DaRec: A Disentangled Alignment Framework for Large Language Model and Recommender System

0

Sign in to get full access
Overview
- This paper proposes a framework called DaRec to align large language models (LLMs) with recommender systems.
- The key idea is to disentangle the representation of text and recommendations, allowing the LLM and recommender to be trained separately.
- The framework aims to improve the quality and interpretability of recommendations by leveraging the rich semantic knowledge in LLMs.
Plain English Explanation
The research paper introduces a new approach called DaRec to combine large language models (LLMs) and recommender systems. LLMs are powerful AI models that can understand and generate human-like text, while recommender systems suggest relevant items to users based on their preferences.
The main challenge is to effectively integrate these two important AI technologies. DaRec addresses this by disentangling the representation of text and recommendations. This means the LLM and recommender can be trained separately, rather than being tightly coupled.
The key insight is that the rich semantic knowledge captured by LLMs can be leveraged to improve the quality and interpretability of recommendations. For example, an LLM's understanding of language and concepts could help a recommender system make more relevant suggestions to users.
By separating the text and recommendation components, DaRec aims to get the best of both worlds - the powerful language understanding of LLMs and the personalized recommendation capabilities. This could lead to more accurate and explainable recommendations for users.
Technical Explanation
The paper proposes a framework called DaRec that disentangles the representation of text and recommendations in a large language model (LLM) and recommender system.
The core idea is to decouple the LLM and recommender, allowing them to be trained separately. This is achieved by introducing an alignment module that maps the text representations from the LLM to the recommendation representations.
Specifically, the LLM is used to encode input text into a semantic representation. This is then passed through the alignment module to produce a recommendation-specific representation. The recommender system can then use this aligned representation to make personalized suggestions.
The authors demonstrate the effectiveness of DaRec through experiments on several benchmark datasets. They show that DaRec can outperform tightly-coupled approaches in terms of recommendation quality and interpretability.
The disentangled architecture also enables flexibility, as the LLM and recommender can be updated independently. This could be useful in real-world scenarios where the text data or user preferences evolve over time.
Critical Analysis
The paper makes a compelling case for decoupling large language models and recommender systems through the DaRec framework. The key strength is the ability to leverage the rich semantic knowledge in LLMs to improve recommendation quality and interpretability.
However, the authors acknowledge some limitations and areas for future work. For example, the current alignment module may not fully capture all the nuances between text and recommendation representations. Exploring more sophisticated alignment techniques could further improve performance.
Additionally, the experiments are conducted on standard benchmark datasets, which may not fully reflect real-world challenges. Evaluating DaRec on large-scale, production-level recommendation systems would provide valuable insights into its practical applicability and scalability.
It would also be interesting to investigate how DaRec could be extended to handle dynamic user preferences and evolving content, as this is a common challenge in recommendation systems.
Conclusion
The DaRec framework presented in this paper offers a promising approach to aligning large language models and recommender systems. By disentangling the text and recommendation representations, it enables the two components to be trained and updated independently, while still allowing the LLM's semantic knowledge to enhance the recommender's performance.
This work contributes to the ongoing efforts to integrate powerful AI technologies like LLMs and recommender systems, which have significant potential to improve personalized content discovery and user experiences across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DaRec: A Disentangled Alignment Framework for Large Language Model and Recommender System
Xihong Yang, Heming Jing, Zixing Zhang, Jindong Wang, Huakang Niu, Shuaiqiang Wang, Yu Lu, Junfeng Wang, Dawei Yin, Xinwang Liu, En Zhu, Defu Lian, Erxue Min
Benefiting from the strong reasoning capabilities, Large language models (LLMs) have demonstrated remarkable performance in recommender systems. Various efforts have been made to distill knowledge from LLMs to enhance collaborative models, employing techniques like contrastive learning for representation alignment. In this work, we prove that directly aligning the representations of LLMs and collaborative models is sub-optimal for enhancing downstream recommendation tasks performance, based on the information theorem. Consequently, the challenge of effectively aligning semantic representations between collaborative models and LLMs remains unresolved. Inspired by this viewpoint, we propose a novel plug-and-play alignment framework for LLMs and collaborative models. Specifically, we first disentangle the latent representations of both LLMs and collaborative models into specific and shared components via projection layers and representation regularization. Subsequently, we perform both global and local structure alignment on the shared representations to facilitate knowledge transfer. Additionally, we theoretically prove that the specific and shared representations contain more pertinent and less irrelevant information, which can enhance the effectiveness of downstream recommendation tasks. Extensive experimental results on benchmark datasets demonstrate that our method is superior to existing state-of-the-art algorithms.
Read more8/16/2024
💬
0
RecExplainer: Aligning Large Language Models for Explaining Recommendation Models
Yuxuan Lei, Jianxun Lian, Jing Yao, Xu Huang, Defu Lian, Xing Xie
Recommender systems are widely used in online services, with embedding-based models being particularly popular due to their expressiveness in representing complex signals. However, these models often function as a black box, making them less transparent and reliable for both users and developers. Recently, large language models (LLMs) have demonstrated remarkable intelligence in understanding, reasoning, and instruction following. This paper presents the initial exploration of using LLMs as surrogate models to explaining black-box recommender models. The primary concept involves training LLMs to comprehend and emulate the behavior of target recommender models. By leveraging LLMs' own extensive world knowledge and multi-step reasoning abilities, these aligned LLMs can serve as advanced surrogates, capable of reasoning about observations. Moreover, employing natural language as an interface allows for the creation of customizable explanations that can be adapted to individual user preferences. To facilitate an effective alignment, we introduce three methods: behavior alignment, intention alignment, and hybrid alignment. Behavior alignment operates in the language space, representing user preferences and item information as text to mimic the target model's behavior; intention alignment works in the latent space of the recommendation model, using user and item representations to understand the model's behavior; hybrid alignment combines both language and latent spaces. Comprehensive experiments conducted on three public datasets show that our approach yields promising results in understanding and mimicking target models, producing high-quality, high-fidelity, and distinct explanations. Our code is available at https://github.com/microsoft/RecAI.
Read more6/26/2024
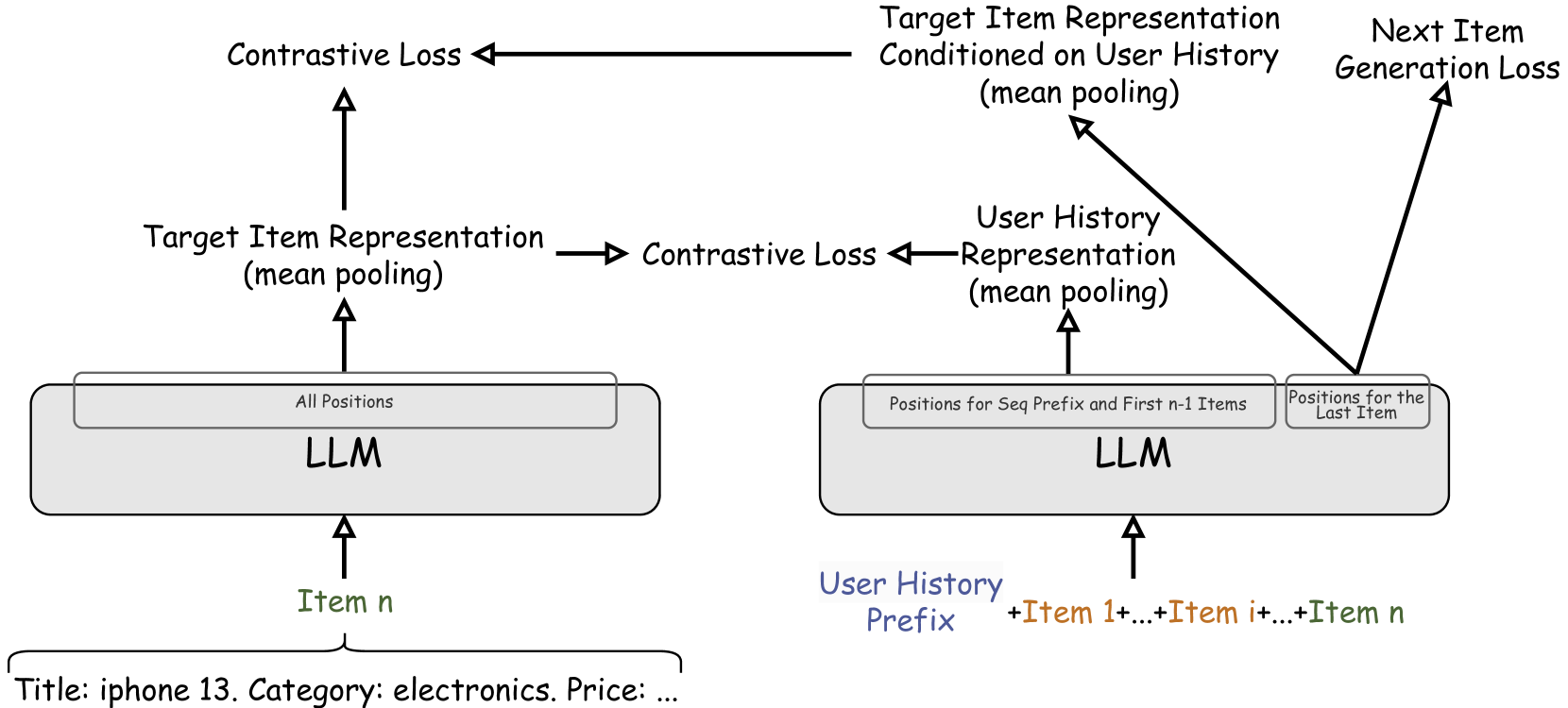
0
CALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
Yaoyiran Li, Xiang Zhai, Moustafa Alzantot, Keyi Yu, Ivan Vuli'c, Anna Korhonen, Mohamed Hammad
Traditional recommender systems such as matrix factorization methods have primarily focused on learning a shared dense embedding space to represent both items and user preferences. Subsequently, sequence models such as RNN, GRUs, and, recently, Transformers have emerged and excelled in the task of sequential recommendation. This task requires understanding the sequential structure present in users' historical interactions to predict the next item they may like. Building upon the success of Large Language Models (LLMs) in a variety of tasks, researchers have recently explored using LLMs that are pretrained on vast corpora of text for sequential recommendation. To use LLMs for sequential recommendation, both the history of user interactions and the model's prediction of the next item are expressed in text form. We propose CALRec, a two-stage LLM finetuning framework that finetunes a pretrained LLM in a two-tower fashion using a mixture of two contrastive losses and a language modeling loss: the LLM is first finetuned on a data mixture from multiple domains followed by another round of target domain finetuning. Our model significantly outperforms many state-of-the-art baselines (+37% in Recall@1 and +24% in NDCG@10) and our systematic ablation studies reveal that (i) both stages of finetuning are crucial, and, when combined, we achieve improved performance, and (ii) contrastive alignment is effective among the target domains explored in our experiments.
Read more8/27/2024
💬
0
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, Ji-Rong Wen
Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
Read more4/22/2024