Dark Experience for Incremental Keyword Spotting

0
Sign in to get full access
Overview
- The paper introduces a novel method called "Dark Experience" for incremental keyword spotting.
- Keyword spotting is a task in speech recognition where the goal is to detect the presence of specific words within an audio stream.
- The "Dark Experience" approach allows a model to continually learn new keywords without forgetting previously learned ones.
Plain English Explanation
The paper describes a new way to train keyword spotting models that can keep learning new words over time without forgetting the old ones. This is an important problem because in the real world, we often need to add new keywords to speech recognition systems as our needs change.
The key insight is to create "dark experience" samples by combining audio clips of different keywords. This forces the model to learn to distinguish between the individual keywords, rather than just memorizing each one. As new keywords are introduced, the model can continue learning them without losing its ability to detect the old ones.
This approach is similar to how humans learn - we don't just memorize a list of words, but rather learn to understand the relationships between them. By mimicking this learning process, the model becomes more robust and adaptable over time.
Technical Explanation
The paper proposes a "Dark Experience" training strategy for incremental keyword spotting. The core idea is to create synthetic training samples by combining audio clips of different keywords. This "dark experience" forces the model to learn to distinguish between the individual keywords, rather than just memorizing each one.
Specifically, the authors create these dark experience samples by randomly selecting audio clips of different keywords and overlaying them. The model is then trained to correctly identify all the keywords present in the combined clip.
This training strategy has several benefits:
-
Continual Learning: As new keywords are introduced, the model can continue learning them without forgetting the old ones. This is achieved by simply adding the new keywords to the pool of possible "dark" samples.
-
Robustness: By learning to disentangle the individual keywords in the dark experience samples, the model becomes more robust to real-world audio conditions, such as overlapping speech or background noise.
-
Efficiency: The dark experience samples can be generated on-the-fly, reducing the need for a large labeled dataset of individual keywords.
The authors evaluate their approach on several benchmark datasets and show that it outperforms traditional fine-tuning and rehearsal-based continual learning methods for keyword spotting.
Critical Analysis
The "Dark Experience" approach presented in this paper is a clever and innovative solution to the problem of incremental keyword spotting. By creating synthetic training samples that force the model to learn the relationships between keywords, the authors have found a way to enable continual learning without catastrophic forgetting.
One potential limitation of the method is that it may not be as effective for keywords that have very similar acoustic properties. In such cases, the model may still struggle to differentiate between them, even with the dark experience training. The paper does not address this issue in depth, and it would be interesting to see how the method performs on a more challenging dataset with highly confusable keywords.
Additionally, the authors do not provide much insight into the computational efficiency of their approach. While they claim it reduces the need for a large labeled dataset, the cost of generating the dark experience samples on-the-fly could offset this benefit. A more thorough analysis of the training time and memory requirements would help to better understand the practical implications of this method.
Overall, the "Dark Experience" approach is a promising contribution to the field of keyword spotting and continual learning. The authors have demonstrated the effectiveness of their method on several benchmark tasks, and the underlying principles could be applied to other domains where incremental learning is important.
Conclusion
The "Dark Experience" method presented in this paper offers a novel solution to the problem of incremental keyword spotting. By creating synthetic training samples that force the model to learn the relationships between keywords, the authors have developed a way to enable continual learning without forgetting previously learned information.
This approach has the potential to significantly improve the adaptability and robustness of speech recognition systems, allowing them to keep up with changing user needs and real-world audio conditions. While the method has some limitations, the underlying principles are compelling and could be applied to other domains where incremental learning is a challenge.
As the field of artificial intelligence continues to advance, techniques like "Dark Experience" will become increasingly important for building systems that can learn and evolve over time, rather than being limited to a fixed set of capabilities. The insights gained from this research could have far-reaching implications for the development of more versatile and user-friendly speech recognition technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dark Experience for Incremental Keyword Spotting
Tianyi Peng, Yang Xiao
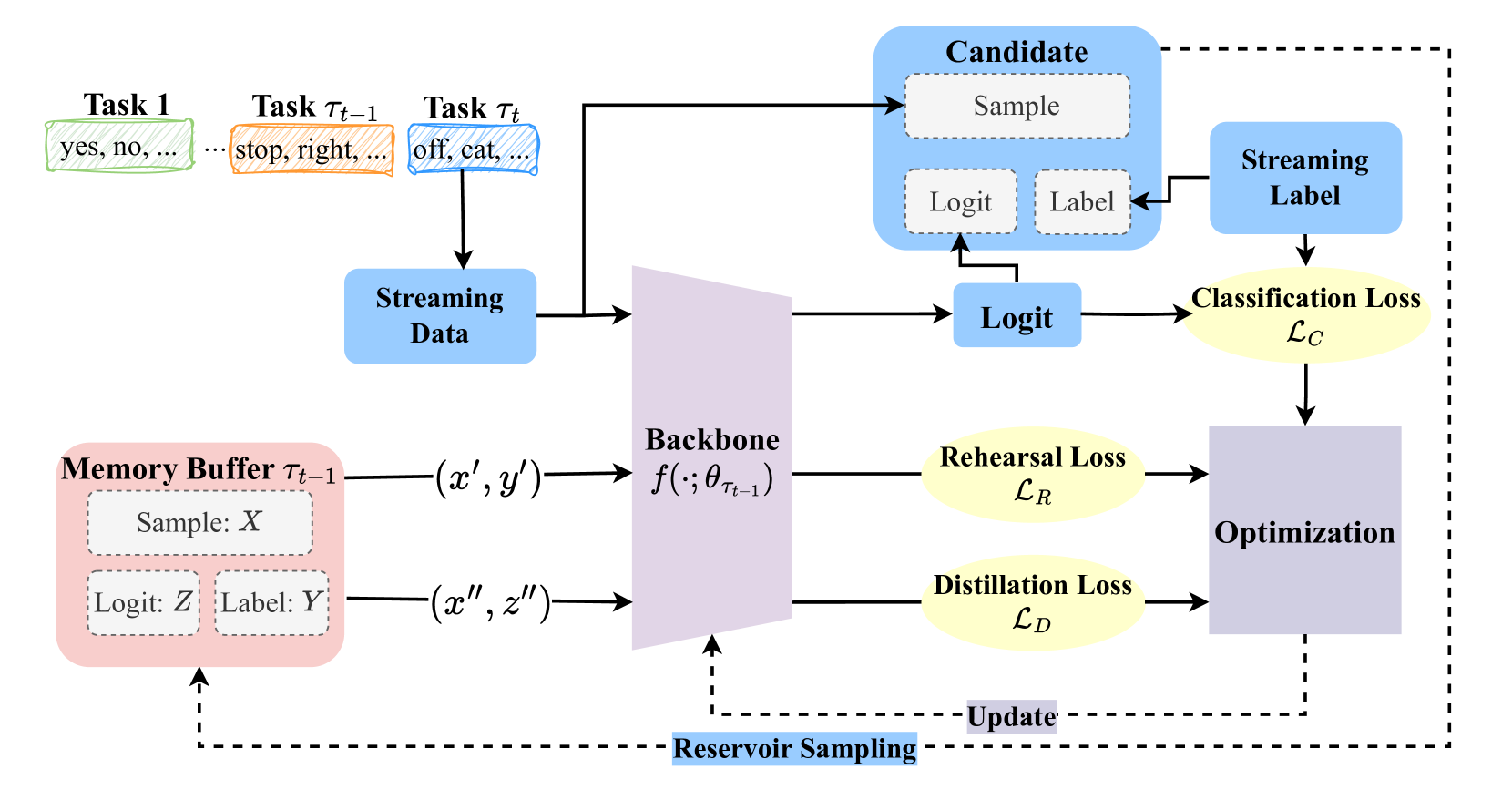
Spoken keyword spotting (KWS) is crucial for identifying keywords within audio inputs and is widely used in applications like Apple Siri and Google Home, particularly on edge devices. Current deep learning-based KWS systems, which are typically trained on a limited set of keywords, can suffer from performance degradation when encountering new domains, a challenge often addressed through few-shot fine-tuning. However, this adaptation frequently leads to catastrophic forgetting, where the model's performance on original data deteriorates. Progressive continual learning (CL) strategies have been proposed to overcome this, but they face limitations such as the need for task-ID information and increased storage, making them less practical for lightweight devices. To address these challenges, we introduce Dark Experience for Keyword Spotting (DE-KWS), a novel CL approach that leverages dark knowledge to distill past experiences throughout the training process. DE-KWS combines rehearsal and distillation, using both ground truth labels and logits stored in a memory buffer to maintain model performance across tasks. Evaluations on the Google Speech Command dataset show that DE-KWS outperforms existing CL baselines in average accuracy without increasing model size, offering an effective solution for resource-constrained edge devices. The scripts are available on GitHub for the future research.
Read more9/16/2024

0
Contrastive Augmentation: An Unsupervised Learning Approach for Keyword Spotting in Speech Technology
Weinan Dai, Yifeng Jiang, Yuanjing Liu, Jinkun Chen, Xin Sun, Jinglei Tao
This paper addresses the persistent challenge in Keyword Spotting (KWS), a fundamental component in speech technology, regarding the acquisition of substantial labeled data for training. Given the difficulty in obtaining large quantities of positive samples and the laborious process of collecting new target samples when the keyword changes, we introduce a novel approach combining unsupervised contrastive learning and a unique augmentation-based technique. Our method allows the neural network to train on unlabeled data sets, potentially improving performance in downstream tasks with limited labeled data sets. We also propose that similar high-level feature representations should be employed for speech utterances with the same keyword despite variations in speed or volume. To achieve this, we present a speech augmentation-based unsupervised learning method that utilizes the similarity between the bottleneck layer feature and the audio reconstructing information for auxiliary training. Furthermore, we propose a compressed convolutional architecture to address potential redundancy and non-informative information in KWS tasks, enabling the model to simultaneously learn local features and focus on long-term information. This method achieves strong performance on the Google Speech Commands V2 Dataset. Inspired by recent advancements in sign spotting and spoken term detection, our method underlines the potential of our contrastive learning approach in KWS and the advantages of Query-by-Example Spoken Term Detection strategies. The presented CAB-KWS provide new perspectives in the field of KWS, demonstrating effective ways to reduce data collection efforts and increase the system's robustness.
Read more9/4/2024
0
Disentangled Training with Adversarial Examples For Robust Small-footprint Keyword Spotting
Zhenyu Wang, Li Wan, Biqiao Zhang, Yiteng Huang, Shang-Wen Li, Ming Sun, Xin Lei, Zhaojun Yang
A keyword spotting (KWS) engine that is continuously running on device is exposed to various speech signals that are usually unseen before. It is a challenging problem to build a small-footprint and high-performing KWS model with robustness under different acoustic environments. In this paper, we explore how to effectively apply adversarial examples to improve KWS robustness. We propose datasource-aware disentangled learning with adversarial examples to reduce the mismatch between the original and adversarial data as well as the mismatch across original training datasources. The KWS model architecture is based on depth-wise separable convolution and a simple attention module. Experimental results demonstrate that the proposed learning strategy improves false reject rate by $40.31%$ at $1%$ false accept rate on the internal dataset, compared to the strongest baseline without using adversarial examples. Our best-performing system achieves $98.06%$ accuracy on the Google Speech Commands V1 dataset.
Read more8/27/2024

0
Sparse Binarization for Fast Keyword Spotting
Jonathan Svirsky, Uri Shaham, Ofir Lindenbaum
With the increasing prevalence of voice-activated devices and applications, keyword spotting (KWS) models enable users to interact with technology hands-free, enhancing convenience and accessibility in various contexts. Deploying KWS models on edge devices, such as smartphones and embedded systems, offers significant benefits for real-time applications, privacy, and bandwidth efficiency. However, these devices often possess limited computational power and memory. This necessitates optimizing neural network models for efficiency without significantly compromising their accuracy. To address these challenges, we propose a novel keyword-spotting model based on sparse input representation followed by a linear classifier. The model is four times faster than the previous state-of-the-art edge device-compatible model with better accuracy. We show that our method is also more robust in noisy environments while being fast. Our code is available at: https://github.com/jsvir/sparknet.
Read more6/12/2024