities for creative music generation. Rather than relying solely on traditional musical knowledge or input from a human composer, MeLFusion can leverage a wider range of cues to inspire the creation of novel, expressive music. This could be useful for applications like video game soundtracks, film scoring, or even as a tool for human musicians to explore new musical ideas.
The researchers explore different architectural designs and training techniques to make this cross-modal music generation work effectively. By combining visual and textual information, they aim to produce musical outputs that are more coherent, meaningful, and aligned with the original prompts.
Technical Explanation
The MeLFusion system uses a text-to-music model and an image-to-music model that are trained on large datasets of text, images, and music. These models learn the relationships between the different modalities, allowing them to generate music that is semantically and stylistically consistent with the input prompts.
The researchers experiment with different architectural designs and training techniques to improve the quality and coherence of the generated music. This includes using text-to-song models to ensure the lyrics and melody are well-aligned.
Through extensive evaluation, the researchers demonstrate that MeLFusion can generate music that is perceived as more expressive, creative, and meaningful compared to systems that rely on a single modality. The ability to combine visual and textual cues opens up new avenues for AI-assisted music composition and production.
Critical Analysis
The paper provides a comprehensive overview of the MeLFusion system and its capabilities, but it also acknowledges several limitations and areas for further research. For example, the researchers note that the current system is limited in its ability to capture the nuances of musical performance, such as expressive timing and dynamics. Additionally, the training data used may not be representative of the full diversity of musical styles and genres.
One potential issue that is not addressed in the paper is the potential for bias and lack of diversity in the generated music. Like many AI-generated creative outputs, there is a risk that MeLFusion could perpetuate existing biases in the training data or reflect the perspectives and preferences of the researchers and developers.
Further research could explore ways to address these limitations, such as incorporating more diverse training data, developing models that can better capture the expressive aspects of music, and implementing techniques to enhance the diversity and originality of the generated compositions.
Conclusion
The MeLFusion system represents a significant advancement in the field of cross-modal music generation, demonstrating the potential of combining visual and textual cues to inspire the creation of novel and expressive musical compositions. By leveraging diffusion models and other state-of-the-art techniques, the researchers have developed a system that can generate music that is more semantically and stylistically coherent with the input prompts.
While the paper highlights several promising applications for this technology, such as in video game soundtracks and film scoring, it also raises important questions about the ethical implications of AI-generated music and the need to address issues of bias and diversity. As the field of AI-assisted music creation continues to evolve, it will be crucial for researchers and developers to carefully consider these challenges and work to ensure that the technology is used in a responsible and inclusive manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MusicMagus: Zero-Shot Text-to-Music Editing via Diffusion Models
Yixiao Zhang, Yukara Ikemiya, Gus Xia, Naoki Murata, Marco A. Mart'inez-Ram'irez, Wei-Hsiang Liao, Yuki Mitsufuji, Simon Dixon
0
0
Recent advances in text-to-music generation models have opened new avenues in musical creativity. However, music generation usually involves iterative refinements, and how to edit the generated music remains a significant challenge. This paper introduces a novel approach to the editing of music generated by such models, enabling the modification of specific attributes, such as genre, mood and instrument, while maintaining other aspects unchanged. Our method transforms text editing to textit{latent space manipulation} while adding an extra constraint to enforce consistency. It seamlessly integrates with existing pretrained text-to-music diffusion models without requiring additional training. Experimental results demonstrate superior performance over both zero-shot and certain supervised baselines in style and timbre transfer evaluations. Additionally, we showcase the practical applicability of our approach in real-world music editing scenarios.
5/29/2024
💬
MusiLingo: Bridging Music and Text with Pre-trained Language Models for Music Captioning and Query Response
Zihao Deng, Yinghao Ma, Yudong Liu, Rongchen Guo, Ge Zhang, Wenhu Chen, Wenhao Huang, Emmanouil Benetos
0
0
Large Language Models (LLMs) have shown immense potential in multimodal applications, yet the convergence of textual and musical domains remains not well-explored. To address this gap, we present MusiLingo, a novel system for music caption generation and music-related query responses. MusiLingo employs a single projection layer to align music representations from the pre-trained frozen music audio model MERT with a frozen LLM, bridging the gap between music audio and textual contexts. We train it on an extensive music caption dataset and fine-tune it with instructional data. Due to the scarcity of high-quality music Q&A datasets, we created the MusicInstruct (MI) dataset from captions in the MusicCaps datasets, tailored for open-ended music inquiries. Empirical evaluations demonstrate its competitive performance in generating music captions and composing music-related Q&A pairs. Our introduced dataset enables notable advancements beyond previous ones.
4/3/2024
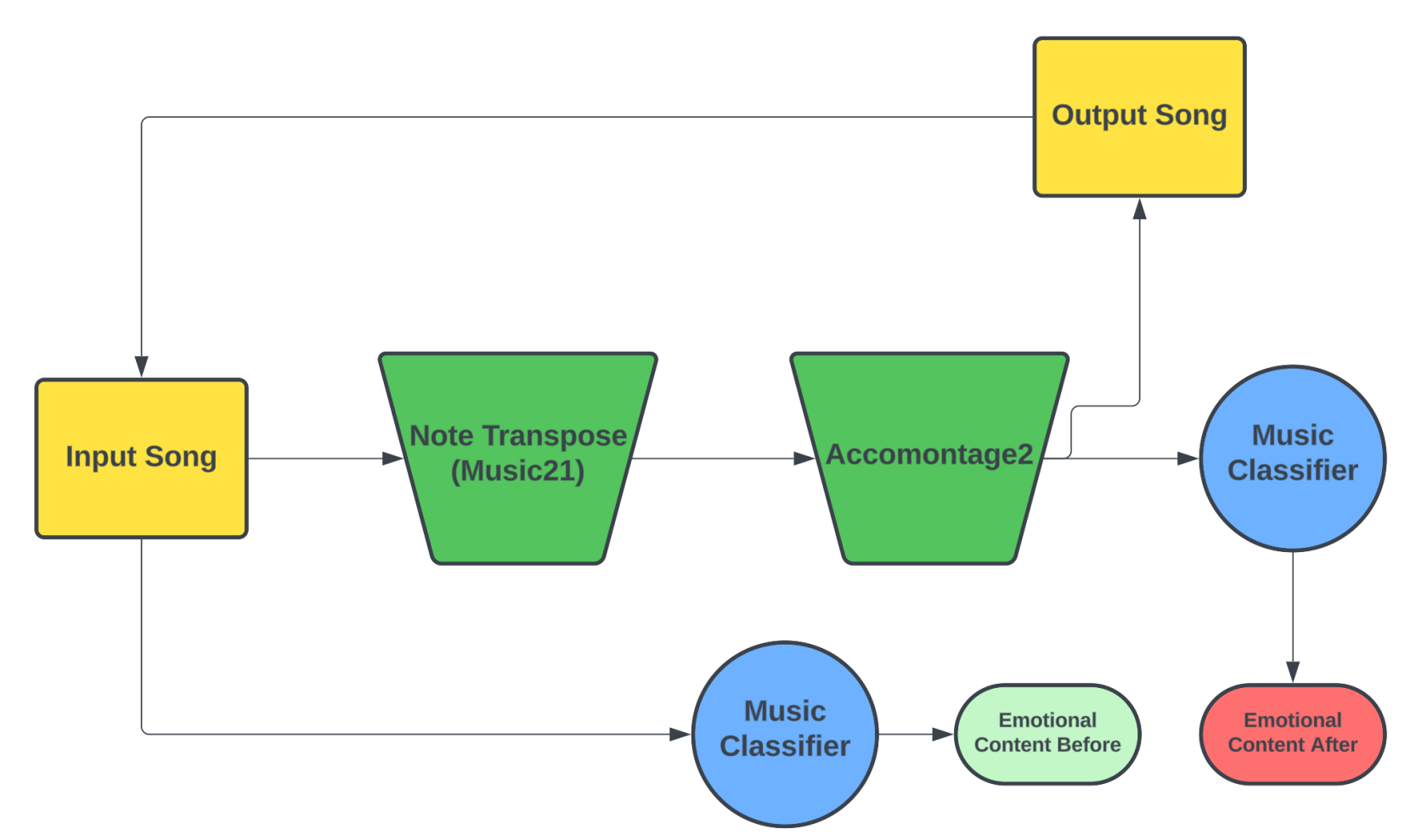
Emotion Manipulation Through Music -- A Deep Learning Interactive Visual Approach
Adel N. Abdalla, Jared Osborne, Razvan Andonie
0
0
Music evokes emotion in many people. We introduce a novel way to manipulate the emotional content of a song using AI tools. Our goal is to achieve the desired emotion while leaving the original melody as intact as possible. For this, we create an interactive pipeline capable of shifting an input song into a diametrically opposed emotion and visualize this result through Russel's Circumplex model. Our approach is a proof-of-concept for Semantic Manipulation of Music, a novel field aimed at modifying the emotional content of existing music. We design a deep learning model able to assess the accuracy of our modifications to key, SoundFont instrumentation, and other musical features. The accuracy of our model is in-line with the current state of the art techniques on the 4Q Emotion dataset. With further refinement, this research may contribute to on-demand custom music generation, the automated remixing of existing work, and music playlists tuned for emotional progression.
6/14/2024
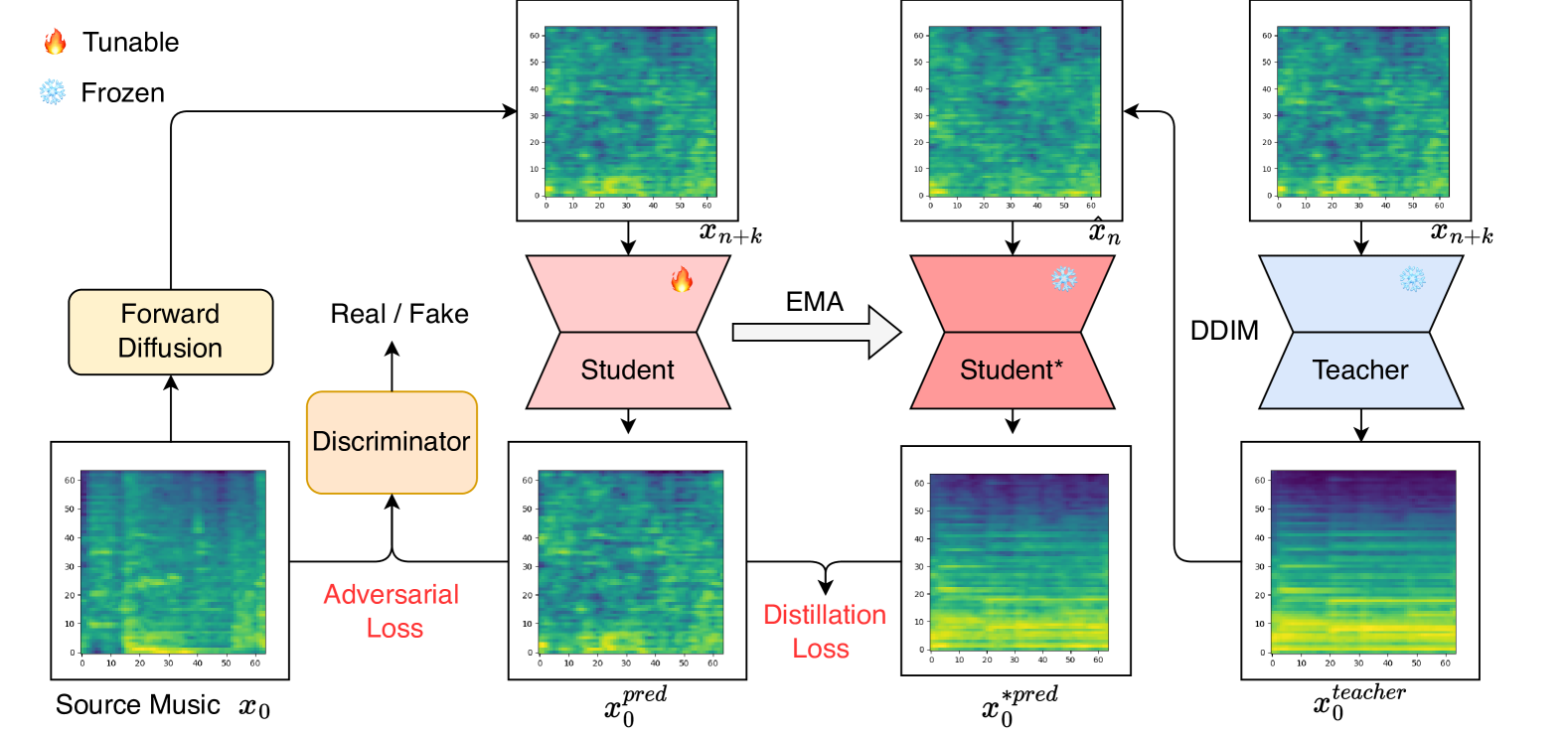
Music Consistency Models
Zhengcong Fei, Mingyuan Fan, Junshi Huang
0
0
Consistency models have exhibited remarkable capabilities in facilitating efficient image/video generation, enabling synthesis with minimal sampling steps. It has proven to be advantageous in mitigating the computational burdens associated with diffusion models. Nevertheless, the application of consistency models in music generation remains largely unexplored. To address this gap, we present Music Consistency Models (texttt{MusicCM}), which leverages the concept of consistency models to efficiently synthesize mel-spectrogram for music clips, maintaining high quality while minimizing the number of sampling steps. Building upon existing text-to-music diffusion models, the texttt{MusicCM} model incorporates consistency distillation and adversarial discriminator training. Moreover, we find it beneficial to generate extended coherent music by incorporating multiple diffusion processes with shared constraints. Experimental results reveal the effectiveness of our model in terms of computational efficiency, fidelity, and naturalness. Notable, texttt{MusicCM} achieves seamless music synthesis with a mere four sampling steps, e.g., only one second per minute of the music clip, showcasing the potential for real-time application.
4/23/2024